Esplorare le tabelle di Azure
Archiviazione tabelle di Azure è una soluzione di archiviazione NoSQL che usa tabelle contenenti elementi di dati con coppie chiave-valore. Ogni elemento è rappresentato da una riga che contiene le colonne relative ai campi dati che devono essere archiviati.
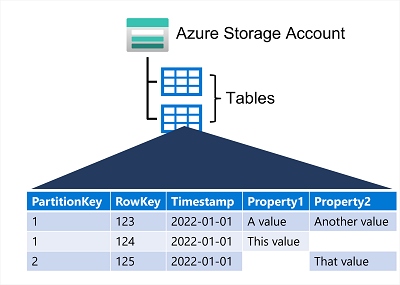
Tuttavia, non farsi confondere da questa terminologia pensando che una tabella di Archiviazione tabelle di Azure sia simile a una tabella di un database relazionale. Una tabella di Azure consente di archiviare dati semistrutturati. Tutte le righe in una tabella devono avere una chiave univoca (composta da una chiave di partizione e una chiave di riga) e quando si modificano i dati in una tabella, una colonna timestamp registra la data e l'ora in cui è stata apportata la modifica; ma a parte questo, le colonne in ogni riga possono variare. Le tabelle di Archiviazione tabelle di Azure non includono alcun concetto di chiavi esterne, relazioni, stored procedure, visualizzazioni o altri oggetti che potrebbero essere presenti in un database relazionale. I dati di Archiviazione tabelle di Azure sono in genere denormalizzati, ovvero ogni riga contiene tutti i dati relativi a un'entità logica. Una tabella che contiene le informazioni sui clienti, ad esempio, potrebbe archiviare i valori di nome, cognome, uno o più numeri di telefono e uno o più indirizzi per ogni cliente. Il numero di campi in ogni riga può variare a seconda del numero dei numeri di telefono e degli indirizzi per ogni cliente e dei dettagli memorizzati per ogni indirizzo. In un database relazionale, queste informazioni verrebbero suddivise tra più righe in più tabelle.
Per garantire un accesso rapido, Archiviazione tabelle di Azure suddivide una tabella in partizioni. Il partizionamento è un meccanismo per raggruppare righe correlate in base a una proprietà comune o a una chiave di partizione comune. Le righe che condividono la stessa chiave di partizione verranno archiviate insieme. Il partizionamento non solo consente di organizzare i dati, ma può anche migliorare la scalabilità e le prestazioni nei modi seguenti:
Le partizioni sono indipendenti l'una dall'altra e possono essere aumentate o ridotte man mano che le righe vengono aggiunte o rimosse da una partizione. Una tabella può contenere un numero qualsiasi di partizioni.
Quando si esegue la ricerca di dati, è possibile includere la chiave di partizione nei criteri di ricerca. Questo consente di limitare il volume dei dati da esaminare e di migliorare le prestazioni riducendo la quantità di I/O (operazioni di input e output o di lettura e scrittura) necessarie per individuare i dati.
La chiave in una tabella di Archiviazione tabelle di Azure è costituita da due elementi: la chiave di partizione che identifica la partizione contenente la riga e una chiave di riga univoca per ogni riga nella stessa partizione. Gli elementi nella stessa partizione vengono archiviati in base all'ordine delle chiavi di riga. Se un'applicazione aggiunge una nuova riga a una tabella, Azure garantisce che la riga si trovi nella posizione corretta nella tabella. Questo schema consente a un'applicazione di eseguire rapidamente query su un punto che identificano una singola riga e query sull'intervallo che recuperano un blocco contiguo di righe in una partizione.