Rendere scalabili le applicazioni
A questo punto, dopo aver appreso le nozioni di base relative alla preparazione alla crescita e i fattori da considerare nella pianificazione della capacità, è possibile affrontare il problema della maggiore scalabilità delle applicazioni.
Revisioni dell'architettura
Un aspetto importante da tenere presente è che bisogna eseguire regolarmente revisioni dell'architettura dei sistemi.
È noto che per migliorare il modo in cui si distribuiscono le risorse cloud si possono applicare pratiche come l'infrastructure as code. Il codice dell'applicazione deve essere aggiornato e migliorato regolarmente ed è necessario fare altrettanto con le risorse della piattaforma sottostanti.
Una revisione dell'architettura consente di identificare le aree che è necessario migliorare.
Il Centro architetture di Azure offre una vasta gamma di risorse per progettare applicazioni nel cloud, oltre a numerosi consigli sulla scalabilità, inclusi nella guida all'architettura delle applicazioni, disponibile al collegamento seguente:
Scenario: Architettura di Tailwind Traders
Il primo passaggio consiste nell'eseguire una valutazione dell'architettura e dell'applicazione, non solo per determinarne i punti deboli, ma anche per individuarne i punti di forza. Quali sono gli aspetti positivi?
Esaminare di nuovo lo scenario illustrato nell'unità precedente. Ecco di nuovo un diagramma dell'architettura dell'organizzazione.
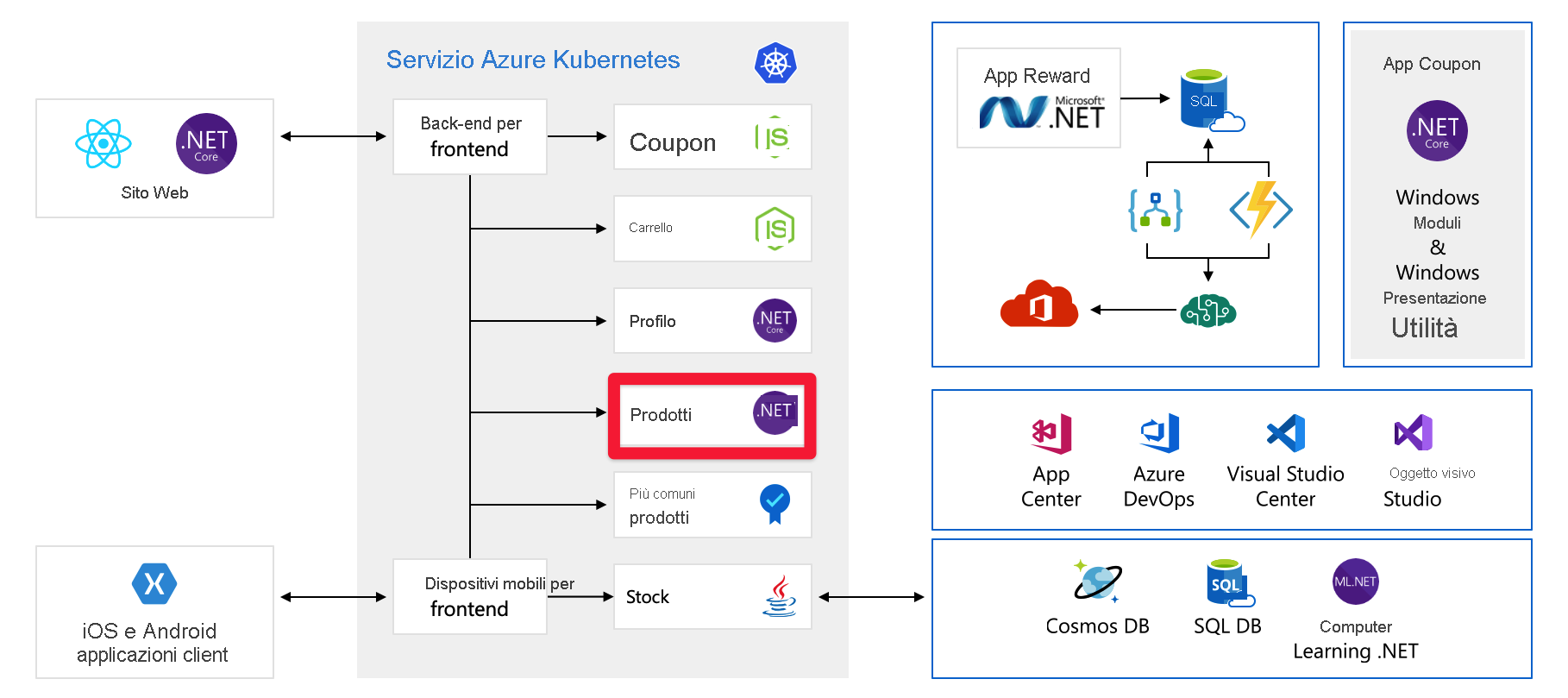
L'applicazione è stata scomposta in microservizi più piccoli e alcuni di questi servizi sono presenti come contenitori nel servizio Azure Kubernetes oppure possono essere in esecuzione in macchine virtuali o nel servizio app. Si usano alcuni servizi intrinsecamente scalabili, ad esempio Funzioni e App per la logica.
Questa modifica è efficace, ma c'è ancora spazio per alcuni miglioramenti che renderebbero l'applicazione più scalabile. Ad esempio, è possibile concentrarsi ora sul servizio Products (Prodotti). Nel diagramma, il servizio dei prodotti viene eseguito in Kubernetes, ma ai fini di questa spiegazione presupponiamo che sia in esecuzione in una macchina virtuale in Azure. I concetti di ridimensionamento, talvolta con un'implementazione leggermente diversa, possono essere adottati per le applicazioni, sia che vengano eseguite su server, nel servizio app o in contenitori.
Il servizio Products è attualmente in esecuzione in una singola macchina virtuale, connessa a una singola istanza del database SQL di Azure. È necessario abilitare questa macchina virtuale per aumentare il numero di istanze. A tale scopo, è possibile usare i set di scalabilità di macchine virtuali di Azure, che consentono di creare e gestire un gruppo di macchine virtuali identiche con bilanciamento del carico. Poiché ora si dispone di più di una macchina virtuale, è necessario introdurre un bilanciatore di carico per distribuire il traffico tra le macchine virtuali.
set di scalabilità di macchine virtuali
Applicando i set di scalabilità di macchine virtuali a singole macchine virtuali, si ottengono vari vantaggi:
- È possibile applicare la scalabilità automatica in base a metriche host, a metriche delle macchine virtuali guest, ai dati analitici delle applicazioni o in base a una pianificazione.
- È possibile usare le zone di disponibilità, ovvero data center autonomi indipendenti presenti all'interno di un'area di Azure. Grazie al supporto delle zone di disponibilità, è possibile distribuire le macchine virtuali in più zone di disponibilità, in modo da rendere l'applicazione più affidabile e proteggerla in caso di interruzioni nei data center. Le nuove istanze all'interno di un set di scalabilità sono distribuite automaticamente e in modo uniforme tra le zone di disponibilità.
- L'aggiunta di un servizio di bilanciamento del carico risulta semplificata. Con i set di scalabilità di macchine virtuali è possibile usare Azure Load Balancer per la distribuzione del traffico di livello 4 di base. Inoltre, supportano il gateway applicazione di Azure per la distribuzione del traffico di livello 7 più avanzata e la terminazione SSL.
Prima di implementare i set di scalabilità, è necessario prendere in considerazione alcuni fattori importanti. In particolare:
- Evitare l'assegnazione esclusiva delle istanze, in modo che nessun client sia vincolato a un back-end specifico.
- Rimuovere i dati persistenti dalla macchina virtuale e archiviarli altrove, ad esempio in Archiviazione di Azure o in un database.
- Progettare per la riduzione delle istanze. È anche importante che l'applicazione possa essere facilmente ridimensionata. Deve gestire normalmente non solo la presenza di più istanze aggiunte al pool di server che gestiscono il traffico, ma anche la chiusura improvvisa di istanze conseguente alla riduzione del carico. La riduzione della scalabilità è un aspetto spesso trascurato.
Disaccoppiamento
Sono state aggiunte altre macchine virtuali con i set di scalabilità. L'aumento delle risorse è la risposta tipica a un'esigenza di ridimensionamento. Tuttavia, questo approccio si basa su una singola metrica e potrebbe non essere adatto per tutte le attività eseguite dal servizio dei prodotti.
In questo scenario per il servizio Products è presente un processo Acquisisce un'immagine del prodotto e la carica. Codifica l’immagine e la archivia in una serie di dimensioni diverse per le anteprime, le immagini nel catalogo e così via. L'elaborazione delle immagini è un processo che richiede un elevato utilizzo della CPU, ma l'utilizzo generale richiede un elevato utilizzo della memoria.
L'elaborazione delle immagini è un'attività asincrona che può essere suddivisa in un processo in background. A questo scopo, è possibile disaccoppiare il servizio di elaborazione delle immagini tramite una coda. Il disaccoppiamento consente di ridimensionare in modo indipendente entrambi i servizi, uno in base alla memoria (il servizio prodotti) e l'altro (il servizio do elaborazione immagini) in base alla CPU o alla lunghezza della coda, e di definire un altro set di scalabilità che usa tali messaggi ed elabora le immagini.
Dimensionare con le code
Azure prevede due tipi di offerte per le code:
- Code del bus di servizio di Azure: un'offerta di accodamento più avanzata, parte integrante del vasto ecosistema di bus di servizio di Azure. Questa opzione offre funzionalità come pubblicazione/sottoscrizione e modelli di integrazione avanzati.
- Code di Archiviazione di Azure: un'interfaccia di accodamento semplice basata su REST e sviluppata su Archiviazione di Azure. e offre messaggistica affidabile e persistente.
I requisiti di questo scenario sono semplici ed è quindi possibile usare Code di Archiviazione di Azure. Non è necessario ridimensionare il livello di prodotto perché questa attività in background è stata disaccoppiata.
Memorizzazione nella cache in memoria
Un altro modo per migliorare le prestazioni dell'applicazione consiste nell'implementare una cache in memoria.
Ora sappiamo che le prestazioni non equivalgono esattamente alla scalabilità, ma migliorando le prestazioni dell'applicazione è possibile ridurre il carico su altre risorse. Questo miglioramento significa che potrebbe non essere necessario aumentare le risorse a breve.
La cache di Azure per Redis è un'offerta Redis gestita. È possibile usare Redis per diversi modelli e casi d'uso. Per il servizio dei prodotti di questo scenario, può essere utile implementare il modello cache-aside. In questo modello, gli elementi vengono caricati dal database nella cache secondo necessità, rendendo l'applicazione più efficiente e riducendo il carico sul database.
È anche possibile usare Redis come coda di messaggistica, per la memorizzazione nella cache del contenuto Web o per la memorizzazione nella cache delle sessioni utente. Questo tipo di memorizzazione nella cache può essere più adatto ad altri servizi del sistema, ad esempio il servizio carrello. In tale contesto, i dati del carrello per ogni sessione potrebbero essere conservati in Redis anziché utilizzare un cookie.
Dimensionare il database
Ora che le risorse di calcolo sono diventate più scalabili, passiamo a esaminare il database. In questo scenario si usa il database SQL di Azure, che è un'offerta di server SQL gestito di Azure.
I database relazionali sono più difficili da ridimensionare rispetto ai database non relazionali. Per dimensionare il database, è possibile inizialmente aumentare le dimensioni del database. Questo ridimensionamento può essere effettuato facilmente con un tempo di inattività medio non superiore ai quattro secondi. Usando una semplice chiamata API in Azure SQL o usando un dispositivo di scorrimento nel portale.
Se questo dimensionamento non soddisfa i requisiti, a seconda delle caratteristiche del traffico, potrebbe essere utile aumentare il numero di operazioni di lettura nel database. Questa operazione consentirà di instradare il traffico di lettura alla replica di lettura.
Nota
Con Azure SQL, la scalabilità in lettura è abilitata per impostazione predefinita se si usano i livelli Premium o Business Critical. Non è possibile abilitare questa funzionalità con i livelli Basic o Standard.
Questa modifica deve essere implementata nel codice. Ecco come fare.
#Azure SQL Connection String
#Master Connection String
ApplicationIntent=ReadWrite
#Read Replica Connection String
ApplicationIntent=ReadOnly
#Full Example
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadOnly;User ID=<myLogin>;Password=<myPassword>;Trusted_Connection=False; Encrypt=True;
Aggiornare l'attributo ApplicationIntent nella stringa di connessione di database per specificare il server a cui connettersi. Usare ReadOnly per connettersi alla replica o ReadWrite per connettersi al nodo master.
Dal momento che questo comando deve essere implementato nel codice, potrebbe non essere una soluzione appropriata per la situazione specifica. Che cosa accade se ogni singolo servizio dei prodotti deve poter eseguire operazioni di lettura e scrittura?
In questo caso è possibile provare ad aumentare le risorse del database SQL tramite il partizionamento orizzontale.
Partizionamento orizzontale dei database
Se dopo il ridimensionamento o l'implementazione delle repliche in lettura, le risorse del database non soddisfano ancora le esigenze del sistema, è l'opzione successiva è il partizionamento orizzontale.
Il partizionamento orizzontale è una tecnica che consente di distribuire grandi quantità di dati strutturati in modo identico tra più database indipendenti. Il partizionamento orizzontale può essere necessario per diversi motivi. Ad esempio:
- La quantità totale di dati è eccessiva e supera i vincoli di un singolo database.
- La velocità effettiva delle transazioni del carico di lavoro complessivo supera le capacità di un singolo database.
- Per motivi di conformità è necessario che i tenant distinti si trovino in database fisici diversi (questo requisito è meno attinente al dimensionamento, ma si tratta di un'altra situazione in cui si usa il partizionamento orizzontale).
L'applicazione aggiunge i dati pertinenti alla partizione opportuna e quindi renderà il sistema scalabile superando i vincoli del singolo database.
In SQL di Azure sono disponibili gli strumenti per database elastico di Azure. Questi strumenti consentono di creare, gestire ed eseguire query su database SQL partizionati in Azure dalla logica dell'applicazione.