Gerarchia dei livelli di affidabilità di Dickerson
La mappa per il percorso di apprendimento Migliorare l'affidabilità si basa su un modello proveniente dal mondo SRE (Site Reliability Engineering), la cosiddetta gerarchia dei livelli di affidabilità di Dickerson. Mikey Dickerson, professionista SRE e amministratore fondatore di United States Digital Service, ha creato questa gerarchia mentre affrontava una delle crisi di affidabilità più gravi che avesse mai incontrato.
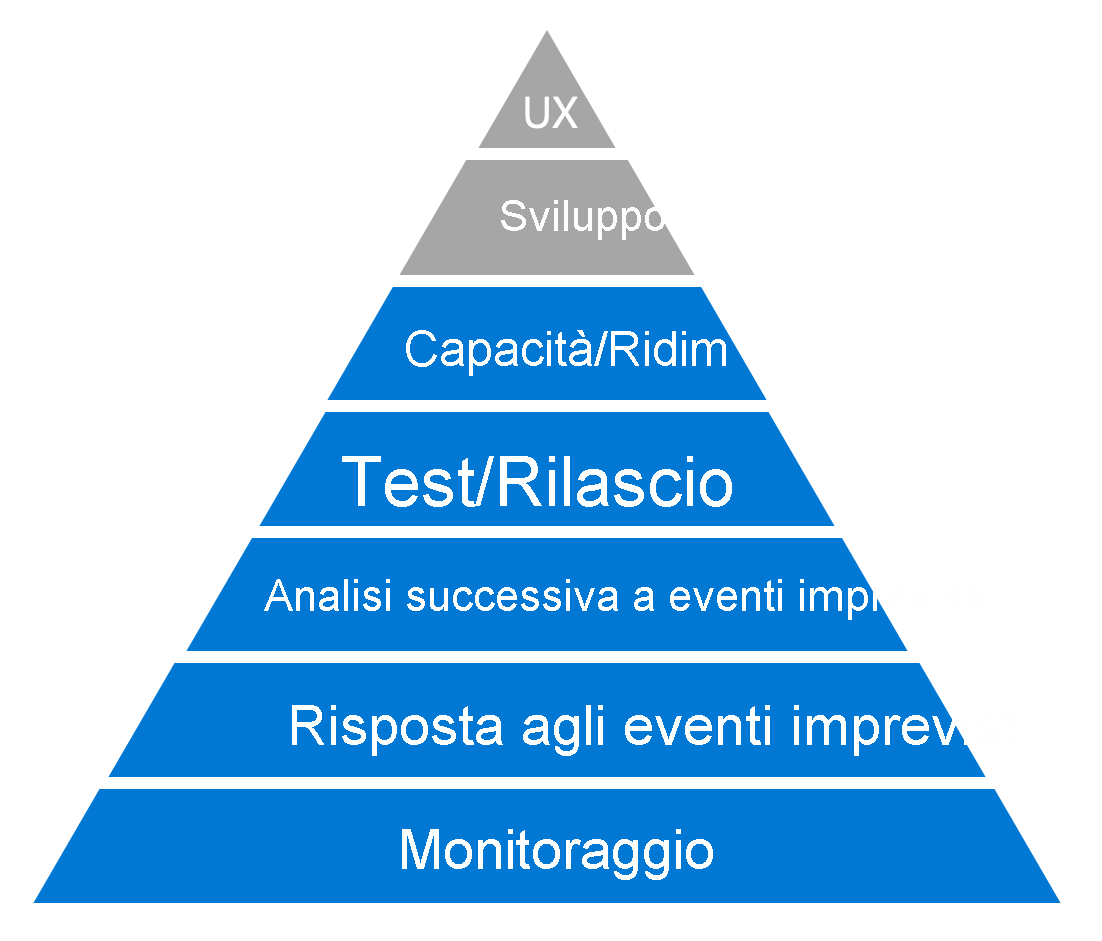
Il modello segue lo schema della gerarchia dei bisogni alla base della motivazione degli esseri umani creata da Abraham Maslow. Come per la gerarchia di Maslow, per salire di un livello nella gerarchia è prima necessario assicurarsi che tutti i livelli sottostanti siano stati soddisfatti. I livelli su cui si concentra l'attenzione in questo percorso di apprendimento, dal basso all'alto, sono:
Monitoraggio
Questo livello rappresenta la base su cui poggiano gli altri livelli. È la fonte di informazioni che offre i dati oggettivi su cui basare qualsiasi trattazione dell'affidabilità all'interno dell'organizzazione. Quando si eseguono modifiche, questa pratica consente di conoscerne gli effetti. Detto in modo ancora più diretto, questa pratica è il modo che consente di sapere se la situazione sta migliorando o meno. Finché la procedura di monitoraggio non è consolidata, non è possibile procedere con il resto del lavoro.
Risposta agli eventi imprevisti
In ogni ambiente di produzione prima o poi si verifica un'interruzione di qualche tipo. Questo è un dato di fatto. La domanda quindi è "Cosa si deve fare quando si verifica un evento imprevisto? "Cosa accade quando i sistemi sono inattivi e i clienti ne risentono?" È necessario un processo standard in grado di valutare il problema in modo efficace, coinvolgere le risorse appropriate e quindi attenuare il problema. Allo stesso tempo è anche necessario assicurarsi di comunicare con gli stakeholder in merito al problema.
Revisione post-evento imprevisto (apprendimento dall'errore)
Questo processo consente di adeguare le procedure operative attraverso l'analisi, la revisione e la discussione collettive dell'esperienza di ogni evento imprevisto significativo. La revisione post-evento imprevisto consente di apprendere dagli errori, un aspetto fondamentale per garantire l'affidabilità.
Test/rilascio (distribuzione)
Il livello superiore successivo si concentra sui processi di test, rilascio e distribuzione. Questo livello può essere considerato la valutazione della capacità dell'organizzazione di creare sistemi e processi in grado di rilevare problemi prima dell'insorgere di eventi imprevisti.
Pianificazione/ridimensionamento della capacità
Il successo e la crescita che lo accompagna possono costituire una minaccia per l'affidabilità di un sistema, esattamente come qualsiasi altro problema. Un cliente non è in grado di distinguere un sistema inattivo a causa della presenza di un bug nel codice da un sistema inattivo perché non è in grado di gestire il carico di un numero eccessivo di tentativi di accesso. Questo livello della gerarchia suggerisce di considerare la pianificazione e il ridimensionamento della capacità come metodi per affrontare questo tipo di minaccia.
Processo di sviluppo ed esperienza utente
Nella gerarchia sono presenti altri due livelli che non vengono trattati nel percorso di apprendimento Migliorare l'affidabilità: il processo di sviluppo e le attività necessarie per la creazione di un'esperienza utente efficace. Questi due argomenti non sono descritti nel percorso di apprendimento Migliorare l'affidabilità, ma sono disponibili altri moduli di Learn validi su questi temi.
È stato creato un modulo Learn separato per ogni livello nella gerarchia dell'affidabilità descritto in precedenza, nella speranza che chi è interessato all'argomento partecipi a tutti e cinque i moduli di questo percorso di apprendimento.