Esplorare un'architettura MLOps
In qualità di data scientist, si vuole eseguire il training del modello di Machine Learning migliore. Per implementare il modello, si vuole distribuirlo in un endpoint e integrarlo con un'applicazione.
Nel corso del tempo, è possibile ripetere il training del modello. Ad esempio, è possibile ripetere il training del modello quando si dispone di più dati di training.
In generale, dopo aver eseguito il training di un modello di Machine Learning, si vuole preparare il modello per la scalabilità aziendale. Per preparare il modello e renderlo operativo, si vuole:
- Convertire il training del modello in una pipeline affidabile e riproducibile.
- Testare il codice e il modello in un ambiente di sviluppo.
- Distribuire il modello in un ambiente di produzione.
- Automatizzare l'intero processo.
Configurare gli ambienti per lo sviluppo e la produzione
All'interno di MLOps, in modo analogo a DevOps, un ambiente fa riferimento a una raccolta di risorse. Queste risorse vengono usate per distribuire un'applicazione o, con progetti di Machine Learning, per distribuire un modello.
Nota
In questo modulo si fa riferimento agli ambienti come sono intesi in DevOps. Si noti che anche Azure Machine Learning usa il termine ambienti per indicare una raccolta di pacchetti Python necessari per eseguire uno script. Questi due concetti di ambienti sono indipendenti tra loro.
Il numero di ambienti con cui si lavora dipende dall'organizzazione. In genere, esistono almeno due ambienti: sviluppo o dev e produzione o prodÈ anche possibile aggiungere altri ambienti tra l'uno e l'altro, ad esempio un ambiente di gestione temporanea o di pre-produzione (pre-prod).
Un approccio tipico consiste nel:
- Sperimentare il training del modello nell'ambiente di sviluppo.
- Spostare il modello migliore nell'ambiente di gestione temporanea o pre-produzione per distribuirlo e testarlo.
- Infine rilasciare il modello nell'ambiente di produzione per distribuirlo in modo che gli utenti finali possano utilizzarlo.
Organizzare gli ambienti di Azure Machine Learning
Quando si implementa MLOps e si lavora con i modelli di Machine Learning su larga scala, è consigliabile usare ambienti separati per ogni fase.
Si supponga che il team usi un ambiente di sviluppo, di pre-produzione e di produzione. Non tutti gli utenti del team devono poter accedere a tutti gli ambienti. I data scientist, ad esempio, possono lavorare solo nell'ambiente di sviluppo con dati non di produzione, mentre i tecnici di Machine Learning possono lavorare sulla distribuzione del modello nell'ambiente di pre-produzione e di produzione con i dati di produzione.
Disponendo di ambienti separati sarà più facile controllare l'accesso alle risorse. Ogni ambiente può quindi essere associato a un'area di lavoro separata di Azure Machine Learning.
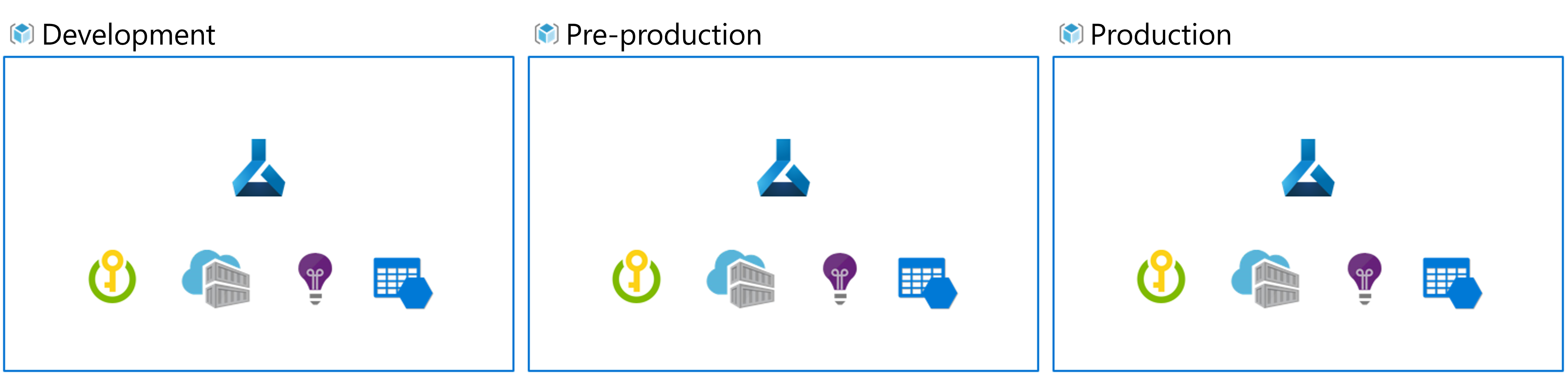
In Azure si userà il controllo degli accessi in base al ruolo per concedere ai colleghi il livello di accesso appropriato al subset di risorse con cui devono lavorare.
In alternativa, è possibile usare una sola area di lavoro di Azure Machine Learning. Quando si usa una sola area di lavoro per lo sviluppo e la produzione, si avrà un footprint di Azure minore e un sovraccarico di gestione inferiore. Il controllo degli accessi in base al ruolo si applica tuttavia sia allo sviluppo che alla produzione e quindi gli utenti potrebbero avere un accesso troppo limitato oppure eccessivo alle risorse.
Suggerimento
Altre informazioni sulle procedure consigliate per organizzare le risorse di Azure Machine Learning.
Progettare un'architettura MLOps
Portare un modello in produzione significa dimensionare la soluzione e collaborare con altri team. Insieme a scienziati dei dati, ingegneri dei dati e team dell'infrastruttura, si è deciso di usare l'approccio seguente:
- Archiviare tutti i dati in un archivio BLOB di Azure, gestito dal data engineer.
- Il team dell'infrastruttura creerà le risorse di Azure necessarie, ad esempio l'area di lavoro di Azure Machine Learning.
- I data scientist si concentrano sulle prestazioni migliori: lo sviluppo e il training del modello (ciclo interno).
- I tecnici di Machine Learning distribuiscono i modelli sottoposti a training (ciclo esterno).
Di conseguenza, l'architettura MLOps include le parti seguenti:
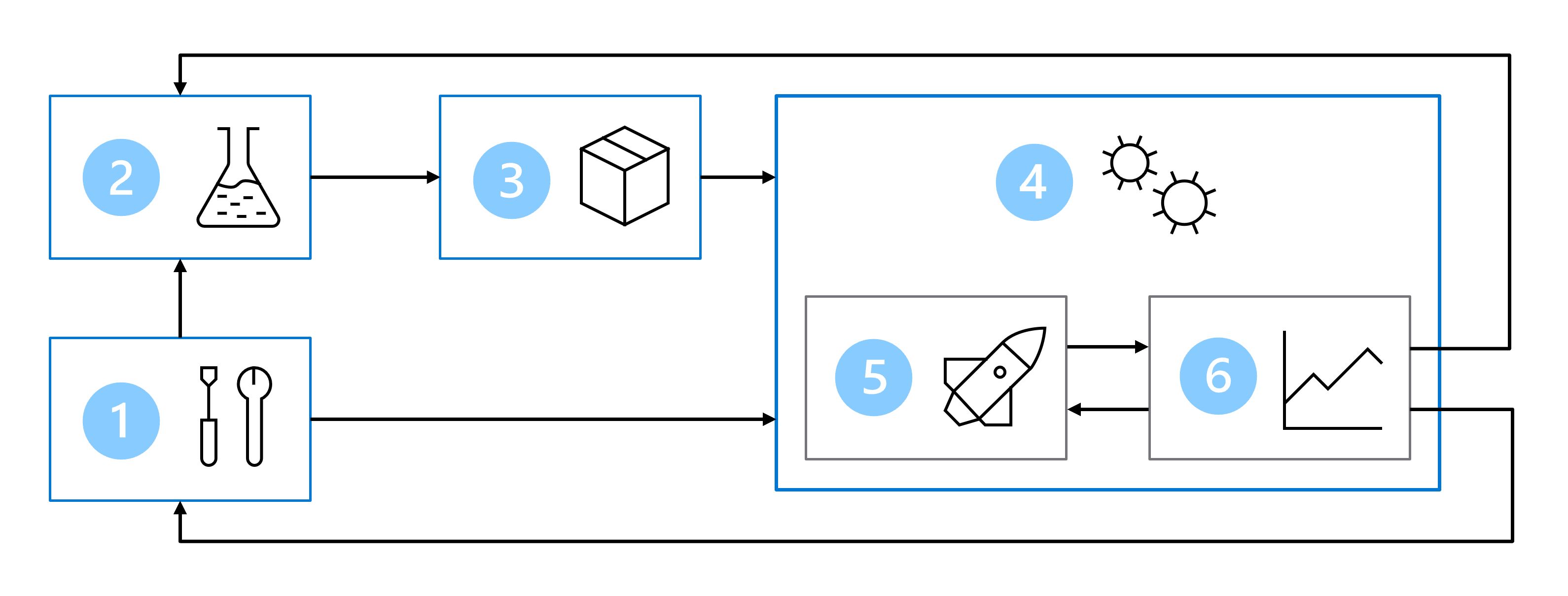
- Configurazione: creare tutte le risorse di Azure necessarie per la soluzione.
- Sviluppo del modello (ciclo interno): esplorare ed elaborare i dati per eseguire il training e la valutazione del modello.
- Integrazione continua: creare un pacchetto del modello e registrarlo.
- Distribuzione del modello (ciclo esterno): distribuire il modello.
- Distribuzione continua: testare il modello e promuoverlo nell'ambiente di produzione.
- Monitoraggio: monitorare le prestazioni del modello e dell'endpoint.
Quando si lavora con team di grandi dimensioni, non si prevede di essere responsabili di tutte le parti dell'architettura MLOps come data scientist. Per preparare il modello per MLOps, tuttavia, è necessario considerare come progettare per il monitoraggio e la ripetizione del training.