Come funziona Azure HDInsight
In questa unità si apprenderà come funziona Azure HDInsight. Verranno fornite informazioni sui componenti seguenti e su come interagiscono per fornire le funzionalità di controllo e gestione dei dati:
- Apache Hadoop
- Archiviazione di HDInsight
- Elaborazione di HDInsight
Che cos'è Apache Hadoop?
Apache Hadoop è un sistema di elaborazione dati distribuito nel cloud alla base di HDInsight. Include tre componenti, descritti nella tabella seguente:
| Componente di Apache Hadoop | Descrizione |
|---|---|
| HDFS | Il componente di Apache Hadoop HDFS (Hadoop Distributed File System) fornisce spazio di archiviazione per il sistema Hadoop. |
| YARN | Il componente di Apache Hadoop YARN (Yet Another Resource Negotiator) fornisce l'elaborazione per il sistema. |
| MapReduce | MapReduce è un modello di programmazione che consente di elaborare e analizzare i dati. |
Come interagiscono i componenti?
Il diagramma seguente illustra i componenti di archiviazione ed elaborazione che interagiscono in un tipico cluster Hadoop di HDInsight. Sono illustrati i componenti seguenti:
- Nodo head e nodi di lavoro, che si occupano dell'elaborazione.
- Più centri di archiviazione BLOB del servizio di archiviazione di Azure (WASB) di Windows, all'interno dei nodi. HDFS interagisce con questi contenitori.
- Più contenitori di archiviazione predefiniti, collegati e scollegati. Sono disponibili per i due nodi.
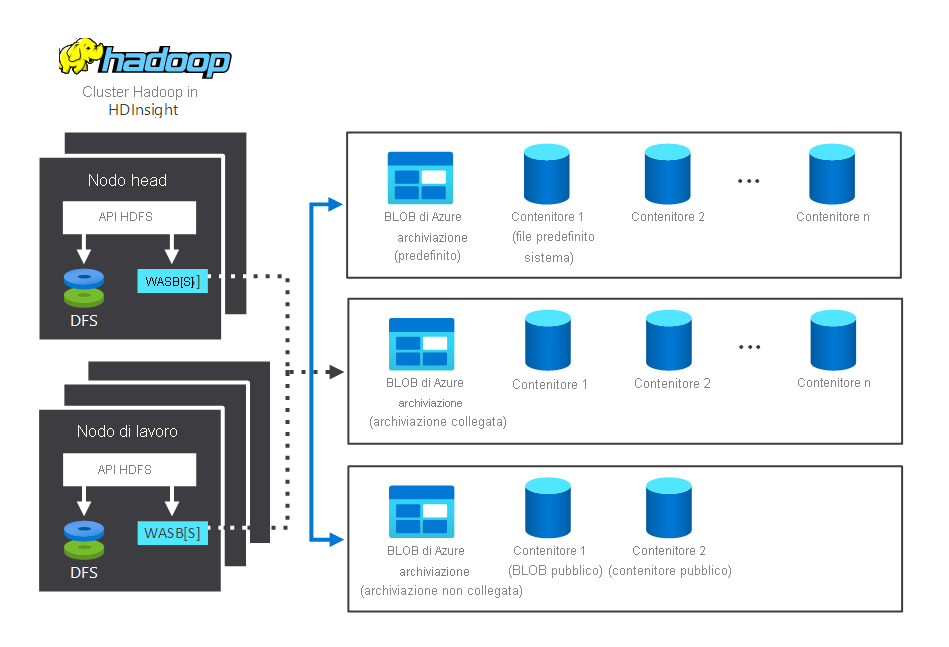
Si esaminerà ora il funzionamento dell'archiviazione e dell'elaborazione.
Come funziona l'archiviazione?
Il componente di archiviazione di un cluster non viene creato automaticamente quando si effettua il provisioning di un cluster HDInsight. Viene invece fornito da un sistema conforme a HDFS, ad esempio Archiviazione di Azure o Azure Data Lake.
La separazione del componente di archiviazione di un cluster dal componente di elaborazione offre alcuni vantaggi. Ad esempio, è possibile eliminare in modo sicuro tutti i cluster HDInsight usati solo per il calcolo senza doversi preoccupare di perdere i dati. Quando si aggiunge un cluster HDInsight, è necessario definire un file system predefinito.
Importante
Per l'archiviazione di Azure è necessario specificare un contenitore BLOB come file system predefinito.
L'impostazione di un file system predefinito garantisce che HDInsight possa risolvere i riferimenti a file relativi durante la ricerca di file.
Suggerimento
Quando si vuole aumentare lo spazio di archiviazione disponibile, è possibile collegare e scollegare ulteriori file system in base alle esigenze.

Come funziona l'elaborazione?
Quando si elaborano i dati, il componente di calcolo di un cluster Hadoop in HDInsight si suddivide in due aree logiche. La tabella seguente descrive queste due aree:
| Componente | Descrizione |
|---|---|
| Nodo head | Il nodo head accetta e gestisce le richieste client e le passa ai nodi di lavoro. |
| Nodo di lavoro | I nodi di lavoro elaborano i dati. |
Nota
Il nodo head viene talvolta definito nodo master.
La maggior parte dei cluster contiene due nodi head, tra cui:
- Nodo head attivo, che gestisce le connessioni client.
- Nodo head passivo, che offre resilienza nel caso in cui il nodo attivo sia offline.
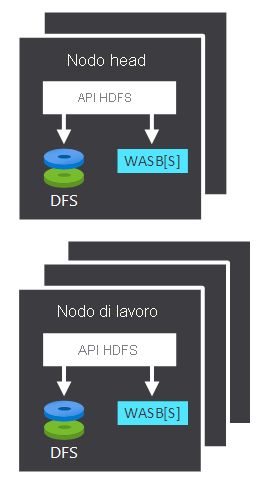
Sia il nodo head che i nodi di lavoro possono connettersi direttamente a un file system HDFS collegato in locale o accedere ai dati archiviati in Archiviazione BLOB di Azure o in Azure Data Lake. I dati che vengono gestiti dipendono da due fattori:
- Il modo in cui il modello di programmazione MapReduce ha definito come usare i dati
- La modalità di allocazione del lavoro da parte del nodo head
Qual è la funzione di YARN?
YARN si occupa della gestione delle risorse all'interno di un cluster HDInsight. Quando si elaborano i dati, questo servizio gestisce le risorse e la pianificazione dei processi.
YARN si colloca tra HDFS e il sistema di calcolo del cluster HDInsight. Collabora con il nodo head per distribuire un processo tra i nodi di lavoro del cluster. Ciò consente di garantire che i processi di elaborazione dati vengano eseguiti in parallelo.