Modellare piccole entità di ricerca
Il modello di dati include due piccole entità di dati di riferimento, ProductCategory e ProductTag. Queste entità vengono usate per i valori di riferimento e sono correlate ad altre entità attraverso un oggetto 1:Many relationship.
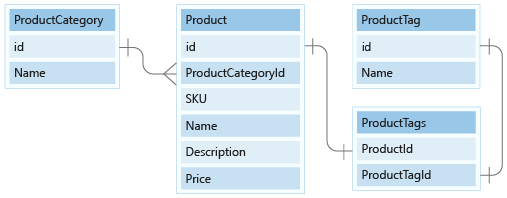
In questa unità verranno modellate le entità ProductCategory e ProductTag nel modello di documento.
Modellare le categorie di prodotti
Per le categorie, i dati verranno modellati con le relative colonne id e name come uniche proprietà e inseriti in un nuovo contenitore denominato ProductCategory.
Successivamente è necessario scegliere una chiave di partizione. Verranno ora esaminate le operazioni che è necessario eseguire su questi dati.
Verrà creata una nuova categoria prodotto, verrà modificata una categoria prodotto e quindi verranno elencate tutte le categorie di prodotti. La creazione e la modifica delle categorie di prodotti non sono operazioni eseguite di frequente. L'applicazione di e-commerce spesso elenca tutte le categorie di prodotti quando i clienti visitano il sito Web. Quindi l'ultima operazione è quella che verrà eseguita di più.
La query per quest'ultima operazione sarà simile a questa: SELECT * FROM c.
Con id come chiave di partizione selezionata questa query viene eseguita tra partizioni, anche se si vuole provare a ottimizzare queste operazioni con intensa attività di lettura, usare solo una singola partizione, se possibile. Sappiamo anche che le dimensioni dei dati per la categoria di prodotti non cresceranno mai fino a circa 20 GB, quindi sulla base di queste informazioni occorre modellare i dati in modo da generare una query a partizione singola quando vengono elencate tutte le categorie di prodotti.
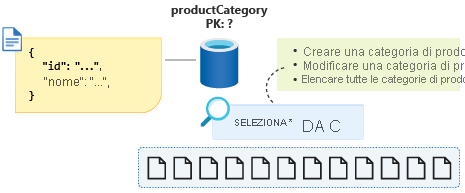
Per imporre questa piccola quantità di dati in una singola partizione, è possibile aggiungere una proprietà del discriminatore dell'entità allo schema e usarla come chiave di partizione per questo contenitore. Assegnando a questa proprietà un valore costante per tutti i documenti di questo tipo nel contenitore, si garantisce la disponibilità di una query a partizione singola. In questo caso, si chiamerà la proprietà type e si assegnerà un valore costante di category. La query avrà ora un aspetto simile a: SELECT * FROM c WHERE c.type = ”category”.

Modellare i tag prodotto
Successivamente si passa all'entità ProductTag. Dal punto di vista funzionale, questa entità è quasi identica all'entità ProductCategory descritta nella sezione precedente. Qui viene adottato lo stesso approccio e il documento viene modellato in modo da contenere le proprietà ID e name e creare una proprietà del discriminatore dell'entità denominata type, in questo caso con un valore costante di tag. Creare un nuovo contenitore denominato ProductTag e impostare type come nuova chiave di partizione.
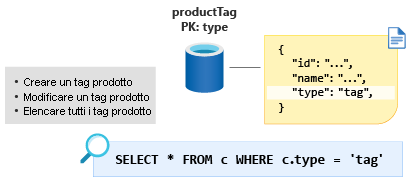
Alcune persone trovano strana questa tecnica di modellazione delle tabelle di ricerca di piccole dimensioni. Tuttavia, modellare i dati in questo modo offre l'opportunità di eseguire un'ulteriore ottimizzazione nel modulo successivo.