Configurare l'archiviazione e i database
Spesso, una parte del processo di distribuzione richiede la connessione a database o servizi di archiviazione. Questa connessione potrebbe essere necessaria per applicare uno schema del database, aggiungere alcuni dati di riferimento a una tabella di database o caricare alcuni BLOB. Questa unità mostra come estendere il flusso di lavoro per usare i dati e i servizi di archiviazione.
Configurare i database da un flusso di lavoro
Molti database dispongono di schemi che rappresentano la struttura dei dati contenuti nel database. È spesso consigliabile applicare uno schema al database a partire dal flusso di lavoro di distribuzione, Questo permette di distribuire insieme tutti gli elementi necessari per la soluzione. Garantisce inoltre che, in caso si verifichi un problema quando viene applicato lo schema, il flusso di lavoro visualizzi un errore in modo da poter risolvere il problema ed eseguire una nuova distribuzione.
Quando si lavora con Azure SQL, è necessario applicare schemi di database connettendosi al server di database ed eseguendo comandi tramite script SQL. Questi comandi sono operazioni del piano dati. il flusso di lavoro deve eseguire l'autenticazione nel server di database e successivamente eseguire gli script. GitHub Actions offre l'azione azure/sql-action che può connettersi a un server di database SQL di Azure ed eseguire i comandi.
Non è necessario configurare altri dati e servizi di archiviazione usando un'API del piano dati. Ad esempio, quando si lavora con Azure Cosmos DB, i dati vengono archiviati in un contenitore. È possibile configurare i contenitori usando il piano di controllo, direttamente all'interno del file Bicep. Allo stesso modo, è anche possibile distribuire e gestire la maggior parte degli aspetti dei contenitori BLOB del servizio di archiviazione di Azure all'interno di Bicep. L'esercizio successivo illustra come creare un contenitore BLOB a partire da Bicep.
Aggiungere dati
Per funzionare in modo corretto, molte soluzioni richiedono l'aggiunta di dati di riferimento ai database o agli account di archiviazione. È possibile aggiungere tali dati ai flussi di lavoro, in modo che, dopo l'esecuzione del flusso di lavoro, l'ambiente sia completamente configurato e pronto per l'uso.
È anche utile disporre di dati di esempio nei database, in particolare per gli ambienti non di produzione. I dati di esempio consentono ai tester e ad altre persone che usano tali ambienti di testare immediatamente la soluzione. Questi dati possono includere prodotti di esempio o elementi come account utente falsi, da non aggiungere in genere all'ambiente di produzione.
L'approccio usato per aggiungere i dati dipende dal servizio in uso. Ad esempio:
- Per aggiungere i dati a un database SQL di Azure è necessario eseguire uno script, in modo analogo alla configurazione di uno schema.
- Per inserire i dati in Azure Cosmos DB, è necessario accedere all'API del piano dati, che potrebbe richiedere la scrittura di un codice script personalizzato.
- Per caricare i BLOB in un contenitore BLOB di Archiviazione di Azure è possibile usare diversi strumenti a partire dagli script del flusso di lavoro, tra cui l'applicazione da riga di comando AzCopy, Azure PowerShell o l'interfaccia della riga di comando di Azure. Ognuno di questi strumenti è in grado di eseguire l'autenticazione in Archiviazione di Azure per conto dell'utente e di connettersi all'API del piano dati per caricare i BLOB.
Idempotenza
Una delle caratteristiche dei flussi di lavoro di distribuzione e dell'infrastruttura come codice è la possibilità di eseguire ripetutamente la distribuzione, senza effetti collaterali negativi. Ad esempio, quando si ridistribuisce un file Bicep già distribuito in precedenza, Azure Resource Manager confronta il file inviato con lo stato attuale delle risorse di Azure. Se non sono presenti modifiche, non esegue alcuna operazione. La capacità di rieseguire un'operazione più volte è detta idempotenza. È consigliabile assicurarsi che gli script e altri passaggi del flusso di lavoro siano idempotenti.
L'idempotenza è particolarmente importante quando si interagisce con i servizi dati, perché mantengono lo stato. Si supponga di inserire un utente di esempio in una tabella di database dal flusso di lavoro. Se non si sta attenti, verrà creato un nuovo utente di esempio ogni volta che si esegue il flusso di lavoro. Si tratta probabilmente di un comportamento indesiderato.
Durante l'applicazione di schemi a un database SQL di Azure è possibile usare un pacchetto di dati, detto anche file del pacchetto di applicazione livello dati, per distribuire lo schema. Il flusso di lavoro compila un file del pacchetto di applicazione livello dati dal codice sorgente e crea un artefatto del flusso di lavoro, proprio come con un'applicazione. Durante il processo di distribuzione nel flusso di lavoro si pubblica quindi il file del pacchetto di applicazione livello dati nel database:
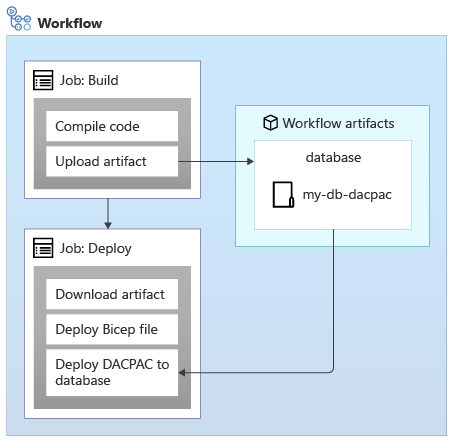
Durante la distribuzione, un file del pacchetto di applicazione livello dati si comporta in modo idempotente, confrontando lo stato di destinazione del database con lo stato definito nel pacchetto. In molte situazioni, ciò significa che non è necessario scrivere script che seguono il principio di idempotenza, perché gli strumenti sono in grado di gestirli autonomamente. Anche alcuni strumenti per Azure Cosmos DB e Archiviazione di Azure si comportano correttamente.
Tuttavia, quando si creano dati di esempio in un database SQL di Azure o in un altro servizio di archiviazione che non funziona automaticamente in modo idempotent, è consigliabile scrivere lo script in modo che crei i dati solo se non esistono già.
È anche importante valutare la necessità di eseguire il rollback delle distribuzioni, ad esempio eseguendo nuovamente una versione precedente di un flusso di lavoro di distribuzione. Il ripristino dello stato precedente dei dati può diventare complicato, quindi valutare attentamente il funzionamento della soluzione se è necessario consentirlo.
Sicurezza di rete
In alcuni casi, è possibile applicare restrizioni di rete ad alcune risorse di Azure. Queste restrizioni possono imporre regole sulle richieste effettuate al piano dati di una risorsa, ad esempio:
- Questo server di database è accessibile solo da un elenco specifico di indirizzi IP.
- Questo account di archiviazione è accessibile solo da risorse distribuite all'interno di una rete virtuale specifica.
Le restrizioni di rete sono comuni con i database, poiché potrebbe non essere necessario usare Internet per connettersi a un server di database.
Tuttavia, anche le restrizioni di rete possono rendere difficile il funzionamento dei flussi di lavoro di distribuzione con i piani dati delle risorse. Quando si usa uno strumento di esecuzione ospitato in GitHub, il relativo indirizzo IP non è facilmente noto in anticipo e potrebbe essere assegnato da un pool di indirizzi IP di grandi dimensioni. Inoltre, gli strumenti di esecuzione ospitati da GitHub non possono essere connessi alle proprie reti virtuali.
Alcune delle azioni che consentono di eseguire operazioni sul piano dati possono risolvere questi problemi. Ad esempio, l'azione azure/sql-action:
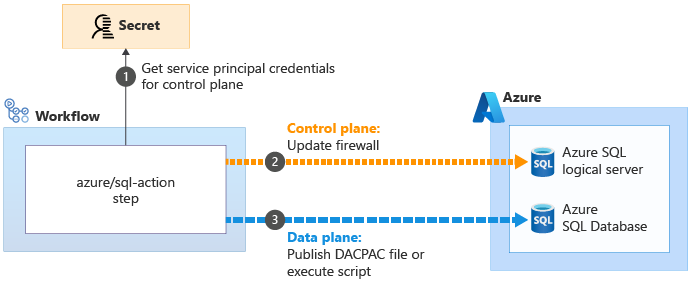
L'azione azure/sql-action impiegata per lavorare con un server logico o un database SQL di Azure usa l'identità del carico di lavoro per connettersi al piano di controllo per il server logico di Azure SQL. Aggiorna il firewall per consentire allo strumento di esecuzione di accedere al server dal relativo indirizzo IP
per connettersi al piano di controllo per il server logico di Azure SQL. Aggiorna il firewall per consentire allo strumento di esecuzione di accedere al server dal relativo indirizzo IP . In seguito, può inviare correttamente il file del pacchetto di applicazione livello dati o lo script da eseguire
. In seguito, può inviare correttamente il file del pacchetto di applicazione livello dati o lo script da eseguire . Al termine delle operazioni, l'azione rimuove automaticamente la regola del firewall.
. Al termine delle operazioni, l'azione rimuove automaticamente la regola del firewall.
In altre situazioni, non è possibile creare eccezioni di questo tipo. In questi casi, prendere in considerazione l'uso di uno strumento di esecuzione self-hosted, che viene eseguito su una macchina virtuale o su un'altra risorsa di calcolo controllata dall'utente. È quindi possibile configurare lo strumento di esecuzione nel modo desiderato, Può usare un indirizzo IP noto o connettersi alla rete virtuale personale. In questo modulo non vengono illustrati gli strumenti di esecuzione self-hosted ma vengono forniti collegamenti ad altre informazioni nella pagina Riepilogo del modulo.
Flusso di lavoro per la distribuzione
Nell'esercizio successivo si aggiornerà il flusso di lavoro di distribuzione per aggiungere nuovi processi e creare i componenti del database del sito Web, distribuire il database e aggiungere i dati iniziali:
