Introduzione
Molte organizzazioni lavorano attualmente con i cosiddetti Big Data. L'enorme volume e varietà dei dati e la velocità con cui vengono generati rendono necessari sistemi per la gestione e il controllo di tali dati. In passato, le organizzazioni usavano sistemi di gestione di database relazionali per controllare i dati. Tuttavia, le organizzazioni vogliono ora usare le funzionalità del software open source in combinazione con i vantaggi delle piattaforme ospitate. Azure HDInsight è l'esempio perfetto di questo tipo di collaborazione. HDInsight consente di elaborare i Big Data in molti scenari, usando dati storici o in tempo reale.
La figura seguente illustra una panoramica dell'uso di HDInsight. Illustra diverse origini dati, tra cui sensori Internet delle cose (IoT), database e diversi archivi dati di Azure. HDInsight elabora i dati da queste posizioni, quindi li rende disponibili in risorse di archiviazione a lungo termine per le app in tempo reale e ulteriori analisi.
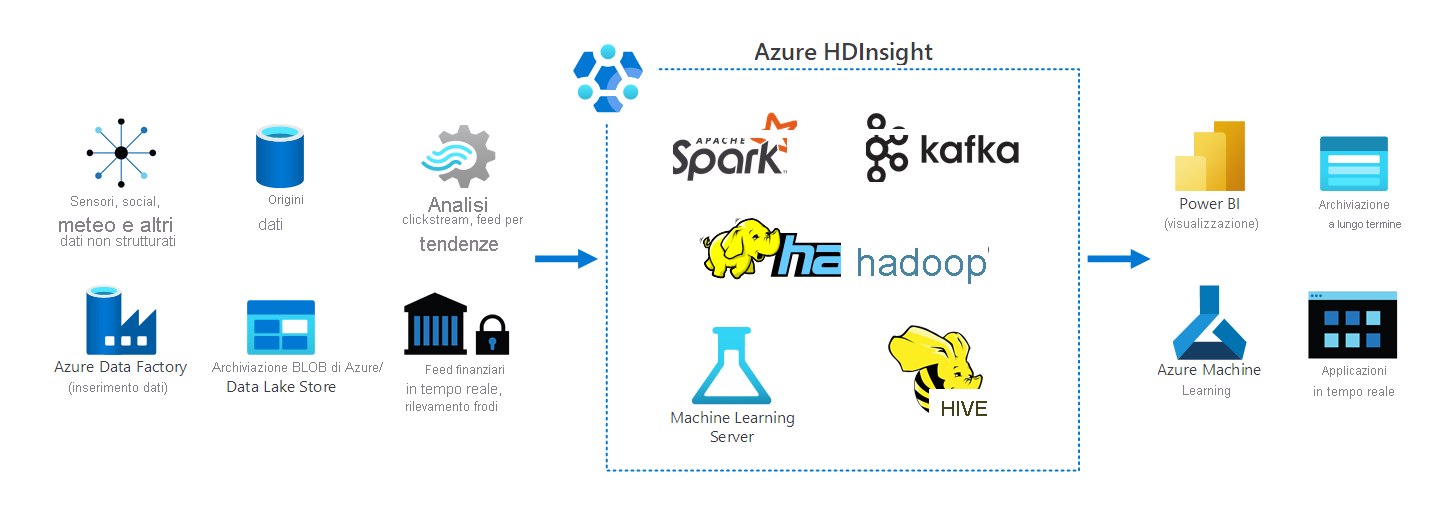
Scenario di esempio
Si supponga di lavorare per un'organizzazione che crea carichi di lavoro che inseriscono dati per la creazione di report cronologici e l'analisi avanzata. Potrebbe esserci anche l'esigenza di analizzare flussi di dati. In questi casi, potrebbe essere utile prendere in considerazione l'uso di HDInsight. Consente l'inserimento di tutti i dati in un'unica posizione di Data Lake. È quindi possibile usarlo per gestire i carichi di lavoro seguenti:
- Elaborazione batch
- Data warehousing
- Operazioni di data science
- Streaming
Cosa si fa?
Al termine di questo modulo si sarà in grado di valutare se HDInsight può essere utile all'organizzazione per l'elaborazione di Big Data. Si sarà anche in grado di descrivere in che modo HDInsight usa framework open source diffusi che supportano molti scenari per l'elaborazione dei dati.
Qual è l'obiettivo principale?
L'obiettivo principale è determinare se HDInsight è una scelta adatta ai requisiti specifici di elaborazione di Big Data.