Progettare per il monitoraggio
Nell'ambito di un'architettura di machine learning operations (MLOps), è consigliabile considerare come monitorare la soluzione di Machine Learning.
Il monitoraggio è utile in qualsiasi ambiente MLOps. È necessario monitorare il modello, i datie l'infrastruttura per raccogliere le metriche che consentono di decidere i passaggi successivi necessari.
Monitorare il modello
In genere, si vuole monitorare le prestazioni del modello. Durante lo sviluppo si usa MLflow per eseguire il training e tenere traccia dei modelli di Machine Learning. A seconda del modello di cui si esegue il training, è possibile usare metriche diverse per valutare se il modello funziona come previsto.
Per monitorare un modello in produzione, è possibile usare il modello sottoposto a training per generare stime su un piccolo subset di nuovi dati in ingresso. Generando le metriche delle prestazioni su tali dati di test, è possibile verificare se il modello sta ancora raggiungendo l'obiettivo.
Inoltre, è anche possibile monitorare eventuali problemi di intelligenza artificiale (IA) responsabili. Ad esempio, se il modello esegue stime corrette.
Prima di poter monitorare un modello, è importante decidere quali metriche delle prestazioni monitorare e quale benchmark deve essere per ogni metrica. Quando si dovrebbe ricevere un avviso che indica che il modello non è più accurato?
Monitorare i dati
In genere si esegue il training di un modello di Machine Learning usando un set di dati cronologico rappresentativo dei nuovi dati che il modello riceverà quando distribuito. Tuttavia, nel corso del tempo potrebbero presentarsi tendenze che modificano il profilo dei dati, rendendo il modello meno accurato.
Si supponga ad esempio che un modello venga sottoposto a training per stimare il chilometraggio previsto di un'automobile in base al numero di cilindri, alle dimensioni del motore, al peso e ad altre caratteristiche. Nel tempo, con i progressi della produzione automobilistica e delle tecnologie motoristiche, la tipica efficienza dei consumi dei veicoli potrebbe migliorare sensibilmente; rendendo meno accurate le stime effettuate dal modello con training sui dati più obsoleti.
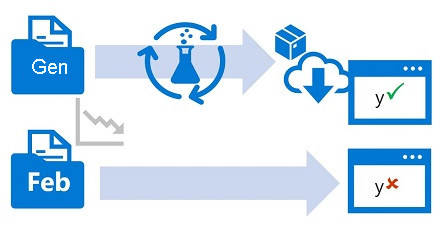
Questa modifica nei profili dati tra training e inferenza è nota come deriva dei dati e può costituire un problema significativo per i modelli predittivi usati nell'ambiente di produzione. È quindi importante poter monitorare la deriva nel tempo e ripetere il training dei modelli come richiesto per mantenere la precisione predittiva.
Monitorare l'infrastruttura
Accanto al monitoraggio del modello e dei dati, è anche necessario monitorare l'infrastruttura per ridurre al minimo i costi e ottimizzare le prestazioni.
In tutto il ciclo di vita di Machine Learning si usa il calcolo per eseguire il training e la distribuzione di modelli. Con i progetti di Machine Learning nel cloud, il calcolo può essere una delle spese maggiori. Si vuole quindi monitorare se si usa in modo efficiente il calcolo.
Ad esempio, è possibile monitorare l'utilizzo delle risorse di calcolo durante il training e durante la distribuzione. Esaminando l'utilizzo del calcolo, si sa se è possibile ridurre le prestazioni del calcolo di cui è stato effettuato il provisioning o se è necessario aumentare le istanze per evitare vincoli di capacità.
Suggerimento
Altre informazioni sul monitoraggio dell'area di lavoro di Azure Machine Learning e delle relative risorse.