Descrivere Collegamento ad Azure Synapse
Le soluzioni HTAP sono supportate in Azure Synapse Analytics tramite Collegamento ad Azure Synapse, termine generale che definisce un set di servizi collegati che supportano la sincronizzazione dei dati HTAP nell'area di lavoro Azure Synapse Analytics.
Collegamento a Synapse di Azure per Cosmos DB
Azure Cosmos DB è un servizio dati NoSQL su scala globale in Microsoft Azure che consente alle applicazioni di archiviare e accedere ai dati operativi usando diverse API (Application Programming Interface).
Collegamento ad Azure Synapse per Azure Cosmos DB è una funzionalità HTAP nativa del cloud che consente di eseguire analisi near real-time sui dati operativi archiviati in un contenitore Cosmos DB. Collegamento ad Azure Synapse crea una stretta integrazione tra Azure Cosmos DB e Azure Synapse Analytics.
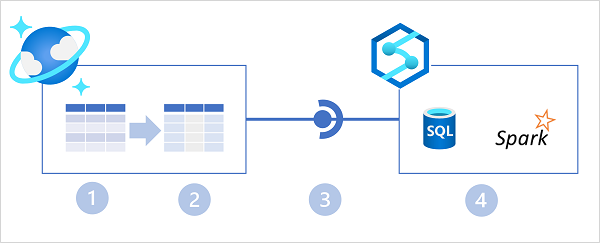
Nel diagramma precedente sono illustrate le funzionalità principali seguenti dell'architettura di Collegamento ad Azure Synapse per Cosmos DB:
- Un contenitore di Azure Cosmos DB offre un archivio transazionale basato su righe ottimizzato per le operazioni di lettura/scrittura.
- Il contenitore fornisce anche un archivio analitico basato su colonne ottimizzato per i carichi di lavoro analitici. Un processo di sincronizzazione automatica completamente gestito mantiene sincronizzati gli archivi dati.
- Collegamento ad Azure Synapse fornisce un servizio collegato che connette il contenitore abilitato per l'archivio analitico in Azure Cosmos DB a un'area di lavoro di Azure Synapse Analytics.
- Azure Synapse Analytics offre runtime Synapse SQL e Apache Spark in cui è possibile eseguire codice per recuperare, elaborare e analizzare i dati dall'archivio analitico di Azure Cosmos DB senza influire sull'archivio dati transazionale in Azure Cosmos DB.
Collegamento ad Azure Synapse per SQL
Microsoft SQL Server è un sistema di database relazionale popolare che supporta le applicazioni aziendali in alcune delle più grandi organizzazioni del mondo. Il database SQL di Azure è una soluzione di database PaaS (Platform-as-a-Service) basata sul cloud per SQL Server. Entrambe queste soluzioni di database relazionale vengono comunemente usate come archivi dati operativi.
Collegamento ad Azure Synapse per SQL abilita l'integrazione HTAP tra i dati in SQL Server o nel database SQL di Azure e un'area di lavoro Azure Synapse Analytics.
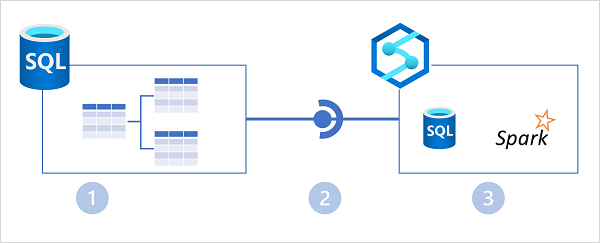
Nella figura precedente sono illustrate le funzionalità principali seguenti dell'architettura di Collegamento ad Azure Synapse:
- Un database SQL di Azure o un'istanza di SQL Server contiene un database relazionale in cui i dati transazionali vengono archiviati nelle tabelle.
- Collegamento ad Azure Synapse per SQL replica i dati della tabella in un pool SQL dedicato in un'area di lavoro Azure Synapse.
- I dati replicati nel pool SQL dedicato possono essere sottoposti a query nel pool SQL dedicato o connessi come origine esterna da un pool di Spark senza alcun impatto sul database di origine.
Azure Synapse Link for Dataverse
Microsoft Dataverse è servizio di archiviazione dati all'interno di Microsoft Power Platform. È possibile usare Dataverse per archiviare i dati aziendali in tabelle accessibili da Power Apps, Power BI, Power Virtual Agents e altri servizi e applicazioni in Microsoft 365, Dynamics 365 e Azure.
Collegamento ad Azure Synapse per Dataverse consente l'integrazione HTAP replicando i dati della tabella in Azure Data Lake Storage, dove i runtime in Azure Synapse Analytics possono accedere ai dati, direttamente dal data lake o tramite un database Lake definito in un pool SQL serverless.
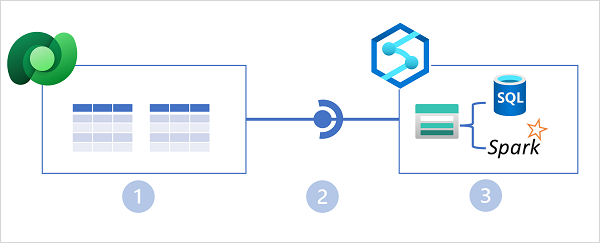
Nella figura precedente sono illustrate le funzionalità principali seguenti dell'architettura di Collegamento ad Azure Synapse per Dataverse:
- Le applicazioni aziendali archiviano i dati nelle tabelle di Microsoft Dataverse.
- Collegamento ad Azure Synapse per Dataverse replica i dati della tabella in un account di archiviazione di Azure Data Lake Gen2 associato a un'area di lavoro di Azure Synapse.
- I dati nel data lake possono essere usati per definire tabelle in un database Lake ed eseguire query usando un pool SQL serverless oppure leggere direttamente dall'archiviazione usando SQL o Spark.