Esercizio - Pulire e preparare i dati
Prima di poter preparare un set di dati è necessario comprenderne il contenuto e la struttura. Nel lab precedente è stato importato un set di dati contenente informazioni relative agli arrivi puntuali per un'importante compagnia aerea statunitense. I dati includevano 26 colonne e migliaia di righe, con ogni riga che rappresenta un volo e contiene informazioni quali l'origine del volo, la destinazione e l'orario di partenza previsto. I dati sono anche stati caricati in un notebook Jupyter ed è stato usato un semplice script di Python per creare da essi un DataFrame Pandas.
Un DataFrame è una struttura dei dati con etichette bidimensionale. Le colonne in un DataFrame possono essere di diversi tipi, proprio come le colonne in un foglio di calcolo o in una tabella di database. È l'oggetto usato più comunemente in Pandas. In questo esercizio si esaminerà in modo più dettagliato il DataFrame e i dati al suo interno.
Tornare al notebook di Azure creato nella sezione precedente. Se il notebook è stato chiuso, è possibile accedere di nuovo al portale di Microsoft Azure Notebooks, aprire il notebook e usare Cell ->Run All (Cella > Esegui tutto) per eseguire di nuovo tutte le celle del notebook dopo averlo aperto.
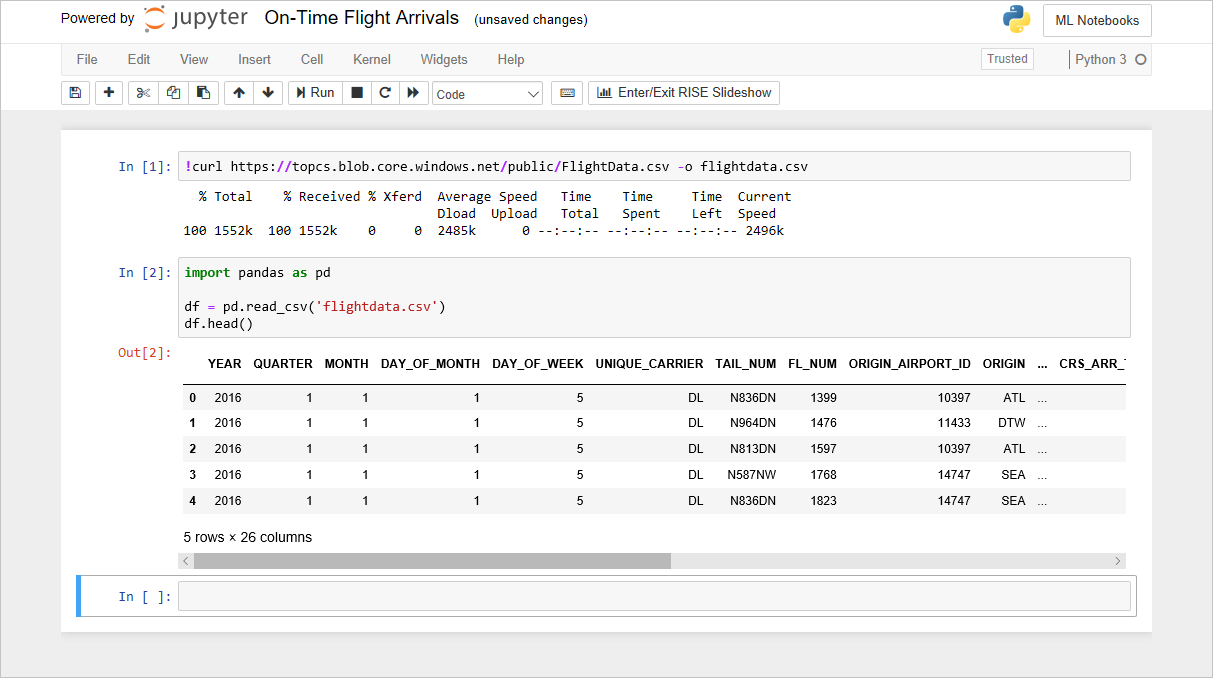
Il notebook FlightData
Il codice aggiunto al notebook nel lab precedente crea un DataFrame da flightdata.csv e chiama DataFrame.head su di esso per visualizzare le prime cinque righe. Una delle prime cose generalmente da sapere su un set di dati è il numero di righe che contiene. Per ottenere un conteggio, digitare l'istruzione seguente in una cella vuota alla fine del notebook ed eseguirla:
df.shapeVerificare che il DataFrame contenga 11.231 righe e 26 colonne:

Ottenere un conteggio di righe e colonne
Ora esaminare le 26 colonne nel set di dati. Contengono informazioni importanti, ad esempio la data del volo (YEAR, MONTH e DAY_OF_MONTH), l'origine e la destinazione (ORIGIN e DEST), gli orari di partenza e arrivo previsti (CRS_DEP_TIME e CRS_ARR_TIME), la differenza tra l'orario di arrivo previsto e quello effettivo in minuti (ARR_DELAY) e se il volo ha avuto un ritardo di 15 minuti o più (ARR_DEL15).
Di seguito è riportato l'elenco completo delle colonne presenti nel set di dati. Gli orari sono espressi nel sistema orario a 24 ore. Ad esempio, 1130 equivale alle 11:30 e 1500 equivale alle 15:00.
Colonna Descrizione YEAR Anno in cui è stato effettuato il volo QUARTER Trimestre in cui è stato effettuato il volo (1-4) MONTH Mese in cui è stato effettuato il volo (1-12) DAY_OF_MONTH Giorno del mese in cui è stato effettuato il volo (1-31) DAY_OF_WEEK Giorno della settimana in cui è stato effettuato il volo (1=lunedì, 2=martedì e così via) UNIQUE_CARRIER Codice del vettore aereo (ad esempio, DL) TAIL_NUM Numero di coda dell'aereo FL_NUM Numero di volo ORIGIN_AIRPORT_ID ID dell'aeroporto di origine ORIGIN Codice dell'aeroporto di origine (ATL, DFW, SEA e così via) DEST_AIRPORT_ID ID dell'aeroporto di destinazione DEST Codice dell'aeroporto di destinazione (ATL, DFW, SEA e così via) CRS_DEP_TIME Orario di partenza previsto DEP_TIME Orario di partenza effettivo DEP_DELAY Numero di minuti di ritardo della partenza DEP_DEL15 0=Partenza ritardata di meno di 15 minuti, 1=Partenza ritardata di 15 minuti o più CRS_ARR_TIME Orario di arrivo previsto ARR_TIME Orario di arrivo effettivo ARR_DELAY Numero di minuti di ritardo dell'arrivo del volo ARR_DEL15 0=Arrivato con un ritardo inferiore ai 15 minuti, 1=Arrivato con un ritardo di 15 minuti o più CANCELLED 0=Volo non cancellato, 1=Volo cancellato DIVERTED 0=Volo non deviato, 1=Volo deviato CRS_ELAPSED_TIME Durata prevista del volo in minuti ACTUAL_ELAPSED_TIME Durata effettiva del volo in minuti DISTANCE Distanza percorsa in miglia
Il set di dati include una distribuzione approssimativamente uniforme di date nell'arco dell'anno. Ciò è importante perché un volo in partenza da Minneapolis avrà minori probabilità di subire ritardi a causa di tempeste invernali nel mese di luglio rispetto a gennaio. Ma questo set di dati è tutt'altro che "pulito" e pronto all'uso. Si scriverà ora il codice Pandas per pulirlo.
Uno degli aspetti più importanti della preparazione di un set di dati per l'uso nel Machine Learning è la selezione delle colonne delle "caratteristiche" rilevanti per il risultato che si sta cercando di prevedere, mentre l'esclusione delle colonne che non influiscono sul risultato può condizionarlo in modo negativo o produrre multicollinearità. Un'altra attività importante consiste nell'eliminazione dei valori mancanti, eliminando le righe o le colonne che li contengono oppure sostituendoli con valori significativi. In questo esercizio verranno eliminate le colonne estranee e sostituiti i valori mancanti nelle restanti colonne.
Uno dei primi elementi che i data scientist cercano in genere in un set di dati sono i valori mancanti. Pandas offre un modo semplice per controllare i valori mancanti. Per una dimostrazione, eseguire il codice seguente in una cella alla fine del notebook:
df.isnull().values.any()Verificare che l'output sia "True". Ciò indica la presenza di almeno un valore mancante nel set di dati.

Controllo dei valori mancanti
Il passaggio successivo consiste nell'individuare i valori mancanti. A questo scopo, eseguire il codice seguente:
df.isnull().sum()Verificare di avere ottenuto l'output seguente che riporta il conteggio dei valori mancanti in ogni colonna:
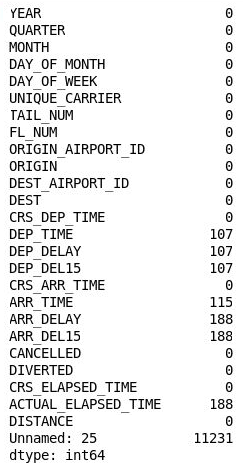
Numero di valori mancanti in ogni colonna
La colonna 26 ("Unnamed: 25") contiene curiosamente 11.231 valori mancanti, che equivale al numero di righe presenti nel set di dati. Questa colonna è stata creata erroneamente perché il file con estensione csv importato contiene una virgola alla fine di ogni riga. Per eliminare questa colonna, aggiungere il codice seguente al notebook ed eseguirlo:
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()Ispezionare l'output e verificare che la colonna 26 sia stata eliminata dal DataFrame:
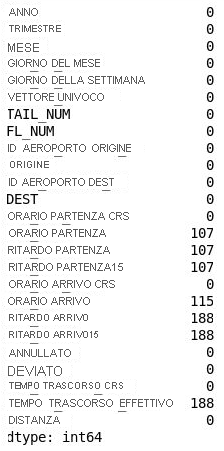
DataFrame con la colonna 26 rimossa
Il DataFrame presenta ancora molti valori mancanti, ma alcuni di essi non sono utili perché le colonne che li contengono non sono rilevanti per il modello che si sta creando. L'obiettivo del modello è prevedere le probabilità di arrivo puntuale di un volo che si vorrebbe prenotare. Se si sa che il volo sarà probabilmente in ritardo, si può decidere di prenotare un altro volo.
Il passaggio successivo consiste quindi nel filtrare il set di dati per eliminare le colonne non rilevanti per un modello predittivo. Il numero di coda dell'aereo, ad esempio, probabilmente incide poco sulla puntualità di un volo e quando si acquista un biglietto non si sa se un volo sarà cancellato, deviato oppure se sarà in ritardo. Per contro, l'orario di partenza previsto potrebbe incidere molto sull'arrivo puntuale. A causa del sistema hub e spoke usato dalla maggior parte delle compagnie aeree, la puntualità dei voli della mattina tende a essere più frequente rispetto a quella dei voli pomeridiani o serali. E in alcuni degli aeroporti più importanti il traffico si accumula durante la giornata, aumentando le probabilità di ritardo dei voli successivi.
Pandas consente di escludere facilmente le colonne che non si vuole includere. Eseguire il codice seguente in una nuova cella alla fine del notebook:
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()Nell'output si può vedere che il DataFrame ora include solo le colonne rilevanti per il modello e il numero di valori mancanti è notevolmente diminuito:
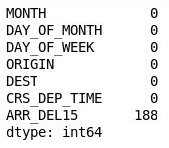
DataFrame filtrato
L'unica colonna contenente valori mancanti è ora la colonna ARR_DEL15, che usa 0 per identificare i voli arrivati in orario e 1 per i voli in ritardo. Usare il codice seguente per visualizzare le prime cinque righe con valori mancanti:
df[df.isnull().values.any(axis=1)].head()Pandas rappresenta i valori mancanti con
NaNche è l'acronimo di Not a Number (Non un numero). L'output indica che queste righe sono effettivamente valori mancanti nella colonna ARR_DEL15: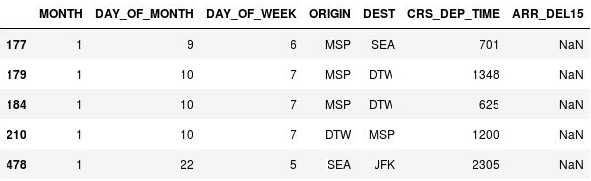
Righe con valori mancanti
Il motivo per cui in queste righe mancano i valori ARR_DEL15 è che tutte corrispondono a voli cancellati o deviati. Per rimuovere queste righe si può chiamare dropna sul DataFrame. Ma poiché un volo cancellato o deviato in un altro aeroporto può essere considerato "in ritardo", verrà usato il metodo fillna per sostituire i valori mancanti con 1.
Usare il codice seguente per sostituire i valori mancanti nella colonna ARR_DEL15 con 1 e visualizzare le righe dalla 177 alla 184:
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]Verificare che i valori
NaNnelle righe 177, 179 e 184 siano stati sostituiti con 1 che indica che i voli sono arrivati in ritardo: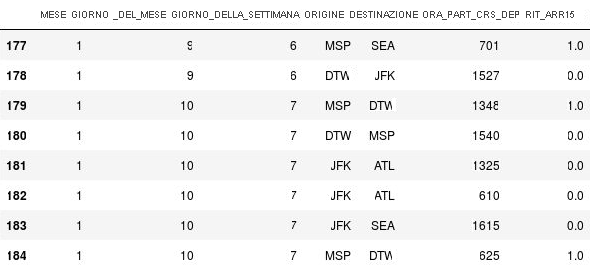
Valori NaN sostituiti con 1
Il set di dati ora è "pulito" nel senso che i valori mancanti sono stati sostituiti e l'elenco di colonne è stato limitato a quelle più rilevanti per il modello. Ma la procedura non è ancora finita. La preparazione del set di dati per l'uso nel Machine Learning richiede altre operazioni.
La colonna CRS_DEP_TIME del set di dati in uso rappresenta gli orari di partenza previsti. La granularità dei numeri in questa colonna che contiene più di 500 valori univoci potrebbe influire negativamente sull'accuratezza di un modello di Machine Learning. Questo problema può essere risolto con una tecnica denominata binning o quantizzazione. Se si dividesse ogni numero contenuto nella colonna per 100 e lo si arrotondasse per difetto all'intero più vicino, 1030 diventerebbe 10, 1925 diventerebbe 19 e così via. Nella colonna rimarrebbe così un massimo di 24 valori discreti. Intuitivamente, ciò ha senso perché probabilmente non ha molta importanza se un volo parte alle 10:30 o alle 10:40. È invece molto importante sapere se parte alle 10:30 o alle 17:30.
Le colonne ORIGIN e DEST del set di dati contengono inoltre i codici degli aeroporti che rappresentano valori di Machine Learning categorici. È necessario convertire queste colonne in colonne discrete contenenti variabili indicatore, talvolta note come variabili "fittizie". In altre parole, la colonna ORIGIN, che contiene cinque codici di aeroporto, deve essere convertita in cinque colonne, una per aeroporto, con ogni colonna che contiene 1 e 0 che indicano se un volo ha avuto origine dall'aeroporto rappresentato dalla colonna. La colonna DEST deve essere gestita in modo simile.
In questo esercizio si eseguirà il "binning" degli orari di partenza nella colonna CRS_DEP_TIME e si userà il metodo get_dummies di Pandas per creare colonne indicatore dalle colonne ORIGIN e DEST.
Per visualizzare le prime cinque righe del DataFrame usare il comando seguente:
df.head()Osservare che la colonna CRS_DEP_TIME contiene valori da 0 a 2359 che rappresentano il sistema orario a 24 ore.
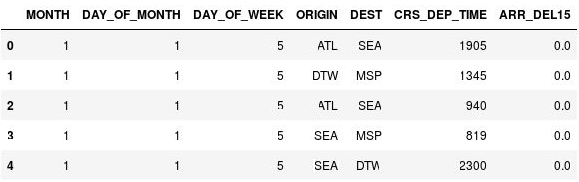
DataFrame con orari di partenza senza binning
Per eseguire il binning degli orari di partenza usare le istruzioni seguenti:
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()Verificare che i numeri presenti nella colonna CRS_DEP_TIME ora rientrino nell'intervallo compreso tra 0 e 23:
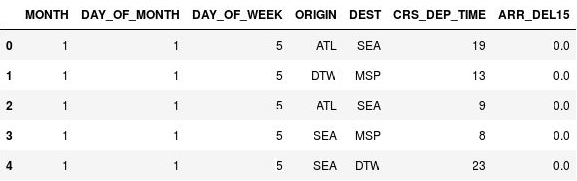
DataFrame con orari di partenza sottoposti a binning
Ora usare le istruzioni seguenti per generare colonne indicatore dalle colonne ORIGIN e DEST eliminando allo stesso tempo le colonne ORIGIN e DEST:
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()Esaminare il DataFrame risultante e osservare che le colonne ORIGIN e DEST sono state sostituite con colonne corrispondenti ai codici di aeroporto presenti nelle colonne originali. Le nuove colonne includono 1 e 0 che indicano se uno specifico volo ha avuto origine o aveva come destinazione l'aeroporto corrispondente.

DataFrame con colonne indicatore
Usare il comando File ->Salva ed esegui checkpoint per salvare il notebook.
Il set di dati ha un aspetto molto diverso da quello iniziale, ma ora è ottimizzato per l'uso nel Machine Learning.