Considerazioni sull'aggiunta di processi
Perché aggiungere processi e thread?
Aggiungere sempre processi a core specifici per ottenere prestazioni ottimali e più costanti da un'esecuzione all'altra.
L'aggiunta di processi consente di:
Massimizzare la larghezza di banda della memoria inserendo o aggiungendo i processi in posizioni che usano tutti i canali di memoria e distribuiscono equamente tutti i canali di memoria tra i core.
Migliorare le prestazioni a virgola mobile garantendo che ogni processo si trovi nel proprio core. In questo modo si elimina la possibilità che due processi finiscano nello stesso core.
Ottimizzare lo spostamento dei dati tra i processi inserendo processi che comunicano in nodi di dominio NUMA (Non-Uniform Memory Access). In questo modo si garantisce abbiano la latenza minima e la larghezza di banda massima.
Ridurre il sovraccarico del sistema operativo e offre risultati più coerenti perché il sistema operativo non può spostare processi in core o domini NUMA diversi.
Dove è possibile aggiungere processi e thread?
Per determinare dove aggiungere processi e thread, è necessario comprendere la topologia di processori e memoria e, in particolare, il numero e la posizione dei domini NUMA.
L'utilità lstopo-no-graphics di hwloc RPM e Intel Memory Latency Checker (MLC) sono strumenti utili per determinare la topologia di processori e memoria. Ad esempio, quanti domini NUMA sono disponibili nella macchina virtuale? Quali core appartengono a ogni dominio NUMA? Qual è la latenza e la larghezza di banda per i processi in ogni dominio NUMA mentre comunicano tra loro?
L'immagine seguente mostra la mappa di latenza dei domini NUMA di HB120_v2 generata da Intel MLC. Più bassa è la latenza tra domini NUMA, più rapida è la comunicazione tra essi. La figura mostra chiaramente che per HB120_v2 sono disponibili 30 domini NUMA e indica quali domini NUMA sono presenti nei singoli socket. Mostra inoltre i domini NUMA possono essere raggruppati per ottenere valori minimi di latenza di trasferimento dei dati e delle comunicazioni.

I processori Intel hanno sei canali di memoria, mentre quelli AMD EPYC ne hanno otto. Assicurarsi di usare tutti i canali di memoria per massimizzare la larghezza di banda di memoria disponibile. A tale scopo, è possibile distribuire i processi in parallelo in modo uniforme tra i domini del nodo NUMA. Per le applicazioni ibride in parallelo, mantenere il raggruppamento di processi/thread negli stessi domini NUMA, condividendo, se possibile, la stessa cache L3. Assicurarsi che il conteggio totale dei thread non superi il numero totale di core.
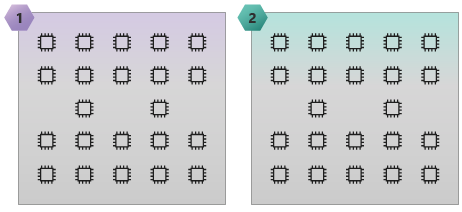
L'immagine seguente illustra uno SKU HC44 con due domini NUMA e 44 core.
L'immagine seguente illustra uno SKU HB60 con 15 domini NUMA e 60 core.
Applicazioni vincolate alla larghezza di banda della memoria
Se si ha un'applicazione vincolata alla larghezza di banda della memoria, è possibile migliorare le prestazioni della macchina virtuale riducendo il numero di thread e processi paralleli in ogni dominio del nodo NUMA. In questo modo si offrirà una maggiore larghezza di banda di memoria per ogni processo e possibilmente si ridurrà il tempo di clock totale di esecuzione.
Se, ad esempio, si usa lo SKU HB120_v2 con 30 domini del nodo NUMA, è possibile provare a eseguire uno, due e tre processi e thread per ogni dominio del nodo NUMA, ad esempio, 30, 60 e 90 processi e thread per ogni macchina virtuale. È quindi possibile individuare la configurazione che offre le prestazioni migliori.