Che cos'è Azure HDInsight?
Di seguito vengono presentati le funzionalità e gli usi di HDInsight. Questa panoramica consentirà di valutare se HDInsight è in grado di soddisfare i requisiti specifici dell'organizzazione.
What is big data? (Che cosa sono i Big Data?)
Il termine Big Data descrive gli enormi volumi di dati strutturati e non strutturati raccolti dall'organizzazione. Questi dati possono essere estremamente utili per le organizzazioni. In particolare, se un'organizzazione può analizzare i dati per ottenere informazioni dettagliate, ha più strumenti per migliorare i processi decisionali. Il risultato è che queste decisioni possono aiutare un'organizzazione a ottenere maggiore successo. Ad esempio, l'analisi di Big Data potrebbe consentire a un'organizzazione commerciale di conoscere meglio le abitudini dei clienti, con la possibilità di aumentare le vendite.
Definizione di Azure HDInsight
Azure HDInsight è un servizio di analisi open source basato sul cloud e completamente gestito destinato alle aziende. HDInsight consente di controllare e gestire i Big Data. HDInsight:
È una distribuzione cloud dei componenti di Hadoop.
Semplifica, velocizza e rende più conveniente l'elaborazione di enormi volumi di dati.
Supporta l'uso di framework open source, come:
- Hadoop
- Apache Spark
- Apache Hive
- Apache Kafka
Nota
Questi framework consentono di abilitare una vasta gamma di scenari, ad esempio l'estrazione, la trasformazione e il caricamento, il data warehousing, Machine Learning e Internet delle cose.
HDInsight offre diversi vantaggi per le organizzazioni che lavorano con Big Data, in particolare:
Open source: consente di creare cluster ottimizzati per vari framework open source.
Affidabilità: fornisce un contratto di servizio end-to-end per tutti i carichi di lavoro di produzione.
Scalabilità: consente di ridimensionare i carichi di lavoro per rispondere alle variazioni nella domanda.
Suggerimento
Creando cluster su richiesta, è possibile ridurre i costi. Si paga solo per le risorse usate.
Sicurezza: consente di proteggere gli asset di dati aziendali tramite l'integrazione con:
- Rete virtuale di Azure
- Tecnologie di crittografia di Azure
- Microsoft Entra ID
Conformità: soddisfa i più diffusi standard di conformità del settore e governativi.
Monitoraggio: si integra con i log di Monitoraggio di Azure per fornire una singola interfaccia. Consente di monitorare tutti i cluster usando una singola interfaccia.
Possibili usi di HDInsight per lavorare con i Big Data
È possibile usare HDInsight per molti scenari che usano l'elaborazione di Big Data. I dati possono essere:
- Dati cronologici: questi dati sono già stati raccolti e archiviati.
- Dati in tempo reale: questi dati vengono trasmessi direttamente dall'origine.
Le categorie seguenti riepilogano gli scenari di elaborazione per questi dati:
- Elaborazione batch
- Data warehousing
- IoT
- Data science
- Ibrido
Queste categorie verranno esaminate in maggiore dettaglio di seguito.
Elaborazione batch
Le organizzazioni usano processi di elaborazione batch per preparare i Big Data per ulteriori analisi. In genere, questo processo prevede tre fasi:
- Lettura di file di dati di origine da origini dati eterogenee.
- Elaborazione dei dati.
- Scrittura dei dati in un archivio scalabile.
Nota
Questo processo è spesso noto come ETL o estrazione, trasformazione e caricamento.
È possibile usare i dati trasformati per attività di data science o data warehousing.
Suggerimento
Un requisito significativo per ETL è la scalabilità orizzontale del calcolo, che consente l'elaborazione di volumi di dati di grandi dimensioni.
Data warehousing
Un data warehouse offre a un'organizzazione una posizione in cui archiviare i Big Data in attesa di analizzarli. Il data warehousing consente di:
- Archiviare i dati.
- Preparare i dati per l'analisi.
- Fornire i dati preparati in un formato strutturato. È quindi possibile eseguire query sui dati usando gli strumenti di analisi.
Il diagramma seguente illustra come Apache Hadoop in HDInsight raccoglie e archivia i dati da diverse origini. Apache Spark e Apache Hive preparano e analizzano i dati. Infine, i dati vengono modellati per l'uso con strumenti di business intelligence (BI). Per la visualizzazione dei dati viene usato Power BI.
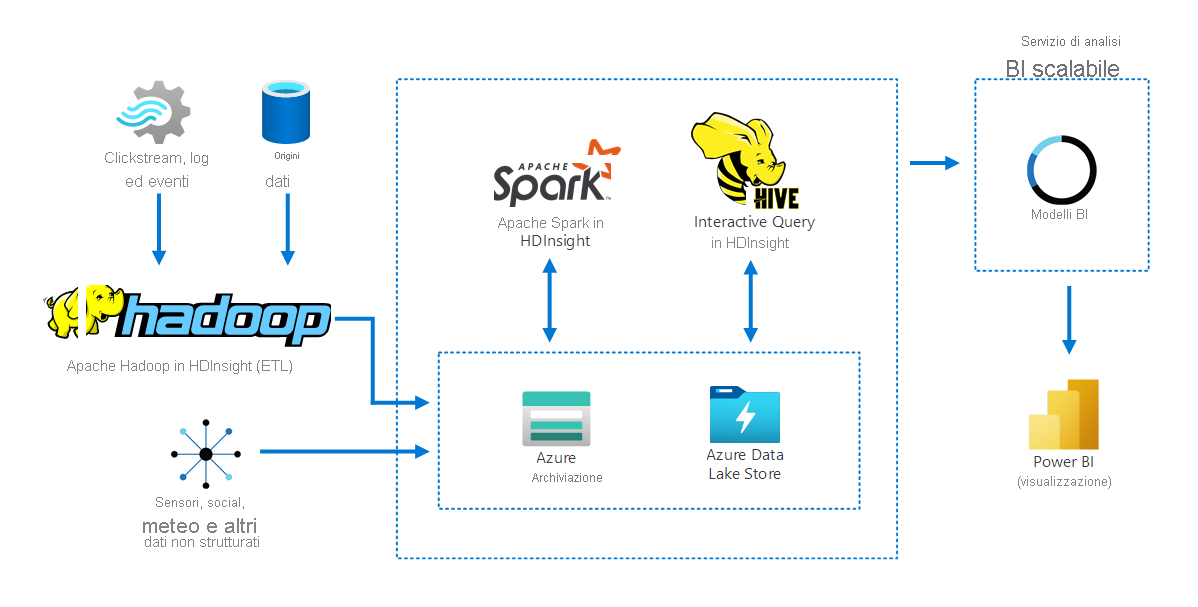
I componenti di questo scenario comprendono:
- Apache Spark è un framework di elaborazione parallela. Supporta l'elaborazione in memoria per migliorare le prestazioni delle applicazioni di analisi dei Big Data.
- Apache Hive in HDInsight è un sistema di data warehousing per Apache Hadoop. Hive consente il riepilogo, l'esecuzione di query e l'analisi dei dati. È possibile usare questi componenti per eseguire query nell'ordine di grandezza di petabyte su dati strutturati o non strutturati in qualsiasi formato.
Suggerimento
Le query Hive sono scritte in HiveQL, un linguaggio di query simile a SQL.
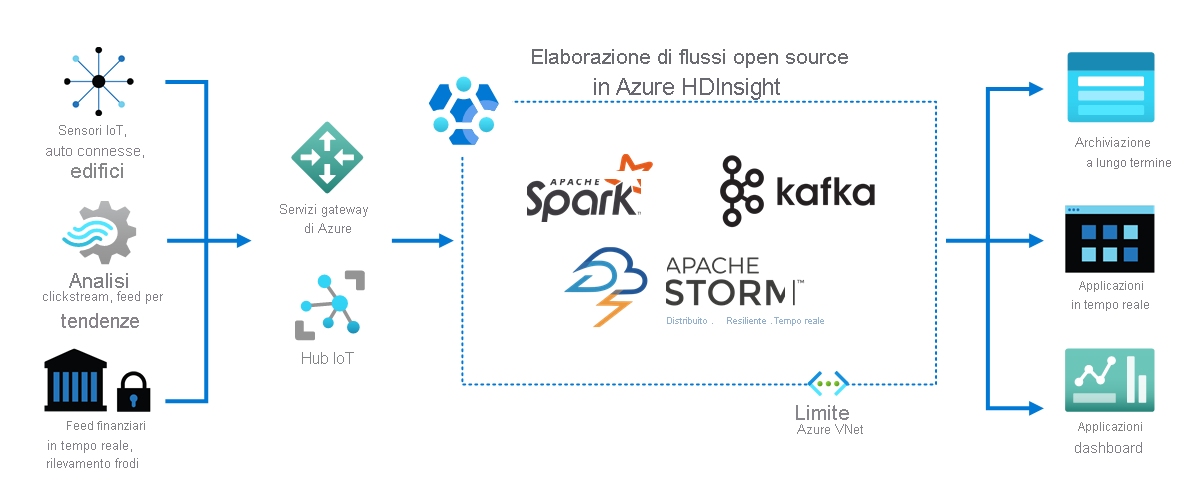
Internet delle cose
Come illustrato nel diagramma seguente, HDInsight elabora i flussi di dati ricevuti in tempo reale da dispositivi e sensori diversi. In questo esempio, diversi framework open source si occupano dell'elaborazione dei flussi, tra cui Apache Spark e Apache Kafka.
I servizi gateway di Azure e gli hub IoT indirizzano i dati a questi framework da diverse origini. I framework elaborano quindi i dati e li passano a:
- Archiviazione a lungo termine.
- App in tempo reale.
- Dashboard in tempo reale.
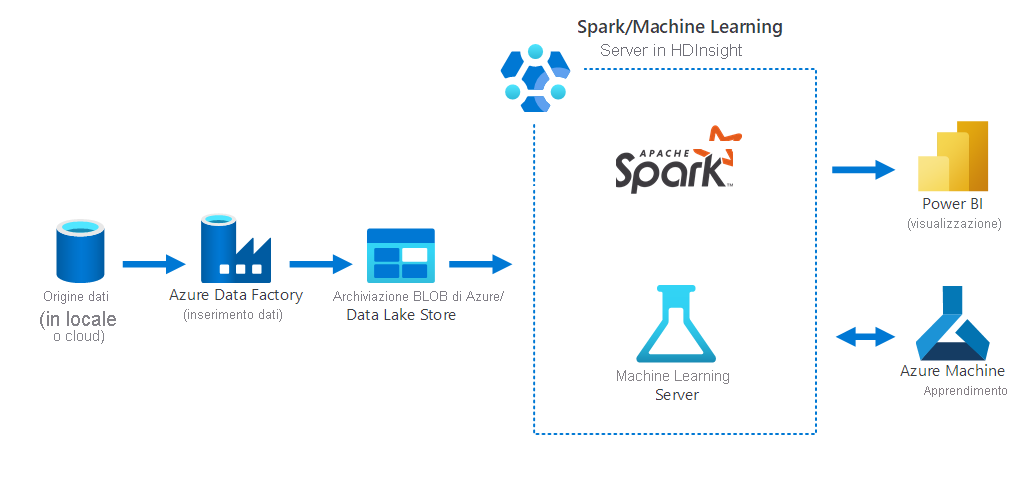
Data science
È possibile usare HDInsight per eseguire attività comuni di data science, ad esempio:
- Inserimento dati.
- Progettazione delle funzioni.
- Modellazione.
- Valutazione del modello.
Il diagramma seguente illustra uno scenario di data science in cui:
- I dati vengono raccolti da un'origine dati locale usando Azure Data Factory.
- I dati inseriti vengono quindi archiviati in un servizio di archiviazione di Azure (Archiviazione BLOB di Azure o Data Lake Store).
- Azure Spark in HDInsight elabora e prepara i dati per Azure Machine Learning. I dati vengono inoltre visualizzati con Power BI.
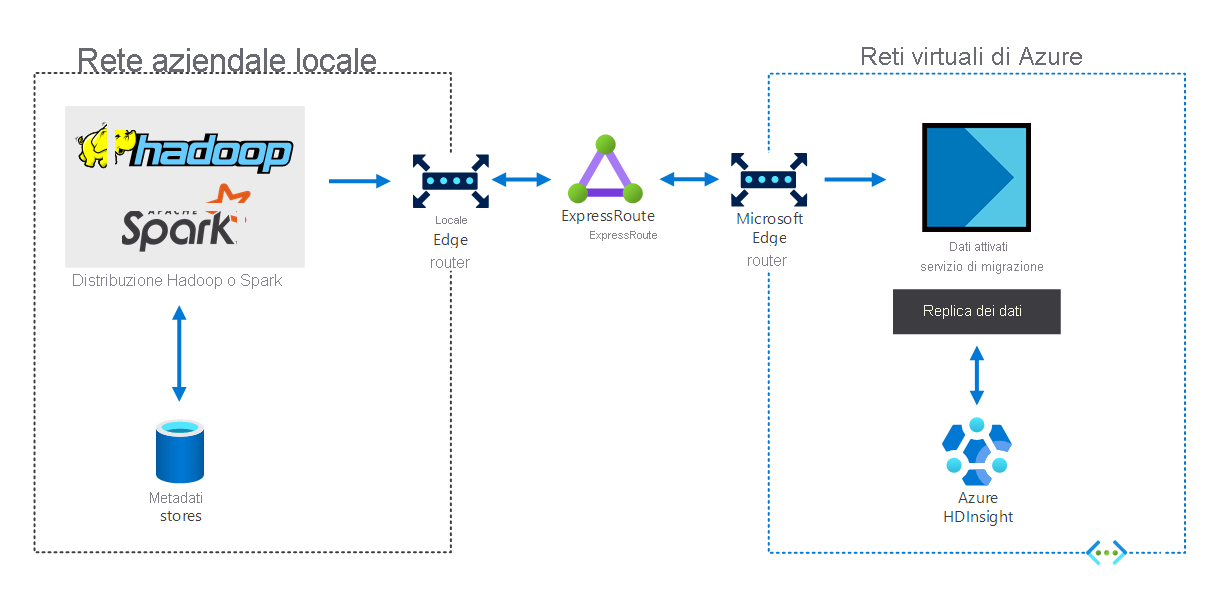
Ibrido
Le organizzazioni con un'infrastruttura Big Data locale possono usare HDInsight per estendersi in Azure. Si ottengono così i vantaggi delle funzionalità di analisi avanzate del cloud di Azure. Il diagramma seguente illustra lo scenario ibrido, in cui:
- L'infrastruttura Big Data locale è costituita da archivi di metadati e una distribuzione Hadoop o Spark nelle macchine virtuali locali.
- Un circuito Azure ExpressRoute connette l'ambiente di rete aziendale locale alle reti virtuali di Azure.
- Uno strumento di migrazione per i dati in tempo reale per Azure replica i dati ricevuti dall'ambiente locale in HDInsight.