Configurare la disponibilità elevata e il ripristino di emergenza
Gran parte della configurazione per il ripristino di emergenza e le soluzioni a disponibilità elevata in SQL Server resta immutata in SQL Server eseguito in una macchina virtuale di Azure. La soluzione a disponibilità elevata è progettata per garantire che nessun dato sottoposto a commit venga perso a causa di errori, che il carico di lavoro non venga influenzato dalle operazioni di manutenzione e che il database non diventi un singolo punto di guasto nell'architettura del software.
La maggior parte dei livelli di servizio Azure SQL offre una gamma di opzioni a disponibilità elevata, dalla ridondanza locale ai modelli di ridondanza della zona.
Successivamente, esploreremo le soluzioni specifiche per il ripristino di emergenza e la disponibilità elevata per le offerte PaaS di Azure.
Backup continuo
Il database SQL di Azure assicura backup continui e regolari dei database, che vengono poi replicati in un'archiviazione con ridondanza geografica e accesso in lettura (RA-GRS).
I backup completi settimanali, i backup differenziali ogni 12-24 ore e i backup dei log delle transazioni ogni 5-10 minuti fanno parte della strategia di backup automatizzata. Per garantire una disponibilità estesa dei backup (fino a 10 anni), la conservazione a lungo termine può essere configurata sia per i database singoli che per i database in pool.
Conservazione a lungo termine (LTR)
Azure offre un criterio di conservazione che è possibile impostare oltre i limiti standard, che risulta particolarmente utile per gli scenari che richiedono una conservazione a lungo termine. È possibile impostare criteri di conservazione per un massimo di 10 anni, anche se questa opzione è disabilitata per impostazione predefinita.

L'immagine mostra come configurare i criteri di conservazione a lungo termine nel portale di Azure. Dopo aver scelto il database, sul lato destro dello schermo viene visualizzato un pannello in cui è possibile modificare le impostazioni predefinite.
Per altre informazioni sulla conservazione a lungo termine, vedere Conservazione a lungo termine - database Azure SQL e Istanza gestita di SQL di Azure.
Ripristino geografico
I backup per database SQL e Istanza gestita di SQL sono con ridondanza geografica per impostazione predefinita. In questo modo è possibile ripristinare facilmente i database in un'area geografica differente. Si tratta di una funzionalità utile per scenari di ripristino di emergenza meno rigorosi.
L'archiviazione dei backup viene fatturata a parte rispetto alla normale archiviazione dei file di database. Tuttavia, quando si esegue il provisioning di un database SQL, la risorsa di archiviazione dei backup viene creata con la dimensione massima del livello dati selezionato per il database senza costi aggiuntivi.
La durata di un'operazione di ripristino geografico può dipendere da diversi componenti sottostanti, tra cui la dimensione del database, il numero di log delle transazioni coinvolti in un'operazione di ripristino e la quantità di richieste di ripristino simultanee elaborate nell'area di destinazione.
Ripristino temporizzato
È possibile ripristinare i database in un momento specifico in base al periodo di conservazione definito. Tuttavia, il ripristino temporizzato è possibile solo se il database viene ripristinato nello stesso server in cui è stato generato il backup. Per ripristinare un database SQL è possibile usare il portale di Azure, Azure PowerShell, l'interfaccia della riga di comando di Azure o l'API REST.
Replica geografica attiva
Un modo per aumentare la disponibilità del database SQL di Azure consiste nell'usare la replica geografica attiva. Questa funzionalità crea una replica del database secondaria in un'altra area che viene costantemente aggiornata in modo asincrono.
Questa replica è leggibile, simile a un gruppo di disponibilità AlwaysOn in SQL Server. Sotto la superficie, Azure usa i gruppi di disponibilità per mantenere questa funzionalità. Questo è il motivo per cui alcune delle terminologie sono simili.
La replica geografica attiva offre continuità aziendale consentendo ai clienti di eseguire il failover a livello di codice o eseguire manualmente il failover dei database primari nelle aree secondarie durante un'emergenza grave.
Nota
Istanza gestita di SQL di Azure non supporta la replica geografica attiva. Invece è necessario usare i gruppi di failover automatico, che è un argomento che verrà esaminato più avanti in questa unità.
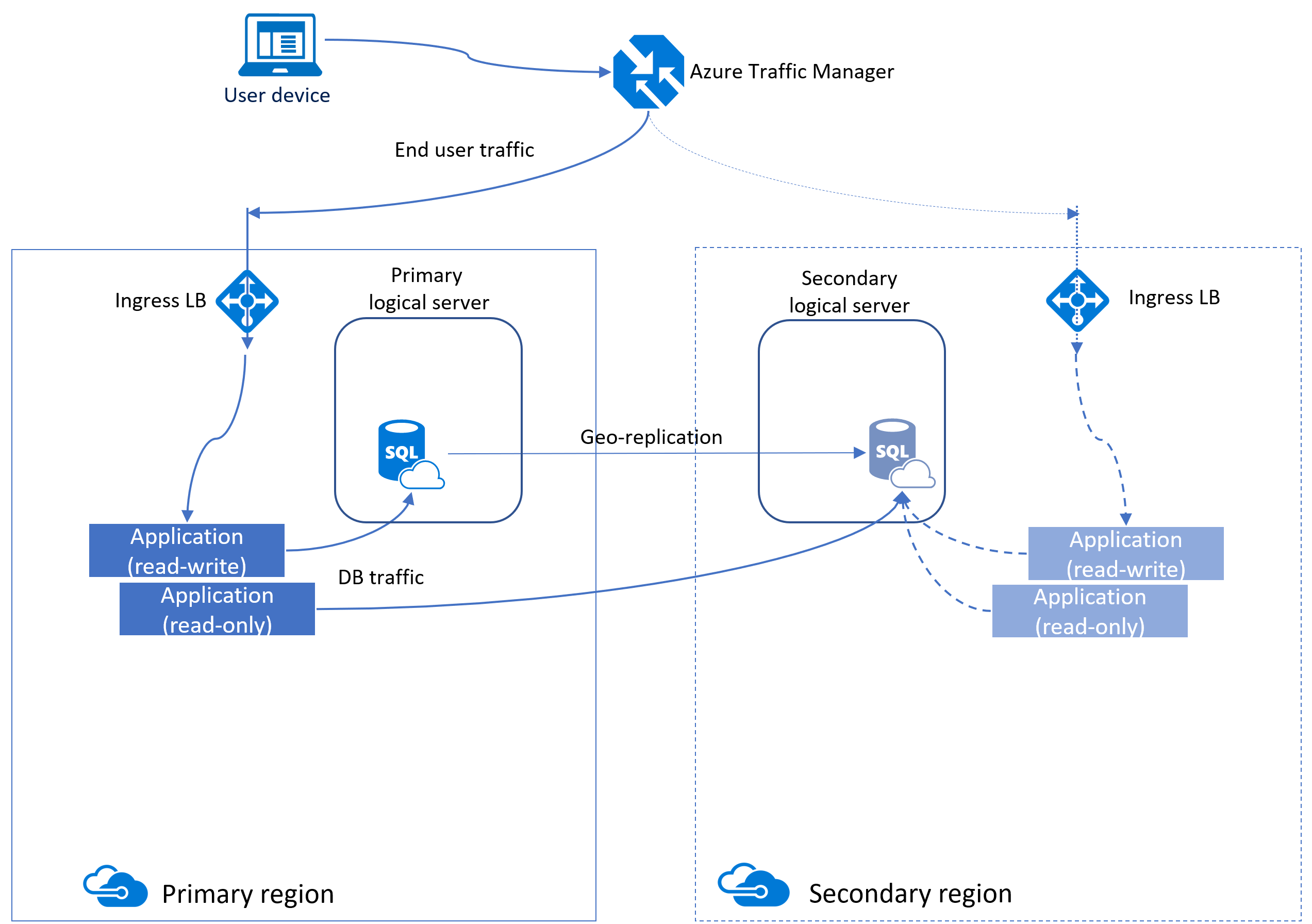
Tutti i database coinvolti in una relazione di replica geografica devono avere lo stesso livello di servizio. Inoltre, per evitare problemi di prestazioni di replica dovuti a un carico di lavoro di scrittura elevato, è consigliabile configurare la replica secondaria con le stesse dimensioni di calcolo della primaria.

È possibile configurare manualmente la replica geografica per il database SQL di Azure accedendo al pannello per il database, nella sezione Gestione dati, selezionando Repliche e quindi + Crea replica.

Dopo aver stabilito la replica secondaria, è possibile avviare manualmente un failover. In questo processo i ruoli vengono invertiti: la replica secondaria assume il ruolo del database primario, mentre la replica primaria originale diventa secondaria.
Replica geografica tra sottoscrizioni
In determinati scenari, è necessario configurare una replica secondaria in una sottoscrizione diversa rispetto al database primario. È qui che entra in gioco la funzionalità di replica geografica tra sottoscrizioni.
Nota
La replica geografica tra sottoscrizioni è disponibile solo in modo programmatico.
Per altre informazioni sui passaggi necessari per configurare una replica geografica tra sottoscrizioni, vedere Replica geografica tra sottoscrizioni.
Gruppi di failover automatico
Un gruppo di failover automatico è una funzionalità a disponibilità elevata supportata sia dal database SQL di Azure che da Istanza gestita di SQL di Azure. I gruppi di failover automatico consentono di gestire le modalità di replica dei database in un'altra area e le modalità in cui potrebbe verificarsi un failover. Il nome assegnato al gruppo di failover automatico deve essere univoco all'interno del dominio *.database.windows.net.
Un gruppo di failover automatico può includere più database. Sia il database primario che quello secondario hanno le stesse dimensioni.
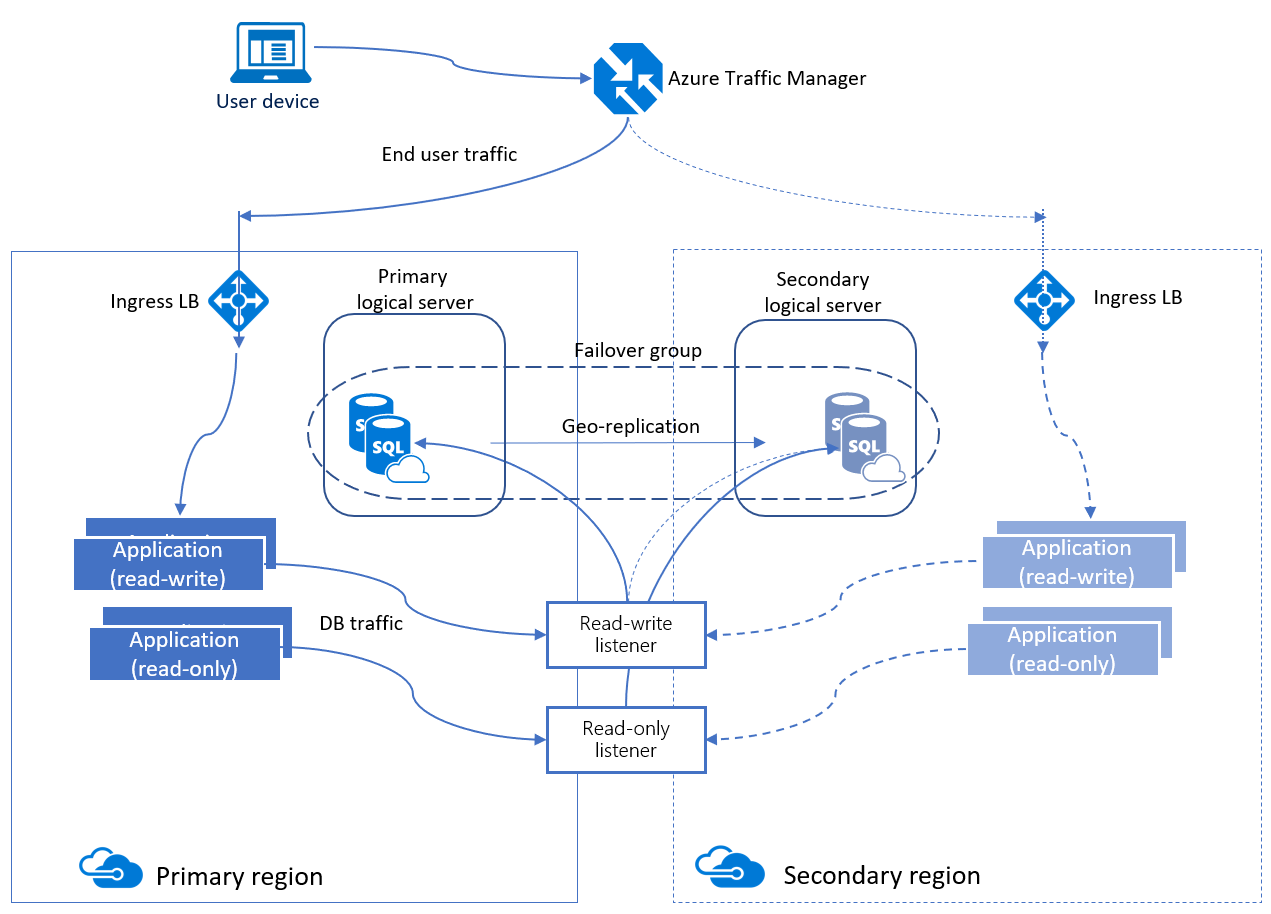
I gruppi di failover automatico forniscono una funzionalità di tipo gruppo di disponibilità denominata listener, che consente le attività sia di lettura/scrittura sia di sola lettura. Esistono due tipi diversi di listener: uno per le attività di lettura/scrittura e uno per il traffico di sola lettura. Quando si verifica un failover, il DNS viene aggiornato in modo che i client possano continuare ad accedere al servizio attraverso lo stesso nome del listener, senza necessità di conoscere ulteriori dettagli. Il server di database contenente le copie di lettura/scrittura è quello primario e il server che riceve le transazioni dal database primario è il secondario.
Esistono due criteri diversi per i gruppi di failover automatico.
| Tipo di criteri | Descrizione |
|---|---|
| Automatico | Quando viene rilevato un errore, il sistema attiva automaticamente un failover per impostazione predefinita. Tuttavia, se necessario, è possibile disabilitare il failover automatico. |
| Sola lettura | Durante un failover, il motore disabilita il listener di sola lettura per impostazione predefinita in modo da preservare le prestazioni del nuovo database primario quando il database secondario non è operativo. Tuttavia, è possibile modificare questo comportamento per consentire entrambi i tipi di traffico dopo un failover. |
Il failover è un processo che può essere avviato manualmente, anche quando è abilitato il failover automatico. Tuttavia, il tipo di failover può influire sulla potenziale perdita di dati. Ad esempio, un failover non pianificato può causare la perdita di dati se viene forzato e il database secondario non è completamente sincronizzato con il database primario.
L’opzione GracePeriodWithDataLossHours determina quanto tempo Azure attende prima di avviare un failover, con il valore predefinito impostato su un'ora. Se l'obiettivo del punto di ripristino (RPO) è rigoroso e la perdita di dati non è inaccettabile, è possibile impostare un valore più elevato per questa opzione. Anche se questo significa che Azure attende più a lungo prima di avviare un failover, potrebbe potenzialmente ridurre la perdita di dati in quanto fornisce più tempo al database secondario per sincronizzarsi completamente con quello primario.
Nota
Il database secondario viene creato automaticamente tramite un processo noto come seeding, che può richiedere tempo a seconda delle dimensioni del database. Pertanto, è importante pianificare in anticipo, considerando fattori come la velocità della rete.
Per altre informazioni sulla disponibilità elevata e sul ripristino di emergenza per il database SQL di Azure, vedere Elenco di controllo per la disponibilità elevata e il ripristino di emergenza del database SQL di Azure.