Informazioni sui data warehouse in Fabric
Lakehouse di Fabric è una raccolta di file, cartelle, tabelle e collegamenti che si comporta come un database su un data lake. Viene usato dal motore Spark e dal motore SQL per l'elaborazione dei big data e dispone di funzionalità per le transazioni ACID quando si usano le tabelle formattate Delta open source.
L'esperienza del data warehouse di Fabric consente di passare dalla vista lake di Lakehouse (che supporta l'ingegneria dei dati e Apache Spark) all'esperienza SQL di un data warehouse tradizionale. Lakehouse consente di leggere le tabelle e di usare l'endpoint di Analisi SQL, mentre il data warehouse consente di modificare i dati.
Nell'esperienza del data warehouse, si modellano i dati usando tabelle e viste, si esegue T-SQL per eseguire query dei dati nel data warehouse e in Lakehouse, si usa T-SQL per eseguire operazioni DML sui dati all'interno del data warehouse e si usano livelli di creazione di report come Power BI.
Ora che si conoscono i principi dell'architettura di base per uno schema di data warehouse relazionale, si vedrà come creare un data warehouse.
Descrivere un data warehouse in Fabric
Nell'esperienza di data warehouse in Fabric, è possibile creare un livello relazionale sopra i dati fisici in Lakehouse ed esporlo agli strumenti di analisi e creazione di report. È possibile creare il data warehouse direttamente in Fabric da crea hub o all'interno di un'area di lavoro. Dopo aver creato un warehouse vuoto, è possibile aggiungervi oggetti.
Dopo aver creato il warehouse, è possibile creare le tabelle usando T-SQL direttamente nell'interfaccia di Fabric.
Inserire i dati nel data warehouse
Esistono alcuni modi per inserire i dati in un data warehouse di Fabric, tra cui Pipeline, Flussi di dati, query tra database e il comando COPY INTO. Dopo l'inserimento, i dati diventano disponibili per l'analisi da parte di più gruppi aziendali, che possono usare funzionalità come l'esecuzione di query e la condivisione tra database per accedervi.
Creare tabelle
Per creare una tabella nel data warehouse, è possibile usare SQL Server Management Studio (SSMS) o un altro client SQL per connettersi al data warehouse ed eseguire un'istruzione CREATE TABLE. È anche possibile creare tabelle direttamente nell'interfaccia utente di Fabric.
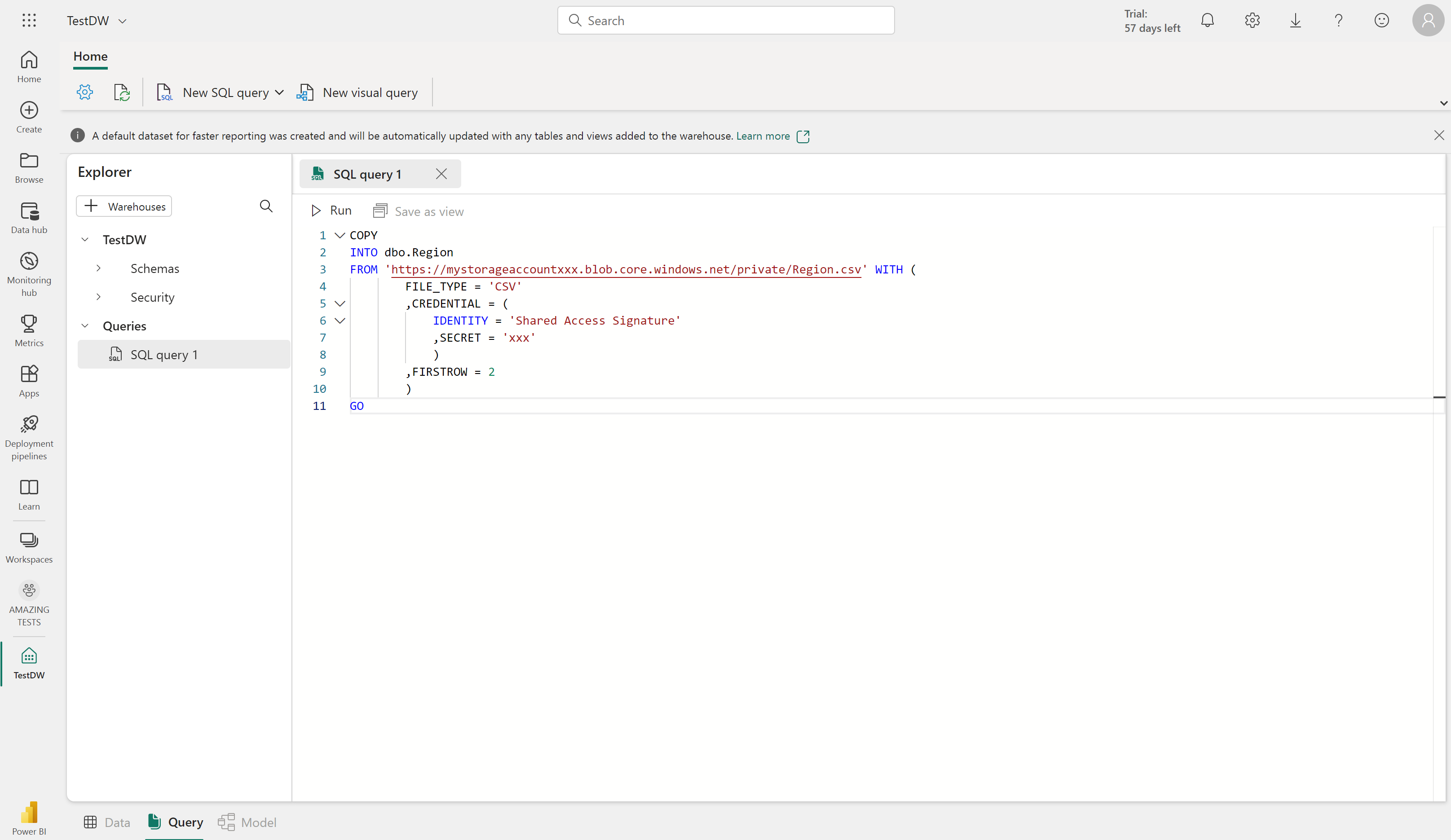
È possibile copiare i dati da una posizione esterna in una tabella del data warehouse usando la sintassi COPY INTO. Ad esempio:
COPY INTO dbo.Region
FROM 'https://mystorageaccountxxx.blob.core.windows.net/private/Region.csv' WITH (
FILE_TYPE = 'CSV'
,CREDENTIAL = (
IDENTITY = 'Shared Access Signature'
, SECRET = 'xxx'
)
,FIRSTROW = 2
)
GO
Questa query SQL carica i dati da un file CSV archiviato in Archiviazione BLOB di Azure in una tabella denominata "Area" nel data warehouse di Fabric.
Clonare le tabelle
È possibile creare cloni di tabelle con copia zero con costi di archiviazione minimi in un data warehouse. Questi cloni sono essenzialmente repliche di tabelle create copiando i metadati pur facendo riferimento agli stessi file di dati in OneLake. Ciò significa che i dati archiviati sottostanti come file Parquet non vengono duplicati, consentendo così di risparmiare sui costi di archiviazione.
I cloni di tabelle sono particolarmente utili in diversi scenari.
- Sviluppo e test: I cloni consentono agli sviluppatori e ai tester di creare copie di tabelle in ambienti inferiori, semplificando lo sviluppo, il debug, i test e i processi di convalida.
- Ripristino dei dati: In caso di rilascio non riuscito o danneggiamento dei dati, i cloni di tabella possono mantenere lo stato precedente dei dati, abilitando il ripristino dei dati.
- Creazione di report cronologici: Consentono di creare report cronologici che riflettono lo stato dei dati in punti specifici nel tempo e conservano i dati in attività cardine aziendali specifiche.
È possibile creare un clone di tabella usando il comando T-SQL CREATE TABLE AS CLONE OF.
Per altre informazioni sui cloni di tabelle, vedere l’Esercitazione : Clonare una tabella usando T-SQL in Microsoft Fabric.
Considerazioni sulle tabelle
Dopo aver creato le tabelle in un data warehouse, è importante prendere in considerazione il processo di caricamento dei dati in tali tabelle. Un approccio comune consiste nell'usare le tabelle di staging. In Fabric, è possibile usare i comandi T-SQL per caricare i dati dai file alle tabelle di staging del data warehouse.
Le tabelle di staging sono tabelle temporanee che possono essere usate per eseguire la pulizia dei dati, le trasformazioni dei dati e la convalida dei dati. È anche possibile usare le tabelle di staging per caricare i dati da più origini in una singola tabella di destinazione.
Il caricamento dei dati viene in genere eseguito come processo batch periodico in cui gli inserimenti e gli aggiornamenti del data warehouse sono programmati a intervalli regolari (ad esempio su base giornaliera, settimanale o mensile).
In genere, è consigliabile implementare il processo di caricamento del data warehouse affinché esegua le attività nell’ordine seguente:
- Inserire i nuovi dati da caricare in un data lake, applicando la pulizia o le trasformazioni di pre-caricamento in base alle esigenze.
- Caricare i dati dai file nelle tabelle di staging nel data warehouse relazionale.
- Caricare le tabelle delle dimensioni dai dati delle dimensioni nelle tabelle di staging, aggiornando le righe esistenti o inserendo nuove righe e generando valori di chiave sostitutiva, in base alle esigenze.
- Caricare le tabelle dei fatti dai dati dei fatti nelle tabelle di staging, cercando le chiavi sostitutive appropriate per le dimensioni correlate.
- Eseguire l'ottimizzazione post-caricamento aggiornando gli indici e le statistiche di distribuzione delle tabelle.
Se si dispone di tabelle nel lakehouse e si vuole poter eseguire query nel data warehouse, ma non apportare modifiche, con un data warehouse di Fabric, non è necessario copiare i dati dal lakehouse al data warehouse. È possibile eseguire query sui dati del lakehouse direttamente dal data warehouse usando l’esecuzione di query tra database.
Importante
L’uso delle tabelle del data warehouse di Fabric presenta attualmente alcune limitazioni. Per altre informazioni, vedere Tabelle nel data warehousing in Microsoft Fabric .