Valutare, distribuire e testare un modello di base ottimizzato
Quando si ottimizza un modello di base dal catalogo in Azure Machine Learning, è possibile valutare il modello e distribuirlo per testarlo e usarlo con facilità.
Valutare il modello ottimizzato
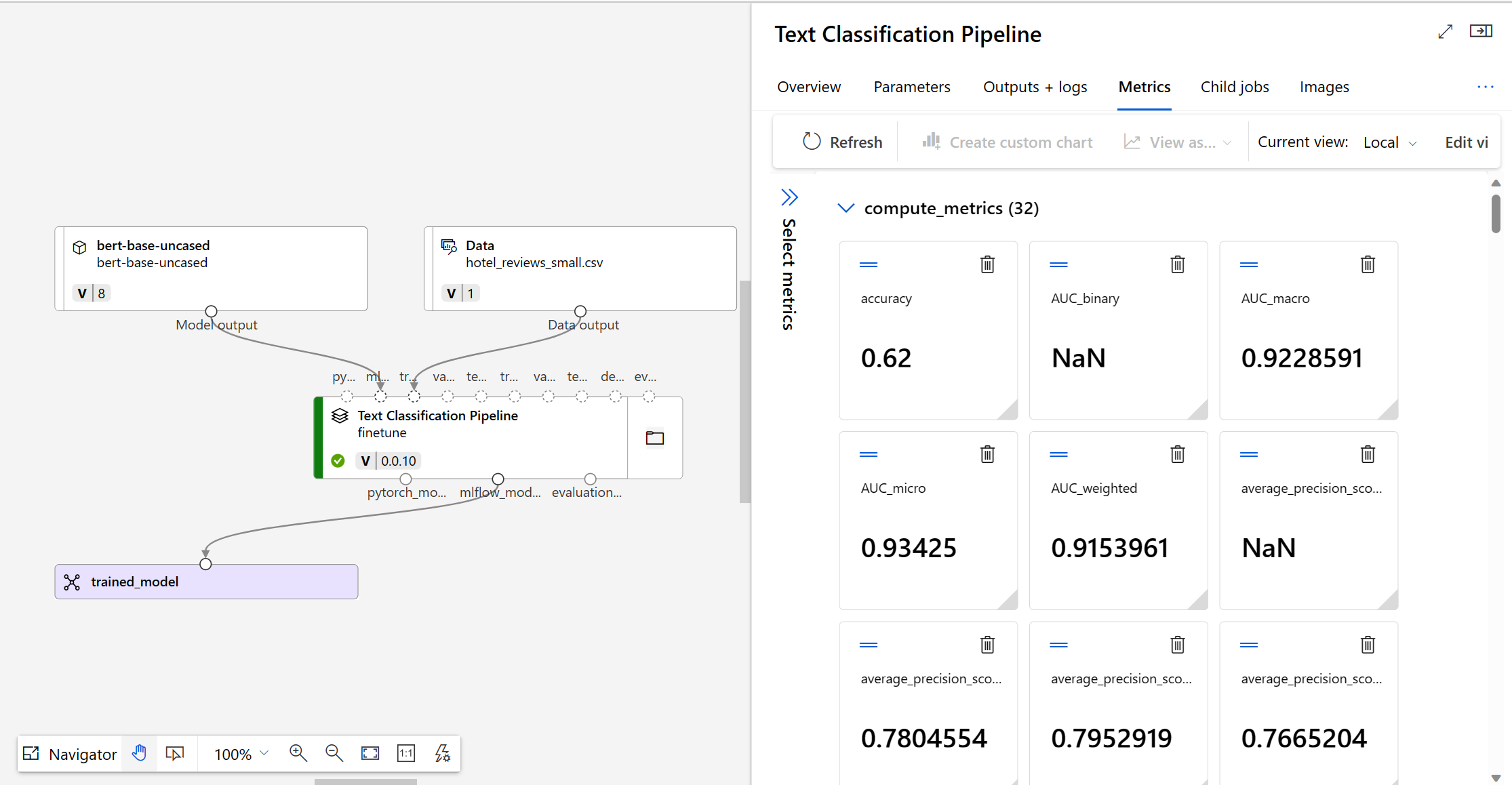
Per decidere se il modello ottimizzato viene eseguito come previsto, è possibile esaminare le metriche di training e valutazione.
Quando si invia un modello per l'ottimizzazione, Azure Machine Learning crea un nuovo processo della pipeline all'interno di un esperimento. Il processo della pipeline include un componente che rappresenta l'ottimizzazione completa del modello. È possibile analizzare i log, le metriche e gli output del processo selezionando il processo della pipeline completato ed esplorando di più selezionando il componente di ottimizzazione dettagliata specifico.
Suggerimento
In Azure Machine Learning vengono monitorate le metriche del modello con MLflow. Se si desidera accedere e rivedere le metriche a livello di codice, è possibile usare MLflow in un notebook Jupyter.
Distribuire il modello ottimizzato
Per testare e usare il modello ottimizzato, è possibile distribuire il modello in un endpoint.
Un endpoint in Azure Machine Learning è un'Application Programming Interface (API) che espone il modello sottoposto a training o ottimizzato, consentendo agli utenti o alle applicazioni di effettuare stime in base ai nuovi dati.
Esistono due tipi di endpoint in Azure Machine Learning:
- Endpoint in tempo reale: progettato per gestire stime immediate.
- Endpoint batch: ottimizzato per la gestione di un volume elevato di dati contemporaneamente.
Poiché gli endpoint in tempo reale consentono di ottenere stime immediate, sono ideali anche per testare le stime di un modello.
Registrare il modello usando lo studio di Azure Machine Learning
Per distribuire il modello ottimizzato usando la studio di Azure Machine Learning, è possibile usare l'output del processo di ottimizzazione completa.
Azure Machine Learning usa MLflow per tenere traccia dei processi e delle metriche e dei file di modello. Poiché MLflow è integrato con la studio di Azure Machine Learning, è possibile distribuire un modello da un processo con uno sforzo minimo.
Prima di tutto, è necessario registrare il modello dall'output del processo. Passare alla panoramica del processo per trovare l'opzione + Registra modello.
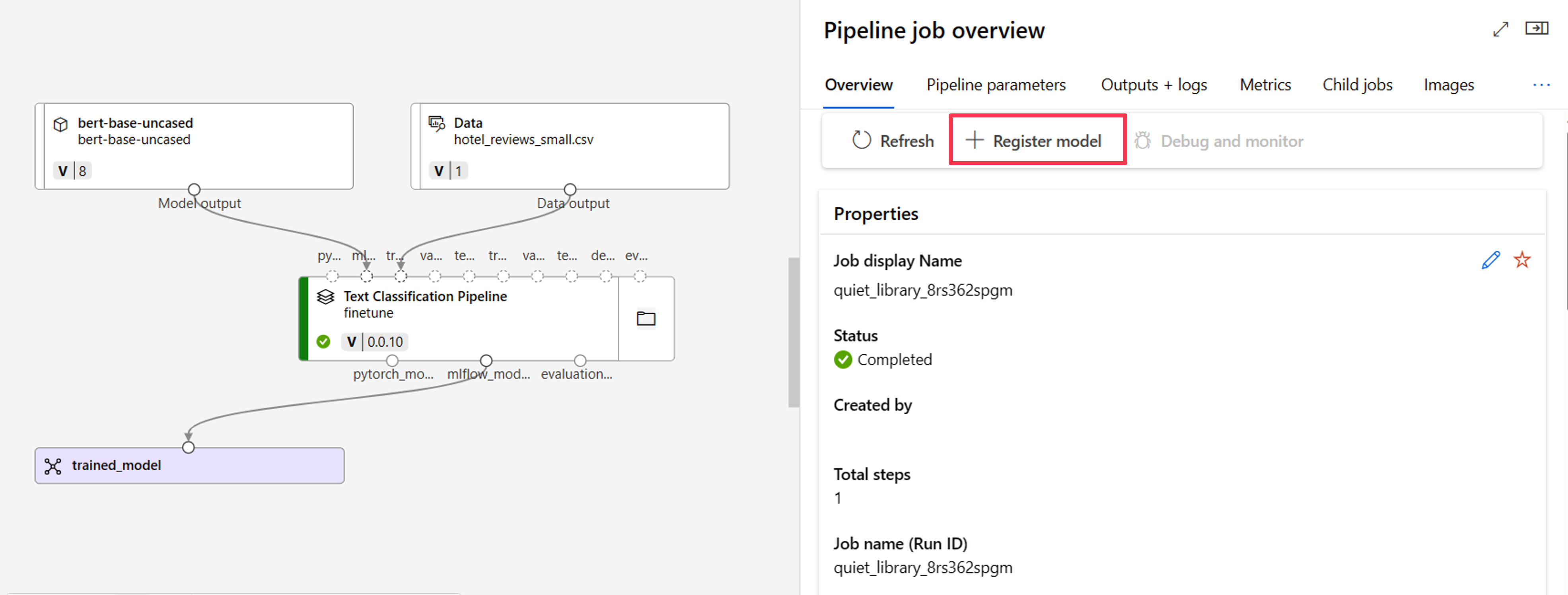
Il tipo di modello registrato è MLflow e Azure Machine Learning compila automaticamente la cartella contenente i file di modello. È necessario specificare un nome per il modello registrato e facoltativamente una versione.
Distribuire il modello usando lo studio di Azure Machine Learning
Dopo aver registrato il modello nell'area di lavoro di Azure Machine Learning, è possibile passare alla panoramica del modello e distribuirlo in un endpoint in tempo reale o batch.
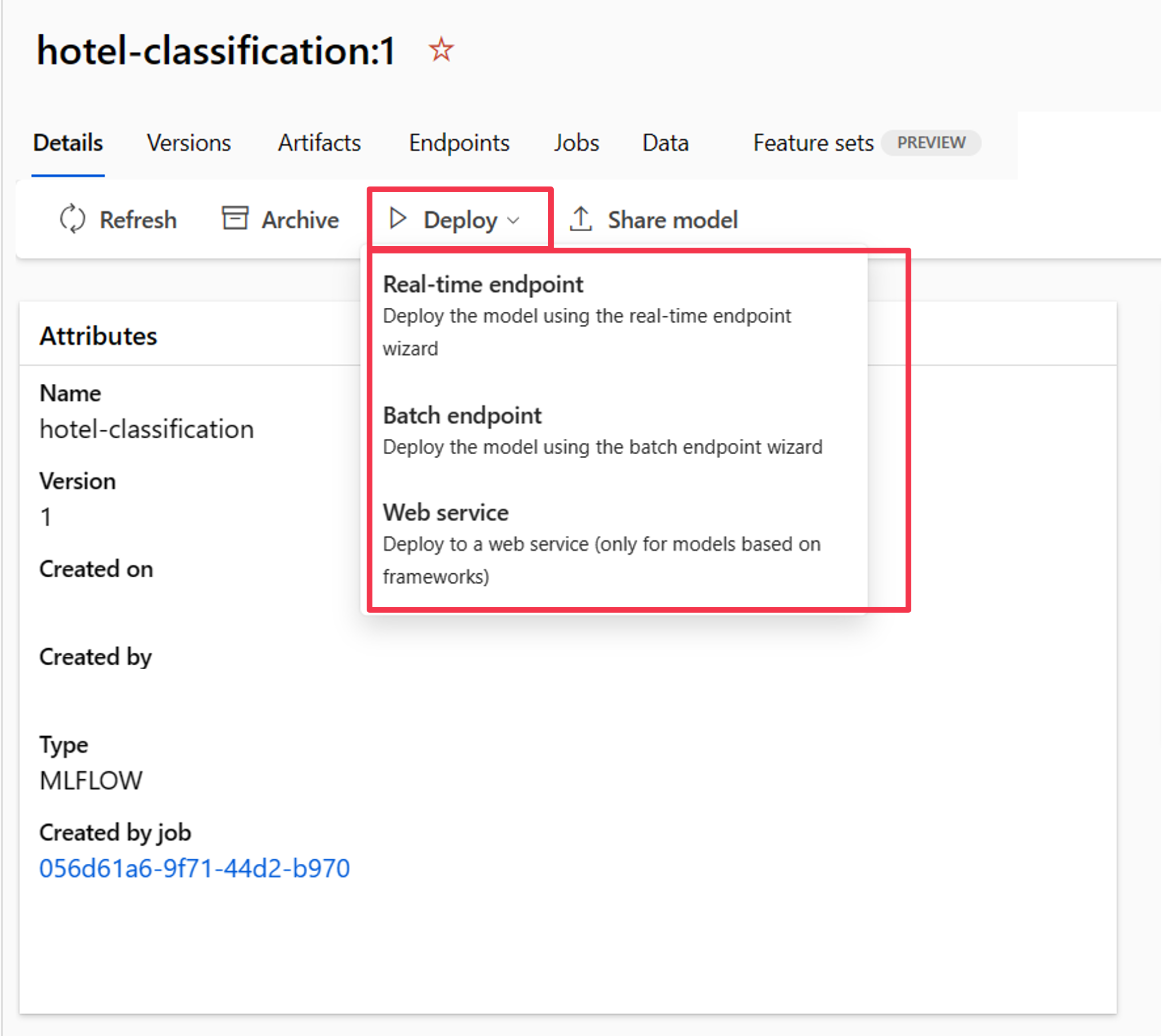
Ad esempio, è possibile distribuire il modello in un endpoint in tempo reale fornendo:
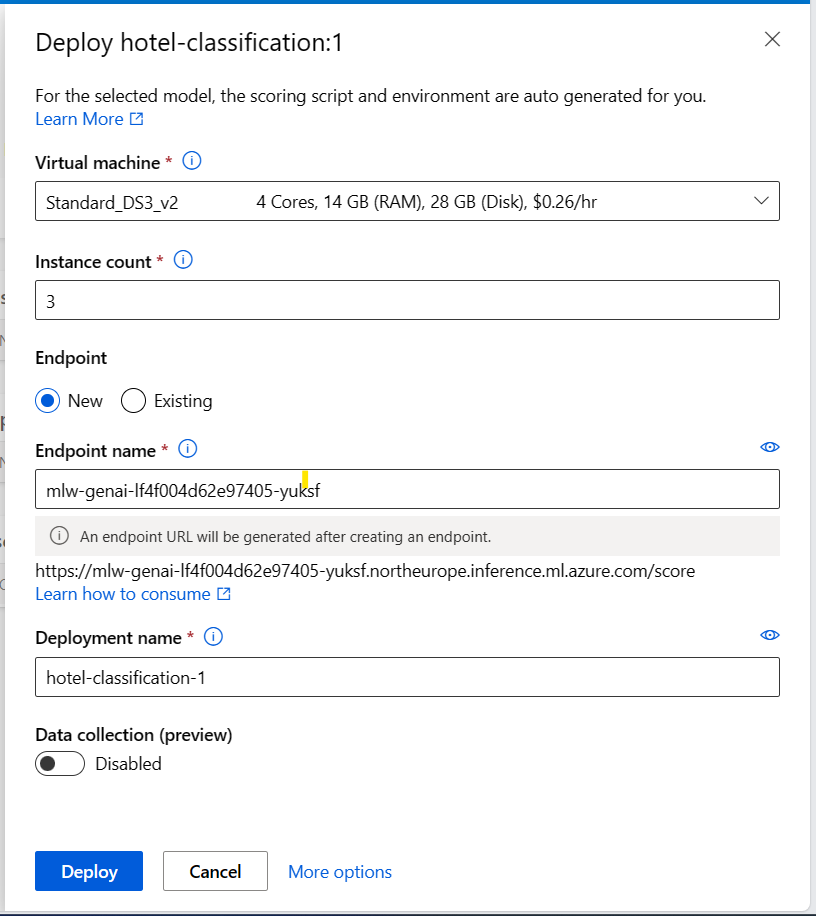
- Macchina virtuale: calcolo usato dall'endpoint.
- Numero di istanze: numero di istanze da usare per la distribuzione.
- Endpoint: distribuire il modello in un endpoint nuovo o esistente.
- Nome endpoint: usato per generare l'URL dell'endpoint.
- Nome della distribuzione: nome del modello distribuito nell'endpoint.
Nota
È possibile distribuire più modelli nello stesso endpoint. La creazione dell'endpoint e la distribuzione di un modello in un endpoint richiederanno tempo. Attendere fino a quando sia l'endpoint che la distribuzione sono pronti prima di provare o usare il modello distribuito.
Testare il modello nel studio di Azure Machine Learning
Quando il modello viene distribuito in un endpoint in tempo reale, è possibile testarlo rapidamente nello studio di Azure Machine Learning.
Passare all'endpoint ed esplorare la scheda Test.
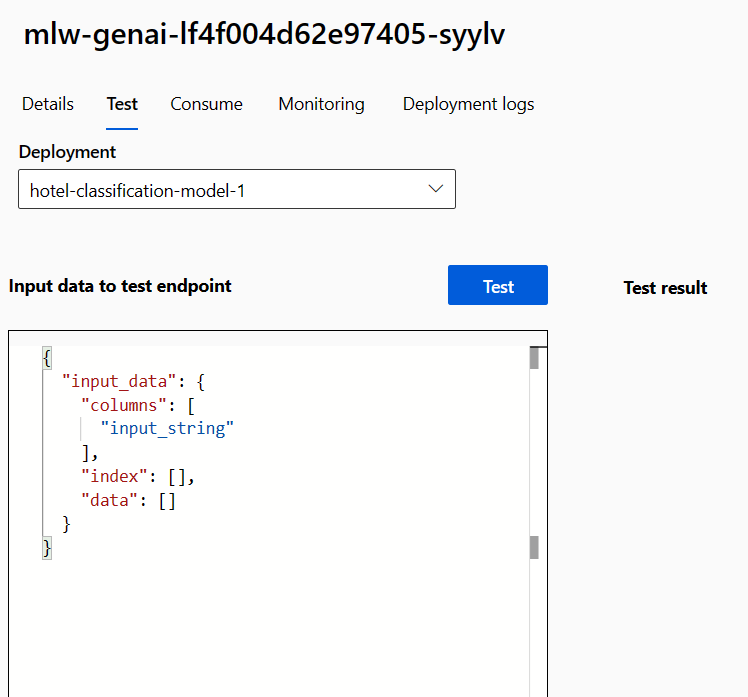
Poiché l'endpoint in tempo reale funziona come API, si prevede che i dati di input siano in formato JSON. Un esempio dell'output previsto viene fornito nella scheda Test:
{
"input_data": {
"columns": [
"input_string"
],
"index": [],
"data": []
}
}
Il formato dei dati di test deve essere simile ai dati di training, esclusa la colonna etichetta. Ad esempio, quando si vuole testare un modello ottimizzato per la classificazione del testo, è necessario specificare una colonna per l'endpoint, in questo caso la frase da classificare:
{
"input_data": {
"columns": [
"input_string"
],
"index": [0, 1],
"data": [["This would be the first sentence you want to classify."], ["This would be the second sentence you want to classify."]]
}
}
È possibile immettere tutti i dati di test nello studio e selezionare Test per inviare i dati all'endpoint. Il risultato viene visualizzato quasi immediatamente in Risultato test.
Suggerimento
Se non si trova la risposta prevista in Risultato test, la causa più probabile è che il formato dei dati di input non sia corretto. Lo script di assegnazione dei punteggi viene generato automaticamente quando si distribuisce un modello MLflow, il che significa che il formato dei dati di input deve essere simile ai dati di training (esclusa la colonna etichetta).