Introduzione
L'apprendimento automatico sta trasformando il modo in cui le aziende operano abilitando l'automazione e il processo decisionale basati sui dati. Tuttavia, lo sviluppo di un modello di apprendimento automatico è solo l'inizio. La vera sfida consiste nella distribuzione di tali modelli negli ambienti di produzione in cui possono fornire informazioni dettagliate e previsioni in tempo reale.
Azure Databricks è una piattaforma versatile che combina data science e ingegneria dei dati. Offre una piattaforma di analisi unificata che semplifica il processo di compilazione, training e distribuzione di modelli di apprendimento automatico su larga scala. Con il proprio ambiente collaborativo, gli scienziati e gli ingegneri dei dati possono collaborare per creare soluzioni di apprendimento automatico efficaci.
Per usare appieno le funzionalità di Azure Databricks, è essenziale comprendere l'intero flusso di lavoro di apprendimento automatico.
Esplorare il flusso di lavoro di apprendimento automatico
Il flusso di lavoro di apprendimento automatico è un processo completo che include diverse attività, ognuna delle quali ha un ruolo fondamentale per lo sviluppo e la distribuzione di modelli di apprendimento automatico efficaci. Il flusso di lavoro di apprendimento automatico include le attività seguenti:
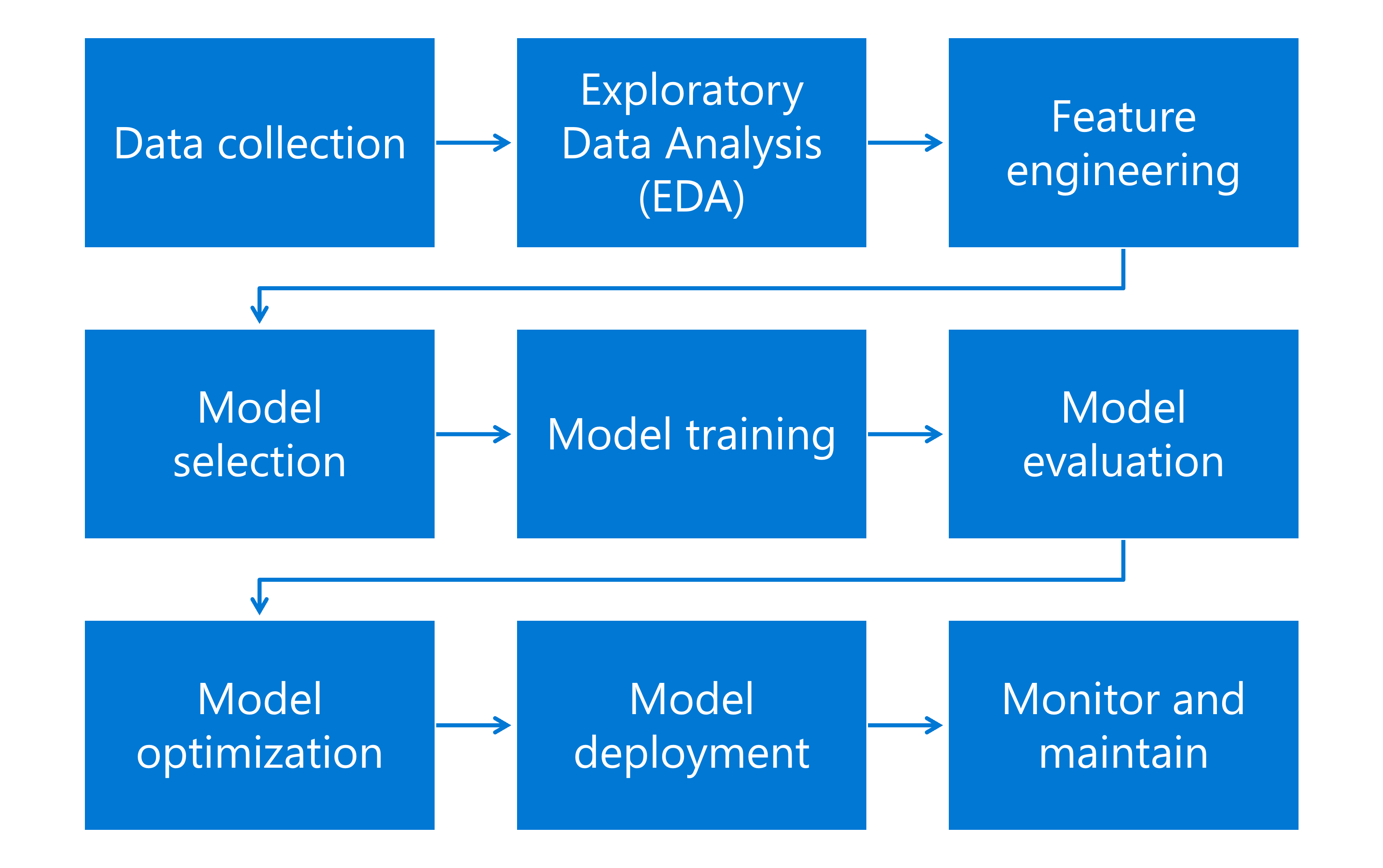
- Raccolta dei dati: i dati possono essere qualsiasi cosa, da numeri e immagini a testo, in base a ciò che deve essere appreso.
- Analisi esplorativa dei dati: analisi dei dati per riepilogarne le caratteristiche principali e individuare eventuali modelli.
- Ingegneria delle funzionalità: creazione di nuove funzionalità o modifica di quelle esistenti per migliorare le prestazioni dei modelli.
- Selezione del modello: il modello è una formula matematica o un algoritmo che esegue previsioni individuando modelli nei dati.
- Training dei modelli: L'algoritmo di apprendimento automatico usa i dati per apprendere i modelli che connettono l'input (funzionalità) all'output (destinazione). Il modello regola i parametri per ridurre al minimo la differenza tra le sue previsioni e i risultati effettivi nei dati di training.
- Valutazione del modello: le prestazioni del modello vengono valutate usando un nuovo set di dati denominato set di test. Le metriche come accuratezza, precisione, richiamo e l'area sotto la curva ROC vengono usate per valutare diversi tipi di modelli.
- Ottimizzazione del modello: i parametri e l'algoritmo del modello vengono ottimizzati per migliorarne l'accuratezza e l'efficienza.
- Distribuzione del modello: il modello viene distribuito in un ambiente di produzione in cui esegue previsioni in batch o in tempo reale.
- Monitoraggio e gestione: Il monitoraggio continuo è fondamentale per garantire che il modello rimanga efficace man mano che vengono aggiunti nuovi dati e si verificano potenziali cambiamenti nella distribuzione dei dati sottostante.
Per esplorare ogni fase del flusso di lavoro di apprendimento automatico e introdurre modelli nell'ambiente di produzione, è importante usare le tecnologie e gli strumenti appropriati. Azure Databricks, insieme ad altri servizi di Azure, offre un set di strumenti che supportano ogni passaggio di questo processo. Dalla raccolta dei dati all'ingegneria delle funzionalità e dalla distribuzione dei modelli al loro monitoraggio, Azure offre strumenti che consentono di semplificare l'integrazione utilizzando flussi di lavoro efficienti.
Verranno ora esaminati gli strumenti che consentono di introdurre i flussi di lavoro di apprendimento automatico nell'ambiente di produzione.