Selezionare la libreria MPI corretta
Gli SKU HB120_v2, HB60 e HC44 supportano le interconnessioni di rete InfiniBand. Poiché PCI Express è virtualizzato tramite la virtualizzazione SR-IOV (Single-Root Input/Output), in queste macchine virtuali HPC sono disponibili tutte le librerie MPI più diffuse (HPCX, OpenMPI, Intel MPI, MVAPICH e MPICH).
La limitazione corrente per un cluster HPC in grado di comunicare tramite InfiniBand è pari a 300 macchine virtuali. La tabella seguente elenca il numero massimo di processi in parallelo supportati nelle applicazioni MPI tightly coupled che comunicano tramite InfiniBand.
| SKU | Numero massimo di processi in parallelo |
|---|---|
| HB120_v2 | 36.000 processi |
| HC44 | 13.200 processi |
| HB60 | 18.000 processi |
Nota
Questi limiti potrebbero cambiare in futuro. Se è presente un processo MPI tightly coupled che richiede un limite superiore, inviare una richiesta di supporto. Potrebbe essere possibile aumentare i limiti per la situazione specifica.
Se un'applicazione HPC consiglia una specifica libreria MPI, provare prima di tutto tale versione. Se si può con maggiore flessibilità la libreria MPI e si vogliono ottenere prestazioni ottimali, provare HPCX. In generale, HPCX MPI garantisce prestazioni migliori con il framework UCX per l'interfaccia InfiniBand e sfrutta tutte le funzionalità hardware e software di Mellanox InfiniBand.
Nella figura seguente vengono confrontate le architetture di libreria MPI più diffuse.
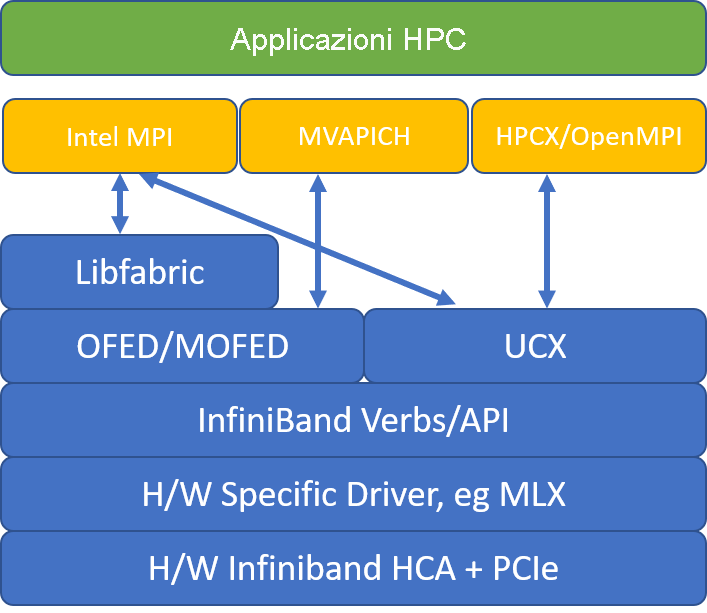
HPCX e OpenMPI sono compatibili con ABI ed è quindi possibile eseguire dinamicamente un'applicazione HPC con HPCX compilata con OpenMPI. Analogamente, Intel MPI, MVAPICH e MPICH supportano ABI.
La coppia di code 0 non è accessibile alla macchina guest, in modo da evitare eventuali vulnerabilità di sicurezza tramite l'accesso hardware di basso livello. Questa limitazione non dovrebbe avere alcun effetto sulle applicazioni HPC degli utenti finali, ma potrebbe impedire il corretto funzionamento di alcuni strumenti di basso livello.
Argomenti di mpirun per HPCX e OpenMPI
Il comando seguente illustra alcuni argomenti consigliati di mpirun per HPCX e OpenMPI:
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
In tale comando:
| Parametro | Descrizione |
|---|---|
$NPROCS |
Specifica il numero di processi MPI. Ad esempio: -n 16. |
$HOSTFILE |
Specifica un file contenente il nome host o l'indirizzo IP, per indicare il percorso nel quale vengono eseguiti i processi MPI. Ad esempio: --hostfile hosts. |
$NUMBER_PROCESSES_PER_NUMA |
Specifica il numero di processi MPI eseguiti in ogni dominio NUMA. Per specificare, ad esempio, quattro processi MPI per NUMA, usare --map-by ppr:4:numa:pe=1. |
$NUMBER_THREADS_PER_PROCESS |
Specifica il numero di thread per ogni processo MPI. Per specificare, ad esempio, un processo MPI e quattro thread per NUMA, usare --map-by ppr:1:numa:pe=4. |
-report-bindings |
Stampa il mapping tra processi MPI e core, che risulta utile per verificare che l'aggiunta dei processi MPI sia corretta. |
$MPI_EXECUTABLE |
Specifica il collegamento creato dall'eseguibile MPI nelle librerie MPI. I wrapper del compilatore MPI eseguono questa operazione automaticamente. Ad esempio, mpicc o mpif90. |
Se si sospetta che l'applicazione MPI tightly coupled stia generando una quantità eccessiva di comunicazioni collettive, è possibile provare ad abilitare i collettivi gerarchici (HCOLL). Per abilitare tali funzionalità, usare i parametri seguenti:
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Argomenti di mpirun per Intel MPI
La versione Intel MPI 2019 è stata spostata dal framework Open Fabrics Alliance (OFA) al framework di Open Fabric Interfaces (OFI) e attualmente supporta libfabric. Sono disponibili due provider per il supporto InfiniBand: mlx e verbs. mlx è il provider preferito nelle macchine virtuali HB e HC.
Ecco alcuni argomenti di mpirun consigliati per Intel MPI 2019 update5+:
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
Negli argomenti seguenti:
| Parametri | Descrizione |
|---|---|
FI_PROVIDER |
Specifica il provider libfabric da usare, che influisce sull'API, sul protocollo e sulla rete usata. verbs è un'altra opzione valida, ma mlx offre in genere prestazioni migliori. |
I_MPI_DEBUG |
Specifica il livello di output di debug aggiuntivo, che può fornire informazioni dettagliate sulla posizione in cui vengono aggiunti i processi e su quale protocollo e rete vengono usati. |
I_MPI_PIN_DOMAIN |
Specifica il modo in cui si vogliono aggiungere i processi. È, ad esempio, possibile aggiungerli a core, socket o domini NUMA. In questo esempio la variabile di ambiente viene impostata su numa, il che significa che i processi verranno aggiunti ai domini del nodo NUMA. |
Sono disponibili altre opzioni che è possibile provare, soprattutto se le operazioni collettive utilizzano tempo notevole. Intel MPI 2019 update5+ supporta il provider mlx e usa il framework UCX per comunicare con InfiniBand. Supporta anche HCOLL.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
Argomenti di mpirun per MVAPICH
L'elenco seguente contiene alcuni argomenti consigliati di mpirun:
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
Negli argomenti seguenti:
| Parametri | Descrizione |
|---|---|
MV2_CPU_BINDING_POLICY |
Specifica i criteri di associazione da usare, che influiscono sull'aggiunta dei processi agli ID core. In questo caso, si specifica scatter, in modo tale che i processi vengano distribuiti uniformemente tra i domini NUMA. |
MV2_CPU_BINDING_LEVEL |
Specifica la posizione in cui aggiungere i processi. In questo caso, viene impostato su numanode, il che significa che i processi vengono aggiunti a unità di domini NUMA. |
MV2_SHOW_CPU_BINDING |
Specifica se si vogliono ottenere informazioni di debug sulla posizione in cui sono stati aggiunti i processi. |
MV2_SHOW_HCA_BINDING |
Specifica se si vogliono ottenere informazioni di debug sulla scheda del canale host usata da ogni processo. |