Comprendere l'elaborazione di eventi
Analisi di flusso di Azure è un servizio per l'elaborazione di eventi complessi e l'analisi dei dati di streaming. Analisi di flusso viene usato per:
- Inserire dati da un input, ad esempio un hub eventi di Azure, un hub IoT di Azure o un contenitore BLOB di Archiviazione di Azure.
- Elaborare i dati usando una query per selezionare, proiettare e aggregare i valori dei dati.
- Scrivere i risultati in un output, ad esempio Azure Data Lake Gen 2, database SQL di Azure, Azure Synapse Analytics, Funzioni di Azure, hub eventi di Azure, Microsoft Power BI o altri.
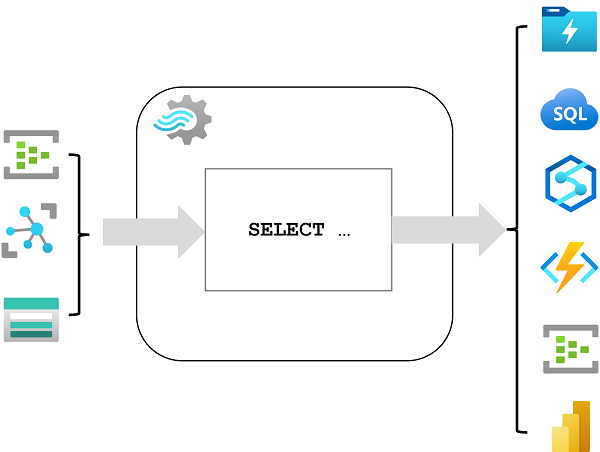
Una volta avviata, una query di Analisi di flusso verrà eseguita in modo perpetuo, elaborando i nuovi dati che arrivano nell'input e archiviando i risultati nell'output.
Analisi di flusso garantisce un'elaborazione degli eventi di tipo exactly-once e un recapito degli eventi di tipo at-least-once, in modo che gli eventi non vadano mai persi. Il servizio include funzionalità di ripristino predefinite in caso di errori di recapito degli eventi. Analisi di flusso offre anche checkpoint predefiniti per gestire lo stato del processo e produce risultati ripetibili. Poiché Analisi di flusso di Azure è un servizio PaaS, è completamente gestito e altamente affidabile. Grazie all'integrazione predefinita con diverse origini e destinazioni, insieme a un modello di programmazione flessibile, garantisce ai programmatori una maggiore produttività. Consentendo il calcolo in memoria, il motore di Analisi di flusso offre prestazioni superiori.
Processi e cluster di Analisi di flusso di Azure
Il modo più semplice per usare Analisi di flusso di Azure consiste nel creare un processo di Analisi di flusso in una sottoscrizione di Azure, configurarne gli input e gli output e definire la query che verrà usata dal processo per elaborare i dati. La query viene espressa usando la sintassi SQL (Structured Query Language) e può incorporare dati di riferimento statici da più origini dati per fornire valori di ricerca che possono essere combinati con i dati di streaming inseriti da un input.
Se i requisiti del processo di flusso sono complessi o a elevato utilizzo di risorse, è possibile creare un cluster di analisi di flusso, che usa lo stesso motore di elaborazione sottostante di un processo di Analisi di flusso, ma in un tenant dedicato (in modo che l'elaborazione non sia influenzata da altri clienti) e con scalabilità configurabile che consente di definire il giusto equilibrio tra velocità effettiva e costi per lo scenario specifico.
Input
Analisi di flusso di Azure può inserire dati dai tipi di input seguenti:
- Hub eventi di Azure
- Hub IoT Azure
- Archiviazione BLOB di Azure
- Azure Data Lake Storage Gen2
Gli input vengono generalmente usati per fare riferimento a un'origine di dati di streaming, che viene elaborata come nuovi record di eventi vengono aggiunti. È inoltre possibile definire input di riferimento usati per inserire dati statici per aumentare i dati di flusso eventi in tempo reale. Ad esempio, è possibile inserire un flusso di dati di osservazione meteo in tempo reale che includono un ID univoco per ogni stazione meteo e aumentare tali dati con un input di riferimento statico che corrisponde all'ID della stazione meteo a un nome più significativo.
Output
Gli output sono destinazioni a cui vengono inviati i risultati dell'elaborazione del flusso. Analisi di flusso di Azure supporta un'ampia gamma di output, che possono essere usati per:
- Rendere persistenti i risultati dell'elaborazione del flusso per ulteriori analisi; ad esempio caricandoli in un data lake o in un data warehouse.
- Visualizzare una visualizzazione in tempo reale del flusso di dati; ad esempio aggiungendo dati a un set di dati in Microsoft Power BI.
- Generare eventi filtrati o riepilogati per l'elaborazione downstream; ad esempio scrivendo i risultati dell'elaborazione del flusso in un hub eventi.
Query
La logica di elaborazione del flusso viene incapsulata in una query. Le query vengono definite usando istruzioni SQL che selezionano i campi dati DA uno o più input, filtrano o aggregano i dati e scrivono i risultati IN un output. La query seguente, ad esempio, filtra gli eventi dall'input degli eventi meteo per includere solo i dati degli eventi con un valore di temperatura inferiore a 0 e scrive i risultati nell'output a freddo:
SELECT observation_time, weather_station, temperature
INTO cold-temps
FROM weather-events TIMESTAMP BY observation_time
WHERE temperature < 0
Un campo denominato EventProcessedUtcTime viene creato automaticamente per definire l'ora in cui l'evento viene elaborato dalla query di Analisi di flusso di Azure. È possibile usare questo campo per determinare il timestamp dell'evento oppure specificare in modo esplicito un altro campo DateTime usando la clausola TIMESTAMP BY come illustrato in questo esempio. A seconda dell'input da cui vengono letti i dati di streaming, è possibile creare automaticamente uno o più campi timestamp potenziali; Ad esempio, quando si usa un input di Hub eventi, viene generato un campo denominato EventQueuedUtcTime per registrare l'ora in cui l'evento è stato ricevuto nella coda dell'hub eventi.
Il campo usato come timestamp è importante quando si aggregano i dati sulle finestre temporali, che vengono illustrate di seguito.