Introduzione
Il linguaggio SQL
SQL è l'acronimo di Structured Query Language. Il linguaggio SQL viene usato per comunicare con i database relazionali. Le istruzioni SQL vengono usate per eseguire attività come l'aggiornamento dei dati in un database o il recupero dei dati da un database. Ad esempio, l'istruzione SQL SELECT viene usata per eseguire query sul database e restituire un set di righe di dati. Tra i sistemi di gestione di database relazionali comuni che usano SQL ci sono Microsoft SQL Server, MySQL, PostgreSQL, MariaDB e Oracle.
Esiste uno standard del linguaggio SQL definito dall'American National Standards Institute (ANSI). Ogni fornitore aggiunge le sue varianti ed estensioni.
Contenuto del modulo:
- Informazioni su SQL e come viene usato
- Identificare gli oggetti di database negli schemi
- Identificare i tipi di istruzioni SQL
- Usare l'istruzione SELECT per eseguire query nelle tabelle di un database
- Usare i tipi di dati
- Gestire i valori NULL
Transact-SQL
Le istruzioni SQL di base, ad esempio SELECT, INSERT, UPDATE e DELETE, sono disponibili indipendentemente dal sistema di database relazionale in uso. Sebbene queste istruzioni SQL facciano parte dello standard SQL ANSI, molti sistemi di gestione di database dispongono anche delle proprie estensioni. Queste estensioni forniscono funzionalità non coperte dallo standard SQL e includono aree come la gestione della sicurezza e la programmabilità. I sistemi di database di Microsoft come SQL Server, Database SQL di Azure, Microsoft Fabric e altri usano un dialetto di SQL denominato Transact-SQL o T-SQL. T-SQL include estensioni del linguaggio per la scrittura di stored procedure e funzioni, ovvero il codice dell'applicazione archiviato nel database, e per la gestione degli account utente.
SQL è un linguaggio dichiarativo
I linguaggi di programmazione possono essere classificati come procedurali o dichiarativi. I linguaggi procedurali consentono di definire una sequenza di istruzioni che il computer segue per eseguire un'attività. I linguaggi dichiarativi consentono di descrivere l'output desiderato lasciando al motore di esecuzione i dettagli dei passaggi necessari per produrre l'output.
SQL supporta parte della sintassi procedurale ma, in genere, per l'esecuzione di query sui dati con SQL viene usata la semantica dichiarativa. Si usa SQL per descrivere i risultati desiderati, mentre l'elaboratore di query del motore di database sviluppa un piano di query per recuperarli. L'elaboratore di query usa statistiche sui dati nel database e sugli indici definiti nelle tabelle per elaborare un buon piano di query.
Dati relazionali
SQL viene usato più di frequente (anche se non sempre) per eseguire query sui dati nei database relazionali. Un database relazionale è un database in cui i dati sono stati organizzati in più tabelle (tecnicamente definite relazioni), ognuna delle quali rappresenta un particolare tipo di entità, ad esempio un cliente, un prodotto o un ordine di vendita. Gli attributi di queste entità, ad esempio il nome di un cliente, il prezzo di un prodotto o la data di un ordine di vendita, sono definiti come colonne o attributi della tabella e ogni riga della tabella rappresenta un'istanza del tipo di entità, ad esempio un cliente, un prodotto o un ordine di vendita specifico.
Le tabelle nel database sono correlate tra loro attraverso colonne chiave che identificano in modo univoco l'entità specifica rappresentata. Per ogni tabella viene definita una chiave primaria. Un riferimento a questa chiave viene definito chiave esterna in qualsiasi tabella correlata. Questi dettagli sono più facilmente comprensibili osservando un esempio:
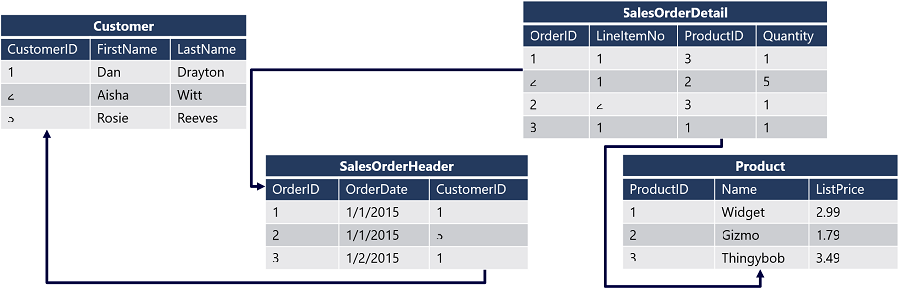
Il diagramma illustra un database relazionale che contiene quattro tabelle:
- Cliente
- SalesOrderHeader
- SalesOrderDetail
- Prodotto
Ogni cliente è identificato da un campo CustomerID univoco, che rappresenta la chiave primaria per la tabella Customer. La tabella SalesOrderHeader include una chiave primaria denominata OrderID per identificare ogni ordine e anche una chiave esterna CustomerID che fa riferimento alla chiave primaria nella tabella Customer per identificare il cliente associato a ogni ordine. I dati relativi ai singoli elementi in un ordine vengono archiviati nella tabella SalesOrderDetail, che include una chiave primaria composta che associa l'OrderID della tabella SalesOrderHeader a un valore LineItemNo. La combinazione di questi valori identifica in modo univoco una voce. Il campo OrderID viene anche usato come chiave esterna per indicare a quale ordine appartiene la voce, mentre il campo ProductID viene usato come chiave esterna per la chiave primaria ProductID della tabella Product per indicare il prodotto ordinato.
Elaborazione basata su set
La teoria dei set è uno dei fondamenti matematici del modello relazionale di gestione dei dati ed è essenziale per l'uso dei database relazionali. Sebbene sia possibile scrivere query in T-SQL senza una conoscenza approfondita dei set, in futuro potrebbe essere difficile scrivere alcuni dei tipi più complessi di istruzioni necessari per raggiungere prestazioni ottimali.
Senza addentrarsi nella matematica della teoria degli insiemi, si può pensare a un insieme come a "una raccolta di oggetti definiti e distinti considerati come un intero". In termini applicati ai database di SQL Server, si può pensare a un insieme come a una raccolta di oggetti distinti contenenti zero o più membri dello stesso tipo. Ad esempio, la tabella Customer rappresenta un set, in particolare il set di tutti i clienti. Si noterà che anche i risultati di un'istruzione SELECT formano un set.
Man mano che si approfondisce la conoscenza delle istruzioni di query T-SQL è importante tenere sempre presente l'intero set anziché i singoli membri. Questa mentalità aiuterà a migliorare la scrittura di codice basato su set, anziché considerare una sola riga alla volta. L'uso dei set richiede di pensare in termini di operazioni che si verificano "contemporaneamente" anziché una alla volta.
Una funzionalità importante da tenere presente per quanto riguarda la teoria dei set è che non esistono specifiche relative all'ordinamento dei membri di un set. Questa mancanza di ordine si applica alle tabelle di database relazionali. Non esiste un concetto di prima riga, seconda riga o ultima riga. È possibile accedere agli elementi (o recuperarli) in qualsiasi ordine. Se occorre che i risultati vengano restituiti in un determinato ordine, è necessario specificarlo in modo esplicito usando una clausola ORDER BY nella query SELECT.