Esercizio - Caricare ed eseguire query sui dati in HDInsight
Ora che è stato effettuato il provisioning di un account di archiviazione e di un cluster Interactive Query è possibile caricare i dati immobiliari ed eseguire alcune query. I dati da caricare sono i dati immobiliari della città di New York. Includono oltre 28.000 record di proprietà, inclusi indirizzi, prezzi di vendita, superfici e informazioni sul percorso geocodificato per semplificare il mapping. La società immobiliare usa queste informazioni per determinare i prezzi corretti al metro quadro per le nuove proprietà immesse sul mercato, in base ai prezzi di vendita delle proprietà vendute in precedenza.
Per caricare i dati ed eseguire query si userà Data Analytics Studio, un'applicazione basata sul Web che è stata installata nell'azione di script usata durante la creazione del cluster Interactive Query. È possibile usare Data Analytics Studio per caricare i dati in Archiviazione di Azure, trasformare i dati in tabelle di Hive usando i tipi di dati e i nomi di colonna impostati, quindi eseguire query sui dati nel cluster usando HiveQL. Oltre a Data Analytics Studio è possibile usare qualsiasi strumento compatibile con ODBC/JDBC per lavorare con i dati usando Hive, ad esempio strumenti Spark e Hive per Visual Studio Code.
Si userà quindi un notebook Zeppelin per visualizzare rapidamente le tendenze nei dati. I notebook Zeppelin consentono di inviare query e visualizzare i risultati in una serie di grafici predefiniti diversi. I notebook Zeppelin installati nei cluster Interactive Query hanno un interprete JDBC con driver Hive.
Scaricare dati immobiliari
- Accedere a https://github.com/Azure/hdinsight-mslearn/tree/master/Sample%20data e scaricare il set di dati per salvare il file propertysales.csv nel computer.
Caricare i dati con Data Analytics Studio
- Aprire quindi Data Analytics Studio nel browser Internet usando l'URL seguente, sostituendo servername con il nome del cluster usato: https://servername.azurehdinsight.net/das/
Per accedere, il nome utente è admin e la password è la password creata.
Se si verifica un errore, passare alla scheda Panoramica del cluster nel portale di Azure e verificare che lo stato sia impostato su In esecuzione e che il tipo di cluster, versione HDI sia impostato su Interactive Query 3.1 (HDI 4.0).
- Data Studio Analytics viene avviato nel browser Internet.
- Fare clic su Database nel menu a sinistra, quindi fare clic sul pulsante con i puntini verticali verdi e successivamente su Crea database.
Rinominare il database "newyorkrealestate", quindi fare clic su Crea.
In Esplora database fare clic sulla casella del nome del database, quindi selezionare newyorkrealestate.
- In Esplora database fare clic su + e quindi su Crea tabella.
- Assegnare alla nuova tabella il nome "propertysales" e quindi fare clic su Carica tabella. I nomi delle tabelle devono contenere solo lettere minuscole e numeri, nessun carattere speciale.
- Nell'area Seleziona formato file della pagina:
- Verificare che il formato del file sia CSV
- Selezionare la casella la Is first row header? (Intestazione prima riga?).
- Nell'area Seleziona origine file della pagina:
- Selezionare Upload from Local (Carica da locale).
- Fare clic su Drag file to upload or click browse (Trascinare il file per caricarlo o fare clic su Sfoglia) e passare al file di propertysales.csv.
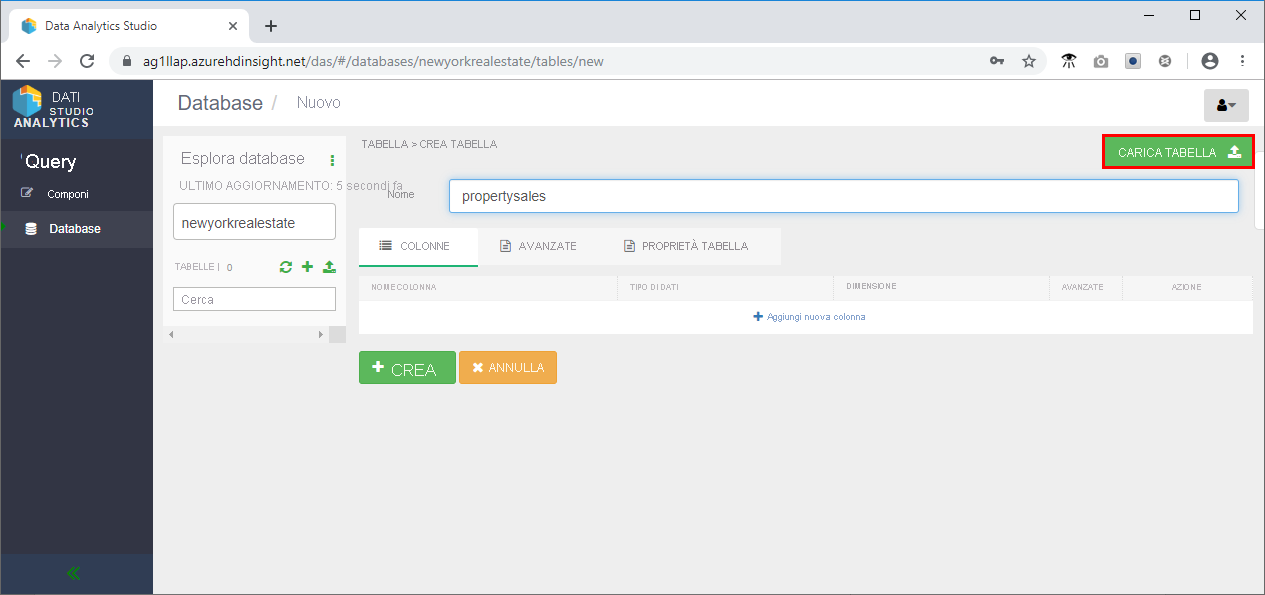
- Nella sezione Colonne modificare il tipo di dati di Latitudine e Longitudine in Stringae la data di vendita in una data.
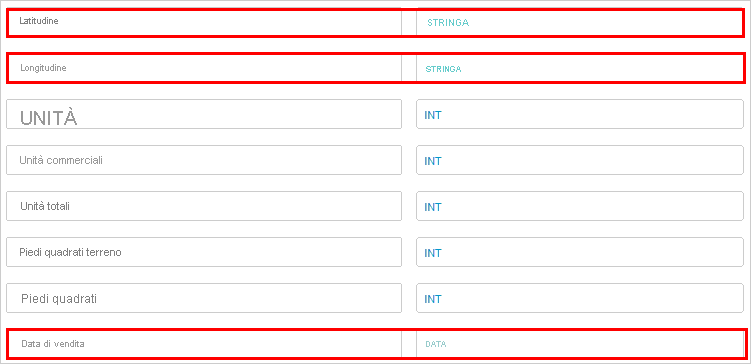
- Scorrere verso l'alto ed esaminare la sezione Anteprima tabella per verificare che le intestazioni di colonna siano corrette.
- Scorrere verso il basso e fare clic su Crea per creare la tabella Hive nel database newyorkrealestate.

- Nel menu a sinistra fare clic su Componi.
- Provare a eseguire la query Hive seguente per verificare che tutto funzioni come previsto.
SELECT `ADDRESS`, `ZIP CODE`, `SALE PRICE`, `SQUARE FOOTAGE`
FROM newyorkrealestate.propertysales;
- L'output dovrebbe essere simile al seguente.
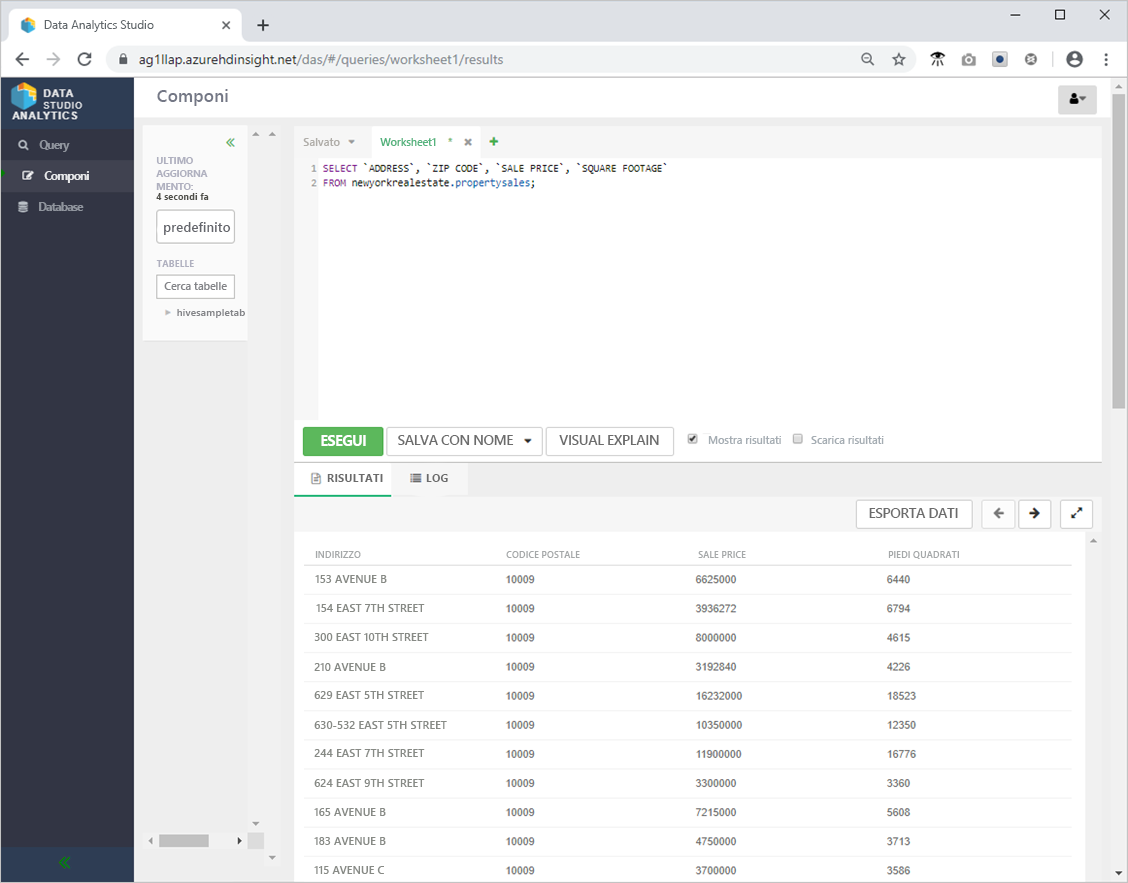
- Per esaminare le prestazioni della query, fare clic su Query nel menu a sinistra e quindi selezionare la query SELECT
ADDRESS,ZIP CODE,SALE PRICE,SQUARE FOOTAGEFROM newyorkrealestate.propertysales appena eseguita.
Se sono disponibili consigli per le prestazioni, lo strumento li mostrerà. In questa pagina viene inoltre visualizzata la query SQL effettiva che è stata eseguita, viene fornita una spiegazione visiva della query, vengono illustrati i dettagli di configurazione dedotti da Hive durante l'esecuzione della query e viene presentata una sequenza temporale che mostra il tempo impiegato per l'esecuzione di ogni parte della query.
Esplorare le tabelle Hive usando un notebook Zeppelin
- Nella casella Dashboard del cluster della pagina di panoramica nel portale di Azure fare clic su Notebook Zeppelin.
- Fare clic su Nuova nota, assegnare alla nota il nome Real Estate Data, quindi fare clic su Crea.
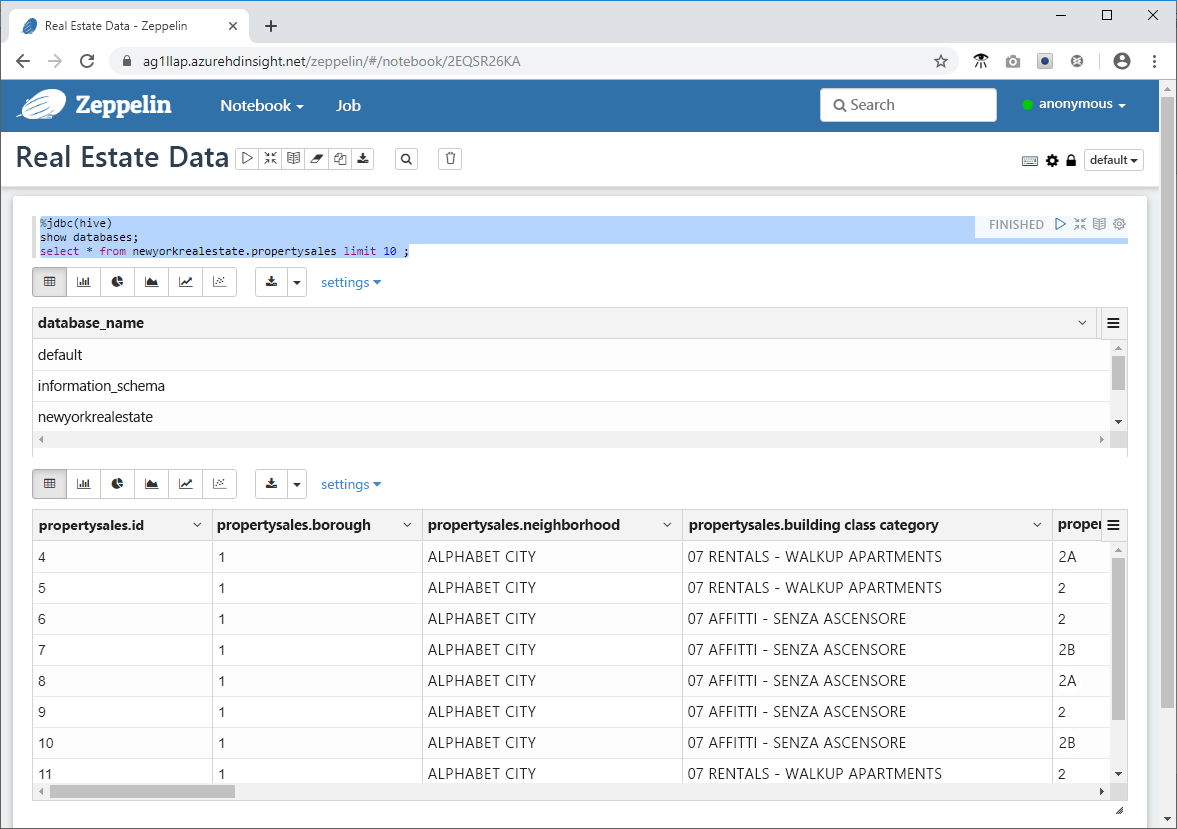
- Incollare il frammento di codice seguente nel prompt dei comandi nella finestra Zeppelin e fare clic sull'icona Riproduci.
%jdbc(hive)
show databases;
select * from newyorkrealestate.propertysales limit 10 ;
L'output della query viene visualizzato nella finestra. Si noterà che vengono restituiti i primi 10 risultati.
- È ora possibile attivare una query più complessa per usare alcune delle funzionalità di visualizzazione e di grafica disponibili in Zeppelin. Copiare la query seguente nel prompt dei comandi e fare clic.
%jdbc(hive)
select `sale price`, `square footage` from newyorkrealestate.propertysales
where `sale price` < 20000000 AND `square footage` < 50000;
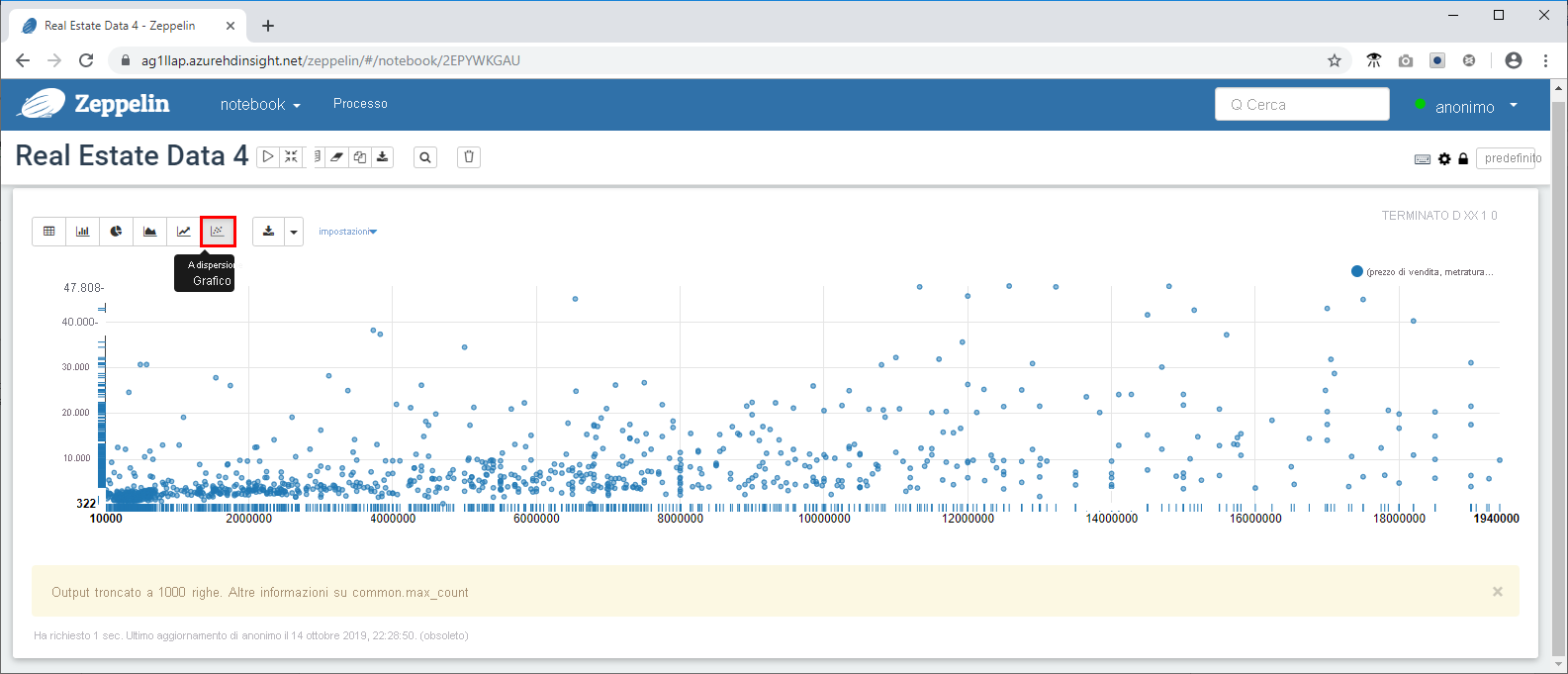
Per impostazione predefinita, l'output della query viene visualizzato in formato tabella. Selezionare invece Grafico a dispersione per visualizzare uno degli oggetti visivi offerti dai notebook di Zeppelin.