Requisiti di accesso ai file ibridi
Le unità precedenti erano incentrate principalmente su cosa fa la soluzione di archiviazione. Questa unità è incentrata su dove si trovano i dati. In particolare, vengono affrontate alcune considerazioni sull'accesso ai file ibridi e il modo in cui gestire questi aspetti.
Panoramica dell'accesso ai file ibridi
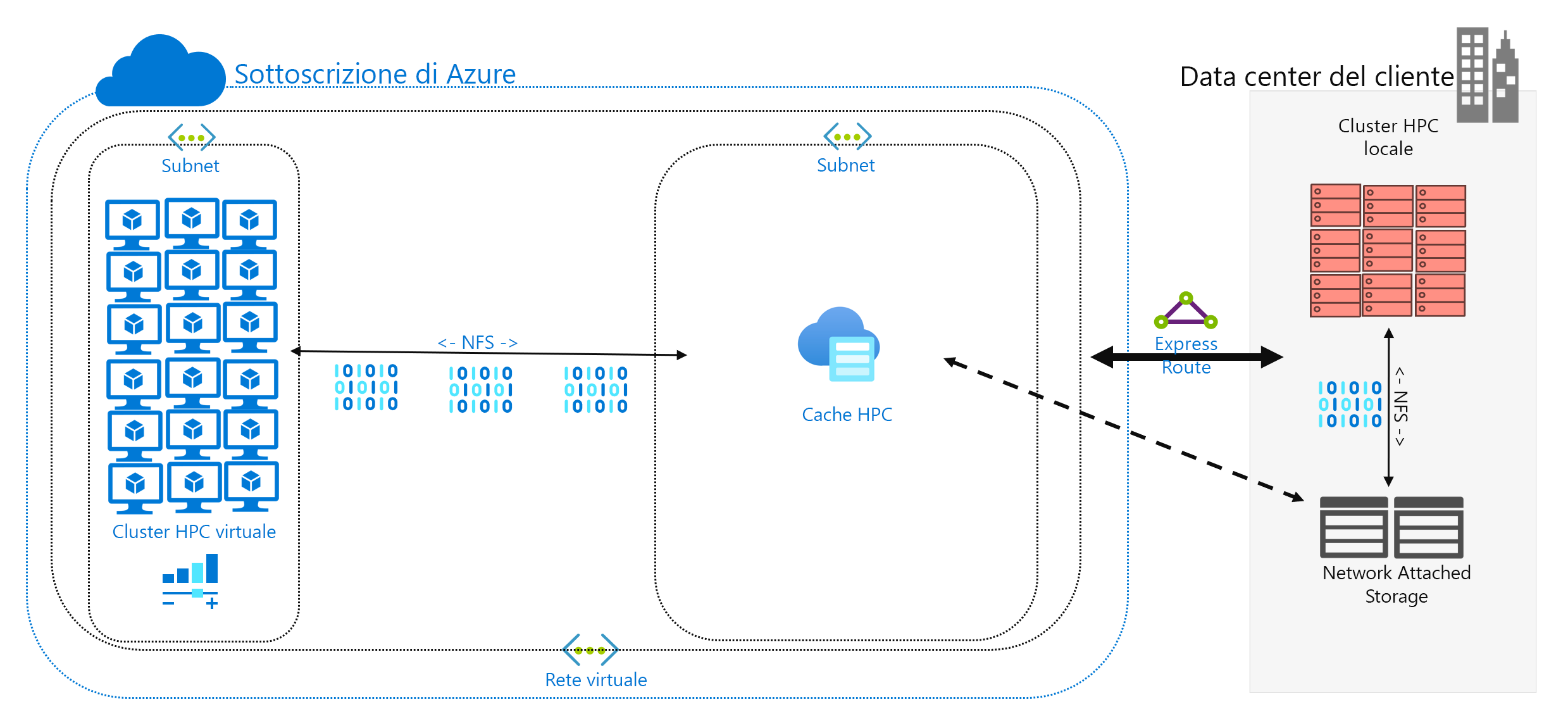
È stato deciso di eseguire in Azure un carico di lavoro HPC che è attualmente in esecuzione nel data center. L'ambiente di calcolo accede ai dati di NAS, che trasmette operazioni NFSv3 al carico di lavoro. Il carico di lavoro è stato eseguito nel data center per anni, ma è possibile che l'ambiente NAS stia raggiungendo la fine del ciclo di vita. Invece di sostituirlo, si sta valutando una migrazione a lungo termine al cloud.
Dopo avere preso questa decisione ma pima della distribuzione cloud completa del carico di lavoro HPC, si definisce la strategia di Azure e si stabilisce la configurazione di base per account/sottoscrizione/sicurezza. Si arriva quindi alla parte complessa: lo spostamento dei carichi di lavoro HPC.
La creazione del cluster HPC e del rispettivo piano di gestione non rientrano nell'ambito di questo modulo. Si presuppone che siano state prese decisioni in merito ai tipi e al numero di macchine virtuali che si vuole eseguire nel cluster.
Per il momenti si presuppone anche che l'obiettivo specifico consista nell'eseguire il carico di lavoro così com'è, ovvero non verranno apportate modifiche alla logica o ai metodi di accesso attualmente distribuiti in locale. Il codice si aspetta quindi che i dati si trovino in percorsi di directory nei file system locali dei membri del cluster.
Il primo obiettivo consiste nel comprendere quali dati sono necessari e da dove vengono originati. È possibile che i dati si trovino in una singola directory in un singolo ambiente NAS o che siano distribuiti in diversi ambienti.
L'obiettivo successivo consiste nel determinare quanti dati sono necessari per eseguire il carico di lavoro. Occorre stabilire se i dati di origine sono pari a un paio di gigabyte o a centinaia di terabyte.
È infine necessario stabilire il modo in cui i dati vengono presentati nelle risorse di calcolo di Azure, ovvero se vengono forniti in locale a ogni computer del cluster HPC o vengono condivisi da una soluzione NAS basata sul cluster.
Considerazioni sull'accesso remoto ai dati
Si vuole eseguire in Azure un carico di lavoro di genomica esistente. I dati vengono generati in locale da sequenziatori di dati genetici e inviati a un ambiente NAS locale. I ricercatori locali utilizzano i dati per diverse finalità. È possibile che i ricercatori vogliano utilizzare anche i risultati del carico di lavoro HPC che si vuole eseguire in Azure. Alcuni ricercatori usano tuttavia workstation locali per queste operazioni. Si supponga inoltre che nuovi dati di genomica vengano generati regolarmente. È quindi disponibile un intervallo limitato per l'esecuzione del carico di lavoro corrente prima che sia necessario sostituire/aggiornare i dati.
La sfida consiste nel presentare i dati alle risorse di calcolo di Azure in modo economicamente conveniente e tempestivo, ma conservare comunque l'accesso locale a tali dati.
Di seguito sono elencate alcune delle domande più importanti a cui rispondere quando si prova a eseguire carichi di lavoro HPC in Azure:
- È possibile spostare i dati di origine in Azure senza conservare una copia in locale?
- È possibile salvare i dati dei risultati in Archiviazione di Azure senza conservare una copia in locale?
- È necessario che gli utenti locali abbiano accesso simultaneo ai dati di origine o dei risultati?
- In tale caso, potranno eseguire operazioni sui dati in Azure o necessiteranno dell'archiviazione locale dei dati?
Se è necessario conservare in locale i dati, quanti dati devono essere copiati in Azure per il carico di lavoro? Quanto tempo è disponibile dopo l'elaborazione dei dati prima che sia necessario elaborare un nuovo set di dati? Il carico di lavoro verrà eseguito in tale intervallo di tempo?
È inoltre necessario prendere in considerazione la connettività di rete ad Azure. È disponibile solo l'accesso Internet ad Azure? La limitazione potrebbe essere accettabile, in base alle dimensioni dei dati da copiare/trasferire e dal periodo di tempo disponibile tra gli aggiornamenti. È possibile che sia necessario copiare ogni volta una quantità elevata di dati. Potrebbe essere necessaria una connessione WAN (Wide Area Network) ad Azure che usa Azure ExpressRoute, che offre larghezza di banda maggiore per la copia o il trasferimento di dati.
Se è già disponibile una connessione ExpressRoute ad Azure, è necessario stabilire quindi quale porzione della connessione è disponibile per l'operazione di copia dei dati. Se il collegamento è altamente saturato, potrebbe essere necessario valutare l'ora del giorno in cui si trasferiscono i dati. oppure configurare una connessione ExpressRoute più grande per consentire trasferimenti dei dati più grandi.
Se si spostano i dati in Azure, potrebbe essere necessario prendere in considerazione le modalità da usare per proteggerli. È ad esempio possibile che sia disponibile un ambiente NFS locale che usa un servizio directory che semplifica l'estensione delle autorizzazioni agli utenti. Se si prevede di copiare questo approccio alla sicurezza in Azure, è necessario stabilire se un servizio directory è necessario come parte della configurazione di Azure. Se invece il carico di lavoro è limitato al cluster HPC e i risultati verranno trasferiti di nuovo nell'ambiente locale, potrebbe essere possibile evitare questi requisiti.
Vengono quindi esaminati i metodi usati per accedere ai dati, ovvero memorizzazione nella cache, copia e sincronizzazione.
Confronto tra memorizzazione nella cache, copia e sincronizzazione
Vengono illustrati gli approcci generali che è possibile usare per aggiungere dati in Azure. La discussione sul trasferimento dei dati si incentrerà sui dati attivi, non sull'archiviazione e il backup dei dati.
Si supponga che i dati trasferiti in questa analisi corrispondano al working set di un carico di lavoro HPC. In un ambiente HPC per scienze biologiche è possibile che i dati includano dati di origine come dati genomici non elaborati, file binari usati per elaborare tali dati o dati supplementari come genomi di riferimento. È necessario elaborarli immediatamente dopo l'arrivo o poco tempo dopo. È inoltre necessario che i dati vengano archiviati in supporti di memorizzazione con il profilo di prestazioni appropriato per operazioni di I/O al secondo, latenza, velocità effettiva e costo. I dati di archiviazione/backup, invece, vengono nella maggior parte dei casi trasferiti nella soluzione di archiviazione meno costosa possibile, che non è destinata all'accesso a prestazioni elevate.
I metodi principali per il trasferimento di dati attivi sono la memorizzazione nella cache, la copia e la sincronizzazione. Verranno analizzati i pro e i contro di ogni approccio, iniziando con la copia.
La copia dei dati è l'approccio più comune per lo spostamento dei dati. I dati vengono copiati in molti modi, in base allo strumento usato.
Tenere presente questi fattori:
- Dimensioni dei file.
- Numero di file.
- Velocità effettiva disponibile per il trasferimento dei dati.
- Tempo disponibile per il trasferimento.
Uno strumento di copia di base come cp è sufficiente se si trasferiscono pochi file di dimensioni ragionevoli in una destinazione remota. Sarà probabilmente consigliabile usare scp invece di cp se si trasferiscono dati su reti non protette: scp fornisce la crittografia su una connessione SSH (Secure Shell).
Sono disponibili molti approcci per ottimizzare le operazioni di copia, in base alla posizione in cui si vogliono copiare i dati. Se si copiano file direttamente in ogni computer HPC, sarà ad esempio possibile pianificare singole operazioni di copia in ogni nodo.
Quando si copiano dati tra collegamenti WAN è necessario prendere in considerazione la quantità di file e cartelle da copiare. Se si copiano molti file di piccole dimensioni, è consigliabile combinare l'uso della copia con un archivio come tar per rimuovere il sovraccarico dei metadati dal collegamento WAN. Copiare il file con estensione tar in Azure e quindi copiare i dati nei computer.
Un altro problema della copia è costituito dal rischio di interruzione. Se ad esempio si prova a copiare un file di grandi dimensioni e si verificano errori di trasmissione, non è possibile usare cp perché non consente di riavviare la copia dal punto in cui è stata interrotta.
Un problema finale relativo alla copia dei dati consiste nel fatto che la copia può diventare obsoleta. È ad esempio possibile che si esegua la copia di un set di dati in Azure e che nel frattempo un utente locale abbia aggiornato uno o più file di origine. Sarà necessario definire un processo per assicurarsi di usare i dati corretti.
La sincronizzazione dei dati è una forma di copia, ma è più sofisticata. Strumenti come rsync offrono anche la possibilità di sincronizzare i dati tra origine e destinazione, oltre a copiarli dall'origine. rsync assicura che i file siano aggiornati in base alle dimensioni dei file e alle date di modifica. La sincronizzazione consente di ridurre al minimo la possibilità di usare file obsoleti.
rsync offre una funzionalità di ripristino. Se ad esempio si copia un file di grandi dimensioni e si verificano problemi di trasmissione, rsync potrà riavviare la copia dal punto in cui è stata interrotta.
rsync è gratuito e facile da implementare. Include altre funzionalità, oltre a quelle illustrate in questa unità. Consente di stabilire un file system sincronizzato in Azure basato sui dati locali.
rsync presenta anche alcune limitazioni che devono essere prese in considerazione. Lo strumento è prima di tutto a thread singolo. Può eseguire solo un'operazione alla volta e non può parallelizzare l'accesso ai dati. Anche l'utilità di copia cp è a thread singolo. Questi strumenti non sono quindi ottimizzati per operazioni di copia/sincronizzazione di grandi dimensioni che interessano quantità elevate di dati e una finestra temporale ridotta. È inoltre necessario eseguire lo strumento per sincronizzare i dati. L'esecuzione dello strumento aggiunge complessità all'ambiente perché è necessario assicurare che sia in esecuzione in base ai requisiti dell'intervallo temporale. È ad esempio consigliabile pianificare uno script che include rsync. Questo approccio richiede l'aggiunta dello script, nel caso in cui si verifichino problemi. È inoltre necessario monitorare i problemi. Il livello di complessità può crescere rapidamente.
Se si esegue una soluzione NAS commerciale, sono disponibili per l'acquisto strumenti di sincronizzazione a livello di server che sono più sofisticati e offrono prestazioni multithread. Dopo l'abilitazione e la configurazione, questi strumenti sono sempre operativi e sincronizzano i dati tra una o più origini e destinazioni.
La copia e la sincronizzazione trasmettono copie complete dei dati di origine. La trasmissione completa dei file potrebbe essere idonea per set di dati o dimensioni di file minori. Può comportare ritardi significativi se i dati di origine sono costituiti da molti file di grandi dimensioni. Più elevata è la quantità di dati, più tempo sarà necessario per il trasferimento. La sincronizzazione consente di assicurare che vengano aggiunti al cloud solo i nuovi file. È tuttavia necessario trasmettere interamente questi file. In alcuni casi è possibile che il carico di lavoro HPC non richieda l'intero set di file specifico. Potrebbe richiedere l'accesso solo ad aree specifiche dei file.
La memorizzazione nella cache dei dati è il terzo approccio per l'aggiunta di dati ad Azure. La memorizzazione nella cache fa riferimento al recupero e alla presentazione di dati dei file tramite una cache. La cache può essere situata in singoli client locali oppure può essere una cache distribuita che viene usata da tutti i computer HPC. Le cache vengono solitamente usate per ridurre al minimo la latenza, quindi il posizionamento di una cache in corrispondenza dei limiti di latenza è un approccio ottimale per fornire dati. È ad esempio possibile memorizzare le richieste di dati nella cache su una connessione WAN posizionando una cache distribuita in una risorsa di calcolo di Azure connessa a risorse di archiviazione locali mediante il collegamento WAN.
In questo modulo viene fatto riferimento in modo specifico alla memorizzazione nella cache dei file, in cui la cache stessa gestisce le richieste dai computer. Recupera i dati dall'ambiente di archiviazione back-end, ad esempio un ambiente NAS NFS, e li presenta ai client.
La memorizzazione nella cache offre due vantaggi. Le cache non recuperano prima di tutto file interi. Una cache recupera un subset richiesto o un intervallo di byte dei file, invece dei file interi. Il recupero è basato sulle richieste client per tali intervalli di byte. Questo approccio al recupero riduce al minimo le penalizzazioni per le prestazioni dovute al recupero di un intero file di grandi dimensioni quando è necessaria solo una sezione ridotta del file.
In secondo luogo le cache ottimizzano l'accesso ripetuto a dati richiesti di frequente. Quando un intervallo di byte è presente nella cache, le richieste successive per tali dati saranno veloci. L'unico recupero lento è il primo recupero. È possibile ottenere vantaggi significativi quando si esegue un numero elevato di client/thread HPC che accedono a un set comune di file.
La memorizzazione nella cache offre un altro vantaggio per gli scenari ibridi. I dati vengono archiviati in Azure (nella cache) solo temporaneamente e vengono archiviati solo durante il funzionamento del carico di lavoro HPC. È quindi possibile ridurre il sovraccarico logistico correlato a spostamenti di dati più concreti in Azure. È possibile isolare gli aspetti relativi alla privacy e alla sicurezza dei dati alla cache e ai computer HPC stessi.
Alcune soluzioni di memorizzazione nella cache offrono infine il controllo degli attributi. Analogamente alla sincronizzazione, la cache controlla periodicamente gli attributi del file all'origine e recupera gli intervalli di byte quando la modifica del file risulta superiore nell'origine. Questa architettura assicura che l'ambiente HPC usi sempre i dati più aggiornati.