Trasmettere dati in streaming con Apache Kafka
Apache Kafka è stato creato da LinkedIn nel 2010, con l'obiettivo di trasferire i dati su scala molto elevata, a latenza molto bassa e con un alto livello di tolleranza di errore. LinkedIn ha poi donato il progetto ad Apache Foundation nel 2012, ma continua a usare Kafka in tutto il suo ecosistema per tenere traccia delle attività degli utenti, scambiare messaggi e raccogliere metriche.
Kafka è una piattaforma di streaming distribuita progettata per:
- Semplificare le pipeline di dati
- Gestire grandi quantità di dati in un modello di flusso
- Supportare sistemi di elaborazione in batch e in tempo reale
- Consentire una scalabilità elevata della capacità
Si esamineranno prima le caratteristiche di Apache Kafka puro e quindi quelle di Kafka in Azure HDInsight.
Componenti di Kafka
Prima di comprendere come funziona Kafka, si esamineranno i ruoli di alcuni componenti chiave e il modo in cui interagiscono per fornire un sistema di messaggistica altamente scalabile e a tolleranza di errore.
Gestore
Kafka è un servizio gestito in cluster e un singolo cluster Kafka è detto anche broker. I broker ricevono messaggi dai producer e li archiviano su disco. Rispondono inoltre alle richieste di dati provenienti dai consumer. All'interno di un cluster di broker, un singolo broker funge da controller ed è responsabile delle operazioni amministrative e dell'assegnazione di partizioni ai broker.
Message
Un messaggio è un'unità di dati in un cluster Kafka. Nella maggior parte dei casi, i messaggi sono costituiti da coppie chiave-valore.
Argomenti e partizioni
Gli argomenti e le partizioni sono categorie di messaggi in Kafka. Gli argomenti vengono in genere ripartiti tra una serie di partizioni per ottimizzare il processo, con un minimo consigliato di tre partizioni. I messaggi vengono scritti in una partizione di argomenti in modalità di solo accodamento. Le partizioni vengono ulteriormente replicate tra più broker per migliorare la ridondanza in caso di errori del broker. Le partizioni consentono la lettura in parallelo degli argomenti perché consentono la suddivisione dei dati tra più broker. Esiste una replica leader, che gestisce tutte le richieste di lettura e scrittura e da cui vengono replicate le partizioni follower. In caso di errore della replica leader, una delle altre repliche assume il ruolo di leader.
Producer e consumer
I producer e i consumer sono i client che producono e utilizzano i messaggi dal sistema Kafka. I producer pubblicano nuovi messaggi e li indirizzano a un argomento specifico. I consumer possono anche essere designati per la scrittura in una partizione di argomenti specifica. I consumer sottoscrivono a loro volta uno o più argomenti e leggono i messaggi da tali argomenti.
Gruppo di consumer
Uno o più consumer possono interagire tra loro come gruppo e utilizzare i messaggi di conseguenza. Se il numero di consumer è uguale al numero di partizioni di argomenti, ogni consumer utilizzerà una singola partizione, creando parallelismo.
Conservazione
I messaggi in Kafka possono essere conservati nel cluster Kafka per un periodo di tempo predefinito. Una volta raggiunti i limiti di conservazione, Kafka può impostare i messaggi come scaduti ed eliminarli.
Sfalsamento
Il termine offset, in questo caso, si riferisce semplicemente alla posizione di un messaggio in una partizione. L'aggiornamento della posizione corrente in una partizione durante l'elaborazione dei messaggi è definito commit. Dopo l'elaborazione di un messaggio, Kafka esegue il commit dell'offset del messaggio in uno specifico argomento interno. Quando un producer pubblica un messaggio in una partizione, il messaggio viene inoltrato alla partizione leader. Quest'ultima aggiunge il messaggio al log di commit e ne incrementa l'offset. L'offset dei messaggi indica il modo in cui i messaggi vengono identificati all'interno dell'argomento. Il messaggio è disponibile al consumer solo dopo che ne è stato eseguito il commit nel cluster.
Zookeeper
Zookeeper è un servizio di coordinamento. In un cluster Kafka, il servizio Zookeeper fornisce una visualizzazione sincronizzata dello stato del cluster. Kafka usa Zookeeper per selezionare la partizione leader tra le partizioni broker e quelle degli argomenti e anche per gestire l'individuazione dei servizi per i broker Kafka che formano il cluster. Zookeeper invia le modifiche della topologia a Kafka, in modo che ogni nodo del cluster sappia quando un nuovo broker è stato aggiunto o arrestato oppure quando un argomento è stato rimosso o aggiunto.
In che modo si combinano tutti questi elementi?
Le applicazioni (note anche come producer) inviano messaggi a un broker Kafka e i messaggi vengono elaborati da uno o più consumer. I messaggi in un cluster sono classificati per argomenti. Un cliente può, ad esempio, creare un argomento "Vendite" per inviare tutti i messaggi rilevanti per le vendite. Man mano che gli argomenti aumentano di dimensione con l'aumentare dei messaggi, vengono suddivisi in partizioni e le partizioni vengono ulteriormente replicate tra i broker Kafka per assicurare ridondanza. Le partizioni sono classificate come leader e follower. La partizione leader supporta operazioni di scrittura e lettura, mentre le partizioni follower sono semplici repliche, che vengono aggiornate in base allo stato della partizione leader. Per determinare la partizione in cui scrivere e leggere, i producer e i consumer devono conoscere le partizioni designate come leader. I nodi Zookeeper gestiscono lo stato del cluster Kafka e, tra le altre cose, scelgono le partizioni leader e forniscono queste informazioni ai producer e ai consumer.
Kafka garantisce che i messaggi relativi a una partizione siano ordinati in base alla sequenza di arrivo. Un determinato messaggio può essere chiaramente identificato tramite il relativo offset, ovvero la posizione che occupa all'interno di una partizione. Il consumer legge i messaggi dalle partizioni e, dopo l'elaborazione, esegue il commit dell'offset indicando che il messaggio è stato elaborato correttamente. Kafka archivia tutti i record sul disco e gestisce la persistenza dei messaggi. Nel caso in cui il consumer si arresti per qualche motivo e l'elaborazione si interrompa, Kafka conserva questi messaggi per un periodo predeterminato. Dopo essere tornato online, il consumer può riavviare l'elaborazione a partire dall'ultimo offset sottoposto a commit prima dell'interruzione.
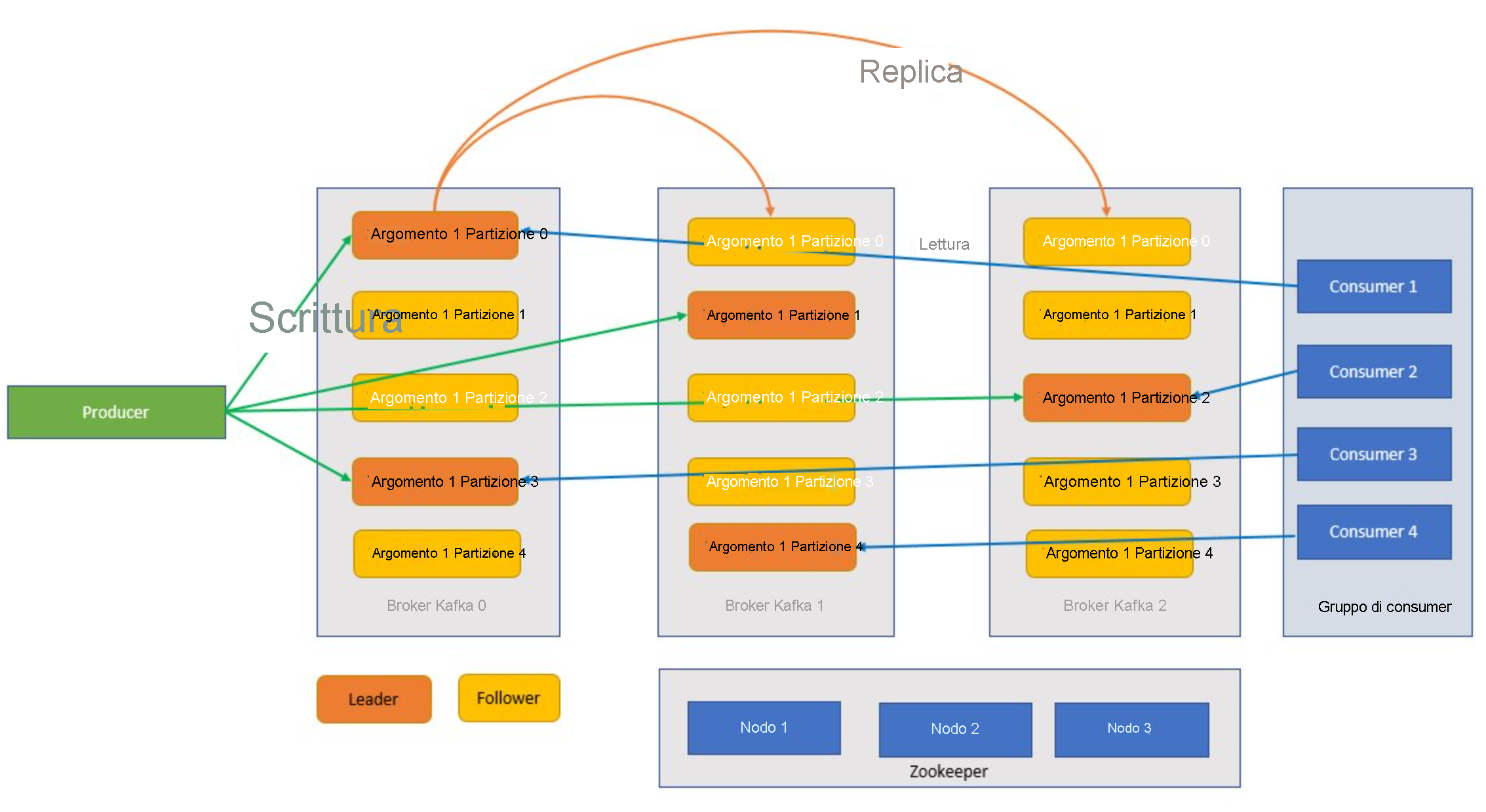
Argomenti Kafka
Un argomento Kafka è un feed o una coda in cui i messaggi vengono archiviati e pubblicati. I producer effettuano il push dei messaggi agli argomenti e i consumer leggono i dati dagli argomenti. Ogni nodo di un broker Kafka può contenere più argomenti.
Quali sono i vantaggi offerti da Kafka in Azure HDInsight?
La versione open source di Kafka offre molte funzionalità, ma richiede un particolare impegno di configurazione. Azure HDInsight offre un eccellente framework per l'analisi open source in Azure e consente ai clienti di configurare i propri cluster open source in pochi minuti, in modo da poterli usare immediatamente, anziché dover impiegare molto tempo per la configurazione. HDInsight è anche un prodotto di livello aziendale in grado di offrire i vantaggi seguenti:
- È un servizio gestito che fornisce un processo di configurazione semplificato. Il risultato è una configurazione che viene testata e supportata da Microsoft.
- Microsoft offre un Contratto di servizio (SLA) con tempo di attività pari al 99,9% per Spark e Kafka.
- Usa gli Azure Managed Disks come archivio di backup per Kafka. La funzionalità Managed Disks può offrire fino a 16 TB di spazio di archiviazione per broker Kafka, con più broker Kafka.
- HDInsight offre un livello ottimale di sicurezza aziendale con le reti virtuali, i controlli di sicurezza con granularità fine di Apache Ranger e la crittografia Bring Your Own Key (BYOK) per i dati inattivi.
- È assicurata la conformità per HIPAA, SOC e PCI.
- È possibile distribuire pipeline di streaming end-to-end con Spark e Archiviazione tramite modelli automatizzati di Azure Resource Manager (ARM) nella stessa rete virtuale.
- La disponibilità elevata è resa possibile da Kafka MirrorMaker, che può utilizzare i record degli argomenti del cluster primario e quindi creare una copia locale nel cluster secondario.
- HDInsight consente di modificare il numero dei nodi di lavoro, che ospitano il broker Kafka, dopo la creazione del cluster. Il ridimensionamento può essere eseguito con il portale di Azure, Azure PowerShell e altre interfacce di gestione di Azure. Per Kafka, è consigliabile ribilanciare le repliche delle partizioni dopo le operazioni di ridimensionamento. Il ribilanciamento delle partizioni consente a Kafka di sfruttare il nuovo numero di nodi di lavoro.
- I log di Monitoraggio di Azure possono essere usati per monitorare Kafka in HDInsight. Monitoraggio di Azure registra le informazioni a livello superficiale di macchina virtuale, ad esempio le metriche del disco e della scheda di interfaccia di rete e le metriche JMX da Kafka.