Alberi delle decisioni e architettura del modello
Quando si parla di architettura, spesso si pensa agli edifici. L'architettura è responsabile della struttura di un edificio, ad esempio l'altezza, la profondità, il numero di piani e il modo in cui gli elementi sono collegati internamente. Questa architettura determina anche come si usa un edificio, in pratica dove si entra e cosa è possibile "ottenere".
In Machine Learning l'architettura si riferisce a un concetto simile. Quanti parametri ha e come sono collegati tra loro per ottenere un calcolo? Calcoliamo molto in parallelo (larghezza) o abbiamo operazioni seriali che si basano su un calcolo precedente (profondità)? Come è possibile fornire input a questo modello e come si possono ricevere gli output? Tali decisioni architetturali in genere si applicano solo a modelli più complessi e le decisioni architetturali possono variare da semplici a complesse. Queste decisioni vengono in genere prese prima del training del modello, anche se in alcune circostanze è possibile apportare modifiche dopo il training.
Si esamini questo aspetto in modo più concreto con gli alberi delle decisioni come esempio.
Che cos'è un albero delle decisioni?
In sostanza, un albero delle decisioni è un diagramma di flusso. Gli alberi delle decisioni sono un modello di categorizzazione che suddivide le decisioni in più passaggi.
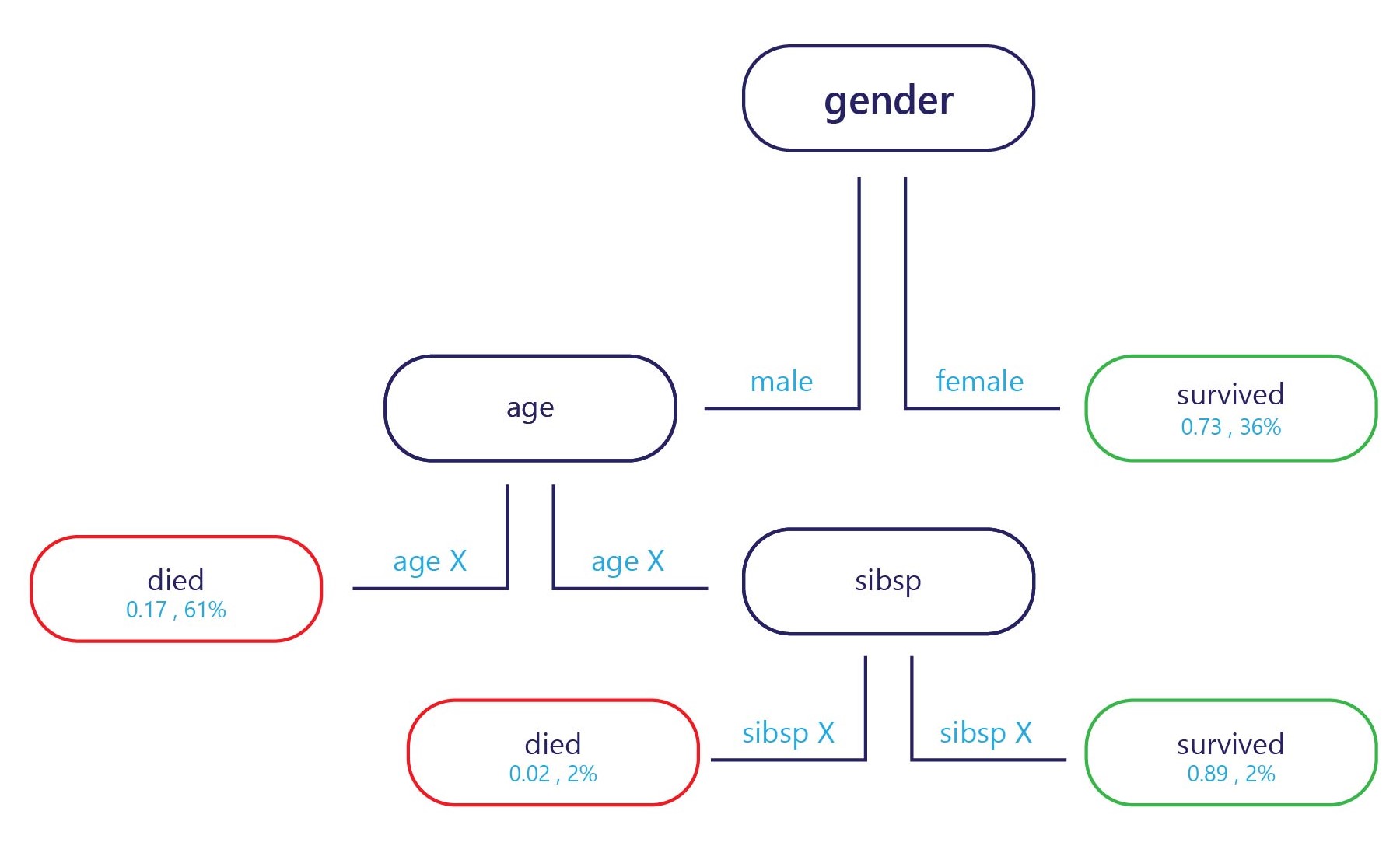
Il campione viene fornito nel punto di ingresso (in alto, nel diagramma sopra) e ogni punto di uscita ha un'etichetta (in basso nel diagramma). In ogni nodo, una semplice istruzione "if" decide a quale ramo passa il campione. Una volta che il ramo ha raggiunto la fine dell'albero (le foglie), gli viene assegnata un'etichetta.
Come viene eseguito il training degli alberi delle decisioni?
Il training degli alberi delle decisioni viene eseguito un nodo, o punto decisionale, alla volta. Nel primo nodo viene valutato l'intero set di training. Da qui viene selezionata una funzionalità che consente di separare al meglio il set in due subset con etichette più omogenee. Si supponga, ad esempio, che il set di training sia il seguente:
| Peso (caratteristica) | Età (caratteristica) | Ha vinto una medaglia (etichetta) |
|---|---|---|
| 90 | 18 | No |
| 80 | 20 | No |
| 70 | 19 | No |
| 70 | 25 | No |
| 60 | 18 | Sì |
| 80 | 28 | Sì |
| 85 | 26 | Sì |
| 90 | 25 | Sì |
Se volessimo individuare un criterio per suddividere questi dati, potremmo farlo in base all'età, fissando una soglia a 24 anni, dato che la maggior parte delle persone che hanno vinto una medaglia aveva più di 24 anni. Questa suddivisione fornirà due subset di dati.
Subset 1
| Peso (caratteristica) | Età (caratteristica) | Ha vinto una medaglia (etichetta) |
|---|---|---|
| 90 | 18 | No |
| 80 | 20 | No |
| 70 | 19 | No |
| 60 | 18 | Sì |
Subset 2
| Peso (caratteristica) | Età (caratteristica) | Ha vinto una medaglia (etichetta) |
|---|---|---|
| 70 | 25 | No |
| 80 | 28 | Sì |
| 85 | 26 | Sì |
| 90 | 25 | Sì |
Se ci fermiamo qui, abbiamo un modello semplice con un nodo e due foglie. La foglia 1 contiene i vincitori senza medaglie ed è accurata al 75% sul set di training. La foglia 2 contiene i vincitori di medaglie ed è anch'essa accurata al 75% sul set di training.
Tuttavia, non è necessario fermarsi qui. È possibile continuare questo processo suddividendo ulteriormente le foglie.
Nel subset 1, il primo nuovo nodo potrebbe essere suddiviso in base al peso, perché l'unico vincitore di medaglie ha un peso inferiore a quello delle persone che non hanno vinto medaglie. La regola potrebbe essere impostata su "peso < 65". Le persone con un peso inferiore a 65 kg tendono a vincere una medaglia, mentre quelle con un peso di 65 kg o superiore sembrano non soddisfare questo criterio e potrebbero quindi essere meno inclini a vincere una medaglia.
Nel subset 2, il secondo nuovo nodo potrebbe essere nuovamente segmentato in base al peso. In questo caso, si presume che coloro con un peso superiore a 70 kg avrebbero ottenuto una medaglia, mentre chi pesa meno di 70 kg non l'avrebbe vinta.
In questo modo verrà fornito un albero in grado di ottenere un'accuratezza del 100% sul set di training.
Punti di forza e punti deboli degli alberi delle decisioni
Gli alberi delle decisioni sono considerati a bassa distorsione. Ciò significa che in genere sono in grado di identificare le caratteristiche importanti per etichettare correttamente un elemento.
Il principale punto debole degli alberi delle decisioni è l'overfitting. Prendendo in considerazione l'esempio citato in precedenza, il modello offre un metodo preciso per calcolare chi ha maggiori probabilità di vincere una medaglia. Questo metodo consente di prevedere correttamente il risultato nel 100% dei casi del set di dati di training. Questo livello di accuratezza è insolito per i modelli di Machine Learning, che in genere causano numerosi errori nel set di dati di training. Le buone prestazioni di training non sono di per sé un aspetto negativo, ma l'albero è diventato così specializzato per il set di training che probabilmente non funzionerà bene per il set di test. Ciò si verifica perché l'albero potrebbe aver identificato delle relazioni nel set di training che, in realtà, potrebbero non essere valide, come l'idea che avere un peso di 60 kg assicuri una medaglia a chi ha meno di 25 anni.
L'architettura del modello influisce sull'overfitting
Il modo in cui viene strutturato l'albero delle decisioni è fondamentale per evitarne i punti deboli. Più è profondo l'albero, maggiore è la probabilità che si verifichi l'overfitting del set di training. Ad esempio, nell'albero semplice illustrato sopra, se l'albero fosse limitato solo al primo nodo, si verificherebbero errori nel set di training, ma probabilmente si otterrebbero risultati migliori nel set di test. In questo modo, l'albero adotterebbe criteri più generali per determinare chi vince le medaglie, ad esempio "atleti con età superiore ai 24 anni", evitando regole estremamente specifiche valide soltanto per il set di training.
Anche se in questo caso l'attenzione è incentrata sugli alberi, altri modelli complessi presentano vulnerabilità analoghe. Queste possono essere attenuate attraverso scelte appropriate riguardo alla loro strutturazione o al modo in cui vengono manipolati dal training.