Indicatori del livello di servizio (SLI) e obiettivi del livello di servizio (SLO)
Finora in questo modulo è stato illustrato come aumentare la consapevolezza operativa e approfondire la conoscenza dell'affidabilità in una determinata ottica. Sono stati inoltre descritti gli strumenti di Monitoraggio di Azure necessari per svolgere il lavoro. A questo punto, è possibile esplorare una delle idee più importanti in questo modulo e i processi per implementarla.
Risponderemo alla domanda: "Come posso usare tutto questo per migliorare l'affidabilità nell'organizzazione?"
Entrare nel ciclo di feedback
Ecco la grande idea che può risolvere il problema per noi:
I cicli di feedback corretti migliorano l'affidabilità nell'organizzazione.
Il miglioramento dell'affidabilità nell'organizzazione è un processo iterativo. In questa unità verrà esaminata una procedura molto efficace del mondo Site Reliability Engineering per creare e alimentare in un'organizzazione un tipo di ciclo di feedback che consenta di migliorare l'affidabilità. Quanto meno, consentirà di dare vita nell'organizzazione a discussioni concrete sull'affidabilità, basate su dati oggettivi.
Più indietro in questo modulo abbiamo fornito la seguente definizione di Site Reliability Engineering:
Site Reliability Engineering è una disciplina di progettazione dedicata ad aiutare le organizzazioni a raggiungere in modo sostenibile il livello di affidabilità appropriato nei propri sistemi, servizi e prodotti.
Ecco dove entra in gioco il concetto di livello di affidabilità appropriato.
Indicatori del livello di servizio (SLI)
Gli indicatori del livello di servizio (SLI, Service Level Indicator) sono connessi alla precedente discussione sull'ampliamento della conoscenza dell'affidabilità. Probabilmente si ricorderà questo diagramma.
Gli indicatori SLI rappresentano il tentativo di specificare come verrà misurata l'affidabilità del sistema. Qual è l'indicatore che mostra il comportamento affidabile di un servizio (in conformità alle aspettative)? Che cosa possiamo misurare per rispondere a questa domanda?
Esempio: disponibilità e latenza del server Web
Supponiamo di lavorare con un server Web e la relativa disponibilità. Potremmo essere interessati al numero di richieste HTTP ricevute e al numero di richieste HTTP a cui ha risposto correttamente. Più precisamente, vogliamo capire quanto efficacemente il sistema ha assolto al proprio ruolo di server Web, comprendendo il rapporto tra le richieste riuscite e il totale delle richieste.
Dividendo il numero di richieste totali per il numero di richieste riuscite, otteniamo un rapporto. È possibile moltiplicare questo rapporto per 100 per ottenere una percentuale. Per fare un esempio, se il server Web ha ricevuto 100 richieste e ha risposto correttamente a 80, il rapporto è 0,8. Moltiplicando per 100 questo valore, possiamo dire che il livello di disponibilità è stato dell'80%.
Vediamo un altro esempio. Questa volta specifichiamo una misura associata alla latenza del servizio Web. Potremmo essere interessati a conoscere il rapporto tra il numero di operazioni completate in meno di 10 millisecondi rispetto al numero totale di operazioni. Eseguendo la stessa operazione matematica, ovvero 100 richieste totali divise per 80 richieste che hanno restituito un risultato più velocemente rispetto alla soglia, calcoliamo di nuovo un rapporto di 0,8. Moltiplicando per 100, anche in questo caso possiamo dire che siamo riusciti a soddisfare all'80% i requisiti di latenza in base a questa misurazione.
Solo per essere chiari: questo non è un aspetto che riguarda solo i siti Web. Se si disponesse di un servizio pipeline per l'elaborazione dei dati, si potrebbe voler misurare la copertura (ad esempio, la quantità di dati che sono stati elaborati). Il sistema è molto diverso, ma i calcoli matematici di base sono molto simili.
Indicatori SLI: dove misurare
Affinché gli indicatori SLI risultino utili in discussioni concrete basate su dati oggettivi, è necessario specificare un altro elemento oltre a ciò che intendiamo misurare. Quando si crea un indicatore SLI, è necessario tenere presente non solo ciò che è stato misurato, ma anche dove è stata eseguita la misurazione.
Ad esempio, quando abbiamo specificato di voler misurare la disponibilità del server Web indicato in precedenza, non abbiamo detto da dove abbiamo recuperato i dati sulle richieste HTTP riuscite e totali. Se, nel corso di una discussione sull'affidabilità del server Web, si esaminano le statistiche sulle richieste raccolte da un servizio di bilanciamento del carico davanti al server, mentre i colleghi analizzano le statistiche registrate dal server stesso, la discussione potrebbe non essere molto produttiva. I dati potrebbero essere radicalmente diversi perché il servizio di bilanciamento del carico potrebbe registrare tutte le richieste in arrivo nella rete, ma se si è verificato un problema con la rete o con il servizio di bilanciamento del carico stesso, non tutte le richieste potrebbero raggiungere il server. Verrebbero tratte conclusioni basate su due set di dati diversi.
Il modo più semplice per risolvere questo problema è definire in modo specifico l'origine dati nell'indicatore SLI. Per il server Web, per la disponibilità specificheremo "il rapporto tra le richieste riuscite e il totale delle richieste, misurate dal servizio di bilanciamento del carico". Per la latenza, specificheremo qualcosa come "il rapporto tra il numero di operazioni completate in meno di 10 millisecondi rispetto al numero totale di operazioni, misurate sul client".
Questo conduce alla domanda logica seguente: qual è il posto migliore per la misurazione degli indicatori SLI? Sfortunatamente, non esiste una risposta "esatta" a livello universale. Si tratta di una decisione che è necessario prendere con la consapevolezza che vi sono compromessi in entrambi i casi. Una delle indicazioni che possiamo offrire ci riporta alla nostra precedente discussione sull'affidabilità: provare a misurare gli elementi nella posizione che rispecchia in modo più accurato l'esperienza del cliente.
Obiettivi del livello di servizio (SLO)
Decidere cosa misurare (e dove) è un ottimo inizio, ma ci conduce solo a metà strada rispetto all'obiettivo. Supponiamo di recuperare le metriche necessarie per l'indicatore SLI relativo alla disponibilità del server Web e che risulti effettivamente una disponibilità dell'80%.
Si tratta di un aspetto positivo o negativo? È il "livello di affidabilità appropriato?"
Per rispondere a queste domande, è necessario definire un obiettivo per l'indicatore SLI: un obiettivo del livello di servizio (SLO, Service Level Objective). Questo obiettivo definirà chiaramente l'obiettivo del servizio.
Fondamentalmente, gli elementi per la creazione di un obiettivo SLO sono i seguenti:
L'elemento da misurare: il numero di richieste, controlli di archiviazione e operazioni, ovvero cosa misurare.
La proporzione desiderata: ad esempio, "operazioni riuscite per il 50% del tempo," "capacità di eseguire la lettura per il 99,9% del tempo", "restituzione di un risultato in 10 ms per il 90% del tempo".
L'orizzonte temporale: il periodo di tempo da prendere in considerazione per l'obiettivo (gli ultimi 10 minuti, l'ultimo trimestre, in una finestra di 30 giorni e così via). Gli obiettivi SLO spesso vengono specificati utilizzando una finestra mobile rispetto a un'unità di calendario come "un mese" per consentire di confrontare i dati relativi a periodi diversi.
Riunendo questi componenti e includendo le informazioni importanti sul dove, un obiettivo SLO di esempio potrebbe essere simile al seguente:
Il 90% delle richieste HTTP segnalate dal servizio di bilanciamento del carico ha avuto esito positivo negli ultimi 30 giorni.
Analogamente, un obiettivo SLO di base che misura la latenza potrebbe essere simile al seguente:
Per il 90% delle richieste HTTP segnalate dal client è stato restituito un risultato in meno di <20 ms negli ultimi 30 giorni.
Iniziare con semplici obiettivi SLO di base come questi al momento di introdurre la procedura nell'organizzazione. Se necessario, sarà possibile creare obiettivi SLO più complessi in un secondo momento.
Indicatori SLI e obiettivi SLO in Monitoraggio di Azure
Come parte finale di questa unità, vediamo come è possibile rappresentare un semplice indicatore SLI o obiettivo SLO in Monitoraggio di Azure tramite Log Analytics. Per assicurare la coerenza, torniamo all'esempio del server Web.
Nell'ultima unità è stato specificato che è possibile creare query in Log Analytics usando il linguaggio di query Kusto (KQL). Di seguito è riportata una query KQL che visualizza un indicatore SLI della disponibilità per un servizio Web:
requests
| where timestamp > ago(30d)
| summarize succeed = count (success == true), failed = count (success == false), total = count() by bin(timestamp, 5m)
| extend SLI = succeed * 100.00 / total
| project SLI, timestamp
| render timechart
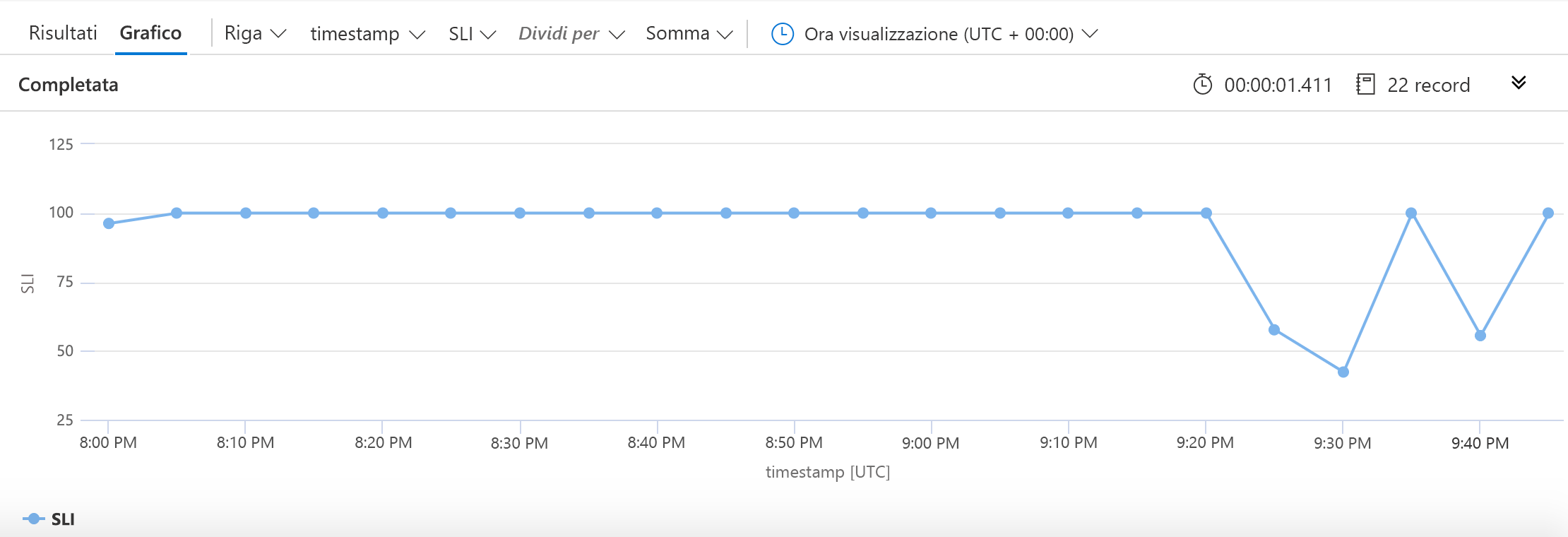
Come in precedenza, per iniziare specifichiamo l'origine dei dati, ovvero la tabella requests. Limitiamo quindi i dati da elaborare alle informazioni degli ultimi 30 giorni. Raccogliamo quindi (in bucket di 5 minuti) il numero di richieste riuscite, il numero di richieste non riuscite e il numero totale di richieste. L'indicatore SLI viene creato usando i semplici calcoli aritmetici descritti in precedenza. Comunichiamo a KQL l'intenzione di tracciare l'indicatore SLI insieme ai timestamp e quindi creare un grafico simile al seguente:
A questo punto, è possibile sovrapporre una semplice rappresentazione di un obiettivo SLO:
requests
| where timestamp > ago(5h)
| summarize succeed = count (success == true), failed = count (success == false), total = count() by bin(timestamp, 5m)
| extend SLI = succeed * 100.00 / total
| extend SLO = 80.0
| project SLI, timestamp, SLO
| render timechart
Sono cambiate due righe in questo esempio rispetto a quello precedente. La prima definisce il numero che verrà usato per l'obiettivo SLO, la seconda indica a KQL che l'obiettivo SLO deve essere incluso nel grafico. Il risultato è simile al seguente:
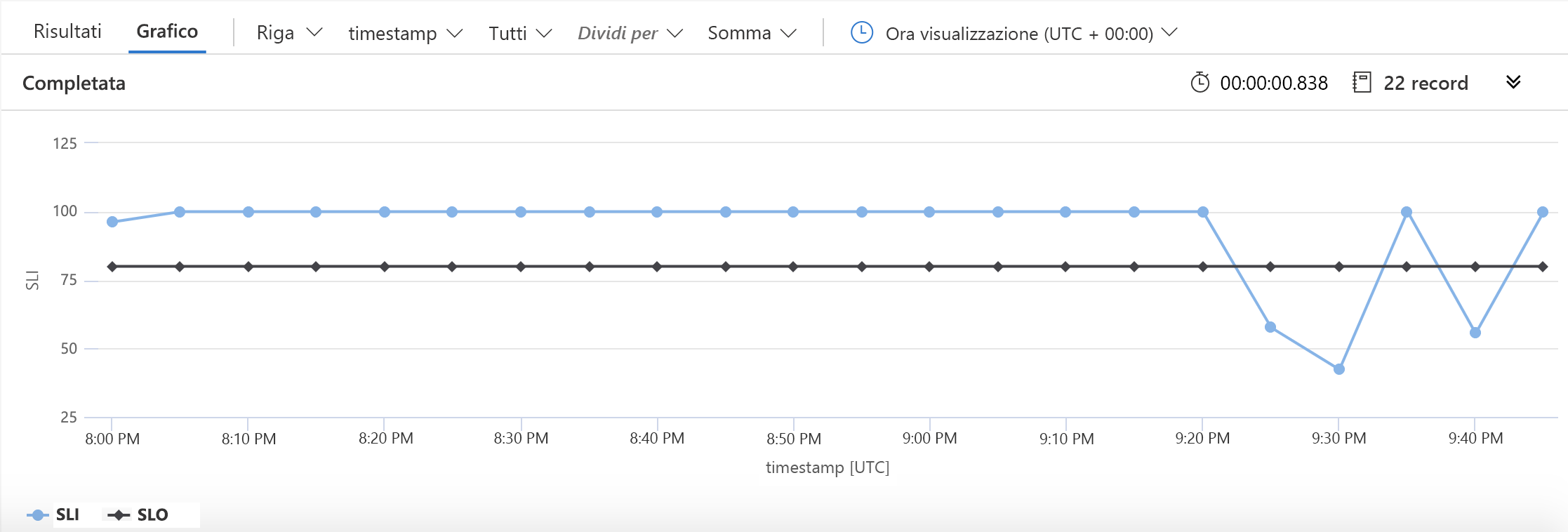
In questo grafico è facile vedere il momento in cui siamo scesi al di sotto dell'obiettivo per la disponibilità.
Uso di indicatori SLI e obiettivi SLO
Invariabilmente ci sono alcune ottimizzazioni da apportare agli indicatori SLI e agli obiettivi SLO (dopo tutto, si tratta di un processo iterativo). Una volta completata questa operazione, cosa è possibile fare con le informazioni?
Innanzitutto, probabilmente si noterà che la creazione degli indicatori SLI e degli obiettivi SLO avrà effetti positivi sull'organizzazione. Richiede discussioni con gli stakeholder e altre comunicazioni che contribuiscono a impostare gli elementi in una direzione corretta. Allo stesso modo, anche il successivo ciclo di discussioni sulle operazioni da eseguire con i dati ottenuti può essere utile.
Infine, indicatori SLI e obiettivi SLO sono strumenti di pianificazione del lavoro. Possono aiutarti a prendere decisioni di progettazione come "dovremmo lavorare sulle nuove funzionalità per il servizio o dovremmo concentrarci sul lavoro di affidabilità?" Possono essere utili per il tipo di cicli di feedback descritti in precedenza.
Un uso secondario ma piuttosto comune per indicatori SLI e obiettivi SLO è come parte di un sistema di monitoraggio/risposta più immediato. Oltre all'aspetto relativo alla pianificazione del lavoro (su cui è necessario concentrarsi inizialmente), molte persone usano questi elementi come segnali operativi. Ad esempio, potrebbero scegliere di avvisare il personale se il servizio scende al di sotto dell'obiettivo SLO per un periodo di tempo prolungato. Questo tipo di avviso ci conduce alla prossima unità di questo modulo.