Correzione
Dividendo il ciclo di vita della risposta agli eventi imprevisti in cinque fasi, come illustrato in questo modulo, è possibile capire il processo, ma le fasi non sono sempre distinte come appaiono nel diagramma. In particolare, la linea tra le fasi di risposta e di correzione diventa spesso meno netta. Ciò vale soprattutto quando gli interventi previsti per alleviare o migliorare la situazione hanno in realtà l'effetto opposto. In questo caso, la risposta e la correzione tendono a sovrapporsi o a scambiarsi di posto.
In questa unità verranno fornite altre informazioni sulla fase di correzione e sui relativi passaggi, oltre a proporre alcuni suggerimenti e strumenti utili. È importante sottolineare che non si devono considerare le misure descritte in questo articolo come un elenco di controllo prescrittivo.
In realtà, se è già disponibile un elenco di controllo per la correzione, in genere significa che è il momento di inserire l'automazione nel contesto. Quando è possibile descrivere esattamente gli interventi da eseguire per correggere un problema, e in quale ordine, è il momento giusto per eseguire il training di un sistema in modo che esegua automaticamente questi passaggi.
Dove iniziare
Si è appresa l'importanza della riduzione del tempo necessario per rispondere a un evento imprevisto. Verranno ora esaminati alcuni aspetti che consentono di velocizzare il processo di correzione o risoluzione del problema.
I vari membri del team potrebbero avere modelli mentali diversi su come funzionano le cose e idee diverse per quanto riguarda il primo passo da fare. Per qualcuno potrebbe essere l'analisi dei log, mentre altri potrebbero scegliere di eseguire prima le query ed esaminare le metriche. Non esiste un unico percorso valido per il successo.
È però utile offrire alle persone il contesto e le indicazioni sugli obiettivi previsti e sugli aspetti da analizzare.
Come e a chi assegnare l'escalation
Una domanda importante a cui rispondere durante la formulazione del punto di partenza della correzione è: quando ci si blocca, chi rivolgersi per l'escalation del problema? Si dovrebbe provare a trasferire un maggior carico delle responsabilità degli interventi al team in generale, non solo a quelli che si occupano di operazioni o della progettazione dell'affidabilità del sito. La continua operatività dei sistemi e gli obiettivi di affidabilità dovrebbero essere responsabilità di tutti i membri del team.
Quali risorse sono utili per le prime persone che rispondono in caso di emergenza?
La considerazione successiva consiste nel determinare le risorse che possono essere usate dalle prime persone che rispondono all'emergenza per avviare il processo, ad esempio metriche, log, query pertinenti e così via. Se possibile, queste risorse devono essere fornite tramite una cartella di lavoro o una guida alla risoluzione dei problemi di Azure. Queste funzionalità verranno descritte più avanti.
È inoltre utile fornire semplici collegamenti alle risorse (spesso in una guida alla risoluzione dei problemi). Se l'obiettivo è rispondere e correggere il problema il più rapidamente possibile, sarà possibile accelerare il processo aiutando le persone a trovare le risposte alle domande senza perdere tempo a cercare il documento o l'URL appropriato.
Aggiornare gli stakeholder
Talvolta si è talmente impegnati a risolvere il problema che ci si potrebbe dimenticare delle numerose persone non direttamente coinvolte nella risposta all'evento imprevisto che, tuttavia, vogliono e devono sapere cosa succede.
È importante comunicare con altri team interni e mantenerli informati sulle conseguenze degli eventi imprevisti che si verificano. Se non si forniscono aggiornamenti coerenti, è probabile che questi stakeholder vengano a chiedere un aggiornamento sullo stato. Hanno tutti i diritti di ricevere queste informazioni, ma è necessario trovare un modo migliore per metterli al corrente del problema e degli interventi intrapresi al riguardo.
I team interni devono essere aggiornati tramite un processo ben definito. Bisogna presentare chiaramente le informazioni note e gli interventi in corso e definire tempi e modi certi per quanto riguarda gli aggiornamenti che possono aspettarsi.
La formula per le comunicazioni con gli stakeholder è semplice:
- Questo è quello che sappiamo.
- Questo è quello che intendiamo fare.
- Ci faremo risentire tra X giorni.
In questo modo si eviterà di essere interrotti dagli stakeholder mentre si è impegnati a tentare di risolvere i problemi.
Un modo per distribuire queste informazioni consiste nell'usare una pagina Web di aggiornamenti facilmente modificabile come quella citata nell'ultima unità. In molti casi si potrebbe scegliere di impostare una pagina più dettagliata per gli stakeholder interni e un'altra esterna per i clienti. La formula precedente funziona per entrambi i casi.
Usare Cartelle di lavoro di Monitoraggio di Azure e Guide alla risoluzione dei problemi
Azure offre due funzionalità strettamente correlate che possono risultare estremamente utili per un team nella fase di correzione: Cartelle di lavoro di Monitoraggio di Azure e Guide alla risoluzione dei problemi di Application Insights. Ai fini di questo modulo sono intercambiabili e presentano anche la stessa interfaccia utente. Cartelle di lavoro di Monitoraggio di è disponibile nel portale di Azure in Monitoraggio di Azure. Le Guide alla risoluzione dei problemi di Azure Insights sono disponibili nel portale di Azure, una volta selezionata un'istanza di Applications Insight.
Le cartelle di lavoro e le guide alla risoluzione dei problemi possono essere considerate "documenti dinamici" che è possibile creare con un'interfaccia per la creazione di pagine. Quando si crea un documento nuovo, è possibile aggiungere alla pagina:
- Testo arbitrario, ad esempio un elenco puntato di attività da completare o altre informazioni utili per chi consulta la pagina
- Collegamenti ad altri sistemi, ad esempio ad altri dashboard o alla documentazione
- Query KQL (Kusto Query Language)
Quest'ultimo punto è quello che rende "dinamici" i documenti. In un modulo precedente di questo percorso di apprendimento, è stato esplorato il linguaggio di query KQL integrato in Log Analytics e in altri parti di Monitoraggio di Azure. Con questo linguaggio è possibile scrivere query personalizzate per restituire e visualizzare informazioni di diagnostica dell'applicazione e dell'infrastruttura di Azure. Quando si inserisce una query KQL in una cartella di lavoro o in una guida alla risoluzione dei problemi, i relativi risultati vengono visualizzati in tempo reale dai lettori del documento. Questo significa che una guida alla risoluzione dei problemi può includere non solo un avviso, ad esempio per invitare a controllare la frequenza degli errori del server Web, ma anche un grafico aggiornato, in questo caso sulla frequenza degli errori, accanto alle istruzioni. La guida può fornire un collegamento per accedere direttamente alla documentazione, ad esempio su come riavviare un server Web.
Azure offre anche alcuni modelli da usare come base per iniziare a creare documenti personalizzati. Ecco uno screenshot di alcuni modelli predefiniti che è possibile usare:
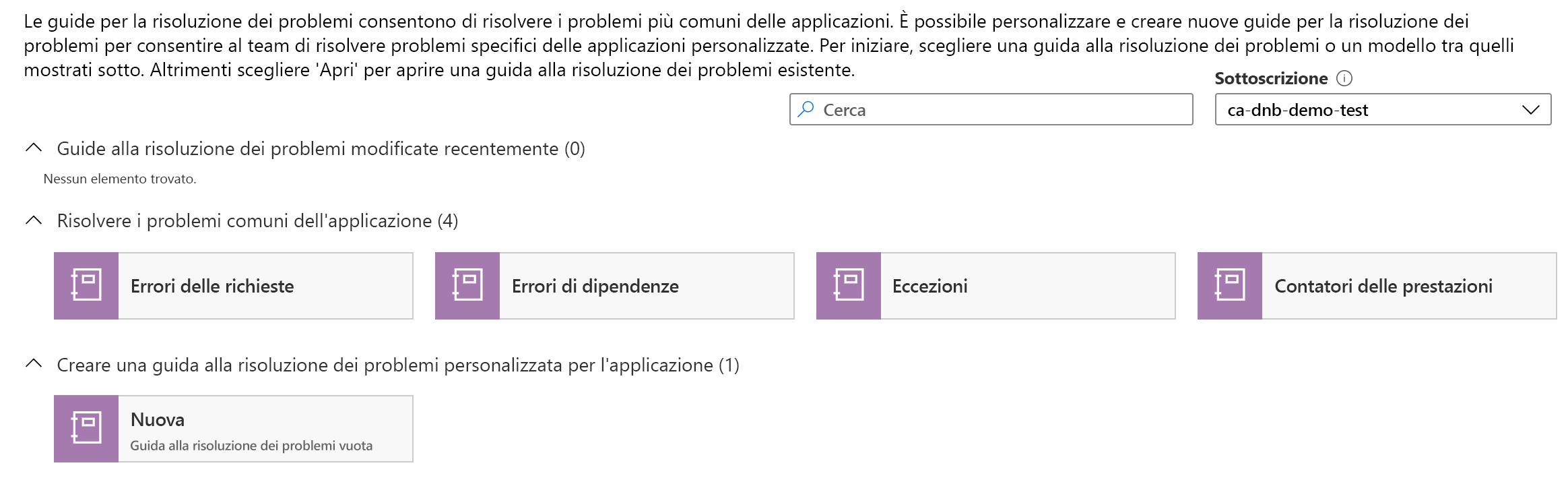
Per le cartelle di lavoro e le guide alla risoluzione dei problemi è disponibile una funzionalità di Editor avanzato che consente di accedere e inserire codice JSON o la rappresentazione di tale documento in un modello di Azure Resource Manager. Questo significa che è possibile tenere traccia di questi documenti e distribuirli tramite un sistema di controllo del codice sorgente a scelta. È anche possibile automatizzare il provisioning di cartelle di lavoro e guide alla risoluzione dei problemi, il che può essere utile per il provisioning di un'altra infrastruttura. Con questa procedura consigliata diventa facile creare una serie di documenti personalizzati per la risoluzione dei problemi da associare a un nuovo servizio nel momento in cui ne viene effettuato il provisioning.
Altri suggerimenti e strumenti utili
In questo modulo sono stati illustrati vari suggerimenti e gli strumenti che è possibile usare per aumentare l'efficienza e ridurre il tempo di risposta agli eventi imprevisti. Per concludere quest'ultima unità, verrà presentata una breve panoramica di alcuni strumenti e tecniche utili per diagnosticare i problemi all'interno dei sistemi.
- È possibile usare il collegamento a Dashboard dell'applicazione di Application Insights per generare automaticamente un dashboard contenente la maggior parte degli elementi chiave necessari come punto di partenza. Se noti che il servizio Integrità dei servizi di Azure non è incluso. È necessario aggiungerlo al dashboard in modo da verificare se i problemi riguardano il sistema o il servizio cloud stesso.
- È possibile usare la funzionalità Mappa delle applicazioni di Application Insights per approfondire la causa esatta dei problemi. È possibile seguire i percorsi di navigazione per trovare la causa dell'errore, ad esempio un URL in formato non valido.
- È possibile usare Log Analytics per eseguire query su qualsiasi parte del sistema.
Tutti gli strumenti precedenti sono preziosi per risolvere i problemi.