Progettare uno schema del data warehouse
Come tutti i database relazionali, un data warehouse contiene tabelle in cui vengono archiviati i dati da analizzare. Più comunemente, queste tabelle sono organizzate in uno schema ottimizzato per la modellazione multidimensionale, in cui le misure numeriche associate agli eventi noti come fatti possono essere aggregate in base agli attributi delle entità associate su più dimensioni. Ad esempio, le misure associate a un ordine di vendita, come l'importo pagato o la quantità di articoli ordinati, possono essere aggregate dagli attributi della data in cui si è verificata la vendita, del cliente, del negozio e così via.
Tabelle in un data warehouse
Un modello comune per i data warehouse relazionali consiste nella definizione di uno schema che include tabelle di due tipi: delle dimensioni e dei fatti.
Tabelle delle dimensioni
Le tabelle delle dimensioni descrivono le entità aziendali, ad esempio prodotti, persone, luoghi e date. Le tabelle delle dimensioni contengono colonne per gli attributi di un'entità. Un'entità cliente, ad esempio, può avere un nome, un cognome, un indirizzo di posta elettronica e un indirizzo postale (che può includere una strada, una città, un codice postale e un paese o un'area geografica). Oltre alle colonne di attributo, una tabella delle dimensioni contiene una colonna chiave che identifica in modo univoco ogni riga nella tabella. Di fatto, una tabella delle dimensioni include comunemente due colonne chiave:
- Una chiave sostitutiva, specifica per il data warehouse, che identifica in modo univoco ogni riga nella tabella delle dimensioni nel data warehouse, in genere costituita da un numero intero incrementale.
- Una chiave alternativa, spesso di tipo naturale o business, usata per identificare un'istanza specifica di un'entità nel sistema transazionale da cui ha origine il record dell'entità, ad esempio un codice prodotto o un ID cliente.
Nota
Perché avere due chiavi? Esistono alcuni motivi validi per questo:
- Il data warehouse può essere popolato con dati provenienti da più sistemi di origine, che possono causare il rischio di chiavi business duplicate o incompatibili.
- Le chiavi numeriche semplici offrono in genere prestazioni migliori nelle query che eseguono il join di molte tabelle, un modello comune nei data warehouse.
- Gli attributi delle entità possono cambiare nel tempo, ad esempio un cliente potrebbe cambiare indirizzo. Poiché il data warehouse viene usato per supportare la creazione di report cronologici, può essere opportuno conservare un record per ogni istanza di un'entità in più punti nel tempo. In questo modo, ad esempio, gli ordini di vendita per un determinato cliente vengono conteggiati per la città in cui viveva al momento dell'esecuzione dell'ordine. Nel caso specifico, più record del cliente avranno la stessa chiave business associata al cliente, ma chiavi sostitutive diverse per ogni indirizzo discreto in cui il cliente ha vissuto nei vari momenti nel corso del tempo.
Una tabella delle dimensioni di esempio per il cliente potrebbe contenere i dati seguenti:
| CustomerKey | CustomerAltKey | Nome | Via | City | PostalCode | CountryRegion | |
|---|---|---|---|---|---|---|---|
| 123 | I-543 | Navin Jones | navin1@contoso.com | 1 Main St. | Seattle | 90000 | Stati Uniti |
| 124 | R-589 | Mary Smith | mary2@contoso.com | 234 190th Ave | Buffalo | 50001 | Stati Uniti |
| 125 | I-321 | Antoine Dubois | antoine1@contoso.com | 2 Rue Jolie | Parigi | 20098 | Francia |
| 126 | I-543 | Navin Jones | navin1@contoso.com | 24 125th Ave. | New York | 50000 | Stati Uniti |
| ... | ... | ... | ... | ... | ... | ... | ... |
Nota
Si noti che la tabella contiene due record per Navin Jones. Entrambi i record usano la stessa chiave alternativa per identificare questa persona (I-543), ma ogni record ha una chiave sostitutiva diversa. In base a queste informazioni è possibile supporre che il cliente si sia trasferito da Seattle a New York. Le vendite effettuate al cliente mentre viveva a Seattle sono associate alla chiave 123, mentre gli acquisti effettuati dopo il trasferimento a New York sono registrati nel record 126.
Oltre alle tabelle delle dimensioni che rappresentano entità aziendali, spesso accade che un data warehouse includa una tabella delle dimensioni che rappresenta valori temporali. Questa tabella consente agli analisti dei dati di aggregare i dati in base a intervalli di tempo. A seconda del tipo di dati da analizzare, la granularità minima (ovvero il livello minimo di dettaglio) di una dimensione temporale potrebbe rappresentare valori di ora (ora, secondo, millisecondo, nanosecondo o anche unità inferiori) o data.
Un esempio di tabella delle dimensioni temporali con granularità a livello di data potrebbe contenere i dati seguenti:
| DateKey | DateAltKey | DayOfWeek | DayOfMonth | Giorno feriale | Mese | MonthName | Trimestre | Anno |
|---|---|---|---|---|---|---|---|---|
| 19990101 | 01-01-1999 | 6 | 1 | Venerdì | 1 | Gennaio | 1 | 1999 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 20220101 | 01-01-2022 | 7 | 1 | Sabato | 1 | Gennaio | 1 | 2022 |
| 20220102 | 02-01-2022 | 1 | 2 | Domenica | 1 | Gennaio | 1 | 2022 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 20301231 | 31-12-2030 | 3 | 31 | Martedì | 12 | dicembre | 4 | 2030 |
L'intervallo coperto dai record nella tabella deve includere i punti meno recenti e più recenti nel tempo per gli eventi associati registrati in una tabella dei fatti correlata. In genere è presente un record per ogni intervallo al livello di granularità appropriato.
Tabelle dei fatti
Nelle tabelle dei fatti vengono archiviati i dati relativi a osservazioni o eventi, ad esempio ordini di vendita, saldi azionari, tassi di cambio, temperature registrate. Una tabella dei fatti contiene colonne per i valori numerici che possono essere aggregati in base alle dimensioni. Oltre alle colonne numeriche, una tabella dei fatti contiene colonne chiave che fanno riferimento a chiavi univoche nelle tabelle delle dimensioni correlate.
Ad esempio, una tabella dei fatti contenente i dettagli degli ordini di vendita potrebbe contenere i dati seguenti:
| OrderDateKey | CustomerKey | StoreKey | ProductKey | NumeroOrdine | LineItemNo | Quantità | UnitPrice | Imposta | ItemTotal |
|---|---|---|---|---|---|---|---|---|---|
| 20220101 | 123 | 5 | 701 | 1001 | 1 | 2 | 2.50 | 0,50 | 5,50 |
| 20220101 | 123 | 5 | 765 | 1001 | 2 | 1 | 2.00 | 0,20 | 2,20 |
| 20220102 | 125 | 2 | 723 | 1002 | 1 | 1 | 4.99 | 0.49 | 5,48 |
| 20220103 | 126 | 1 | 823 | 1003 | 1 | 1 | 7,99 | 0.80 | 8,79 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
Le colonne chiave delle dimensioni di una tabella dei fatti ne determinano il grado di granularità. La tabella dei fatti degli ordini di vendita, ad esempio, include chiavi per date, clienti, negozi e prodotti. Un ordine può includere più prodotti, quindi il grado di granularità rappresenta gli articoli di linea per i singoli prodotti venduti ai clienti nei negozi in giorni specifici.
Opzioni di progettazione per uno schema del data warehouse
Nella maggior parte dei database transazionali usati nelle applicazioni aziendali, i dati vengono normalizzati per ridurre la duplicazione. In un data warehouse, tuttavia, i dati delle dimensioni vengono in genere denormalizzati per ridurre il numero di join necessari per eseguire query sui dati.
Un data warehouse è spesso organizzato come schema star, in cui una tabella dei fatti è direttamente correlata alle tabelle delle dimensioni, come illustrato in questo esempio:
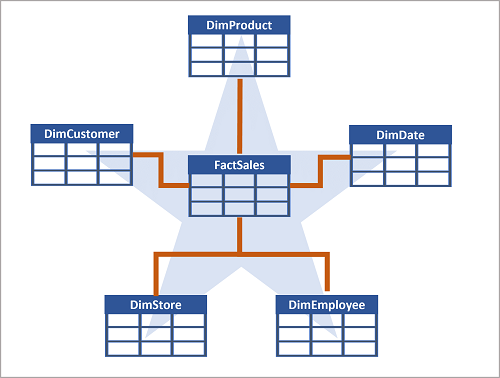
Gli attributi di un'entità possono essere usati per aggregare le misure nelle tabelle dei fatti su più livelli gerarchici, ad esempio per trovare i ricavi totali delle vendite per paese o area geografica, città, codice postale o singolo cliente. Gli attributi per ogni livello possono essere archiviati nella stessa tabella delle dimensioni. Tuttavia, quando un'entità ha un numero elevato di livelli di attributi gerarchici o quando alcuni attributi possono essere condivisi da più dimensioni, come nel caso in cui sia clienti che negozi hanno un indirizzo geografico, può essere opportuno applicare una normalizzazione alle tabelle delle dimensioni e creare uno schema snowflake, come illustrato nell'esempio seguente:
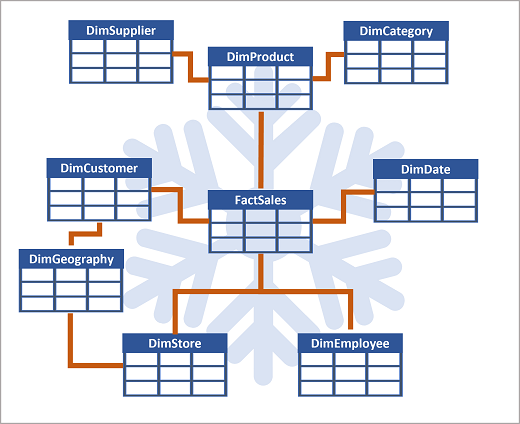
In questo caso, la tabella DimProduct è stata normalizzata per creare tabelle delle dimensioni separate per categorie di prodotti e fornitori e una tabella DimGeography è stata aggiunta per rappresentare gli attributi geografici relativi a clienti e negozi. Ogni riga nella tabella DimProduct contiene valori chiave per le righe corrispondenti nelle tabelle DimCategory e DimSupplier e ogni riga nelle tabelle DimCustomer e DimStore contiene un valore chiave per la riga corrispondente nella tabella DimGeography.