Opzioni di configurazione di HDInsight
HDInsight dispone di un'ampia gamma di tecnologie OSS incorporate che possono essere usate per gestire gli scenari di dati in streaming e in batch, ovvero i termini definiti nelle architetture Lambda. In questo modello di architettura è disponibile sia un percorso critico che un percorso non critico di dati. Il percorso critico di dati viene generato in tempo reale da dispositivi, sensori o applicazioni e l'analisi dei dati viene eseguita quasi in tempo reale; spesso si fa riferimento a questo percorso con il nome di dati in streaming. Un percorso dati ad accesso sporadico si verifica quando i dati vengono spostati in batch, in genere da altri archivi dati; spesso si fa riferimento a questo percorso con il nome di dati in batch.
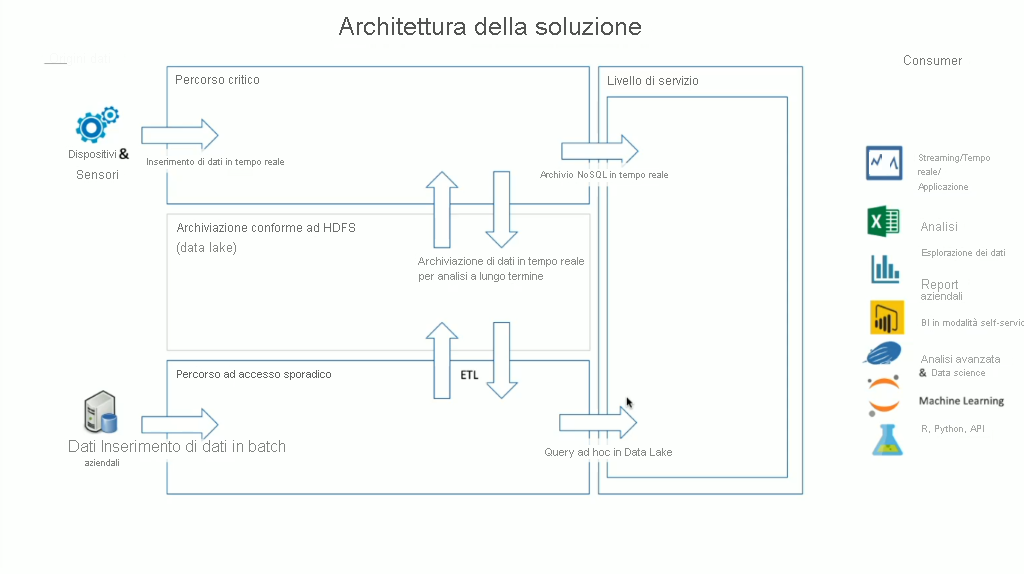
Quando si implementa HDInsight, l'archiviazione dei dati viene mantenuta all'interno di un file system distribuito Hadoop conforme (HDFS). Come archivio dati in Azure si usa in genere Data Lake Gen2 perché è conforme a HDFS. Dopo l'elaborazione i dati del percorso ad accesso frequente e del percorso ad accesso sporadico vengono archiviati in un archivio dati centralizzato denominato data lake. Il data lake in sé può essere suddiviso in raggruppamenti per contenere i dati in raggruppamenti diversi, che possono essere definiti dallo stato dei dati (zona di destinazione, zona di trasformazione e così via), dai requisiti di accesso (ad accesso frequente, medio e sporadico) e dai gruppi aziendali. Il livello di servizio è il raggruppamento finale del data lake che contiene i dati in un formato pronto per l'uso da parte di diversi tipi di consumer.
Fondamentalmente, la parte del calcolo di HDInsight riguarda l'elaborazione di dati in streaming o in batch e può variare a seconda del tipo di cluster selezionato durante il provisioning di un cluster HDInsight. HDInsight offre i servizi nelle singole opzioni del cluster, come illustrato nella tabella seguente.
| Tipo di cluster | Descrizione |
|---|---|
| Apache Hadoop | Framework che usa HDFS e un semplice modello di programmazione MapReduce per elaborare e analizzare i dati in batch. |
| Apache Spark | è un framework open source di elaborazione parallela che supporta l'elaborazione in memoria per migliorare le prestazioni di applicazioni analitiche di Big Data. |
| HBase | un database NoSQL basato su Hadoop che fornisce accesso casuale e coerenza assoluta per quantità elevate di dati non strutturati e semistrutturati. Può gestire potenzialmente milioni di righe e colonne. |
| Apache Interactive Query | Caching in memoria per query Hive interattive e più rapide. |
| Apache Kafka | una piattaforma open source usata per creare applicazioni e pipeline di dati di streaming. Kafka fornisce inoltre funzionalità di code di messaggi che consentono di pubblicare e sottoscrivere i flussi di dati. |
Pertanto, è importante selezionare il tipo di cluster corretto adatto a soddisfare il caso aziendale che si sta tentando di risolvere. Indipendentemente dal tipo di cluster selezionato, all'interno del cluster vengono aggiunti anche componenti open source aggiuntivi per offrire funzionalità supplementari, tra cui:
Gestione Hadoop
HCatalog: un livello di gestione di tabelle e archiviazione per Hadoop.
Apache Ambari: semplifica la gestione e il monitoraggio di un cluster Apache Hadoop.
Apache Oozie: un sistema di pianificazione del flusso di lavoro per la gestione dei processi di Apache Hadoop.
Apache Hadoop YARN: si occupa della gestione delle risorse e della pianificazione e del monitoraggio dei processi.
Apache ZooKeeper: servizio centralizzato per la gestione delle informazioni di configurazione, dei nomi e per la sincronizzazione distribuita e la fornitura di servizi di gruppo.
Elaborazione dati
Apache Hadoop MapReduce: framework per la scrittura semplificata di applicazioni che elaborano grandi quantità di dati.
Apache Tez: framework dell'applicazione per l'elaborazione dei dati.
Apache Hive: semplifica la gestione tramite SQL di set di dati di grandi dimensioni che risiedono nella risorsa di archiviazione distribuita.
Analisi dei dati
Apache Pig: fornisce un livello di astrazione rispetto a MapReduce per l'analisi di set di dati di grandi dimensioni.
Apache Phoenix: abilita l'uso di OLTP e analisi operative in Hadoop.
Apache Mahout: framework di algebra per la creazione di algoritmi personalizzati.
Nota
Al momento della stesura di questo documento, Azure Data Lake Gen1 e Archiviazione BLOB di Azure sono livelli di archiviazione dati supportati per HDInsight. È consigliabile eseguire la migrazione di questi dati ad Azure Data Lake Gen2 perché si tratta della piattaforma di archiviazione consigliata per Spark e Hadoop, oltre a essere la scelta predefinita per HBase.