Esplorare prestazioni e sicurezza
L'ecosistema di Azure offre diverse opzioni di prestazioni e sicurezza per l'istanza di SQL Server nella macchina virtuale di Azure. Ogni opzione offre diverse funzionalità, ad esempio tipi di disco differenti che soddisfano i requisiti di capacità e prestazioni del carico di lavoro.
Considerazioni sulle risorse di archiviazione
Per fornire prestazioni affidabili per quanto riguarda le applicazioni, SQL Server richiede buone prestazioni di archiviazione, sia che si tratti di un'istanza locale o che sia installato in una macchina virtuale di Azure. Azure offre un'ampia gamma di soluzioni di archiviazione per soddisfare le esigenze del carico di lavoro. Sebbene Azure offra diversi tipi di archiviazione (BLOB, file, coda e tabella), nella maggior parte dei casi i carichi di lavoro di SQL Server usano i dischi gestiti di Azure. Le eccezioni sono un'istanza del cluster di failover che può essere basata sull'archiviazione file e i backup che usano l'archiviazione BLOB. I dischi gestiti di Azure agiscono come dispositivo di archiviazione a livello di blocco che viene presentato alla macchina virtuale di Azure. I dischi gestiti offrono numerosi vantaggi, tra cui la disponibilità del 99,999%, la distribuzione scalabile (possono essere presenti fino a 50.000 dischi di macchina virtuale per ogni sottoscrizione per area geografica) e l'integrazione con i set e le zone di disponibilità per offrire livelli di resilienza più elevati in caso di errore.
Tutti i dischi gestiti di Azure offrono due tipi di crittografia. La crittografia lato server di Azure viene fornita dal servizio di archiviazione e funge da crittografia dei dati inattivi fornita dal servizio di archiviazione. Crittografia dischi di Azure usa BitLocker in Windows e DM-Crypt in Linux per fornire la crittografia del sistema operativo e del disco dati all'interno della macchina virtuale. Entrambe le tecnologie si integrano con Azure Key Vault e consentono all'utente di portare la propria chiave di crittografia.
A ogni macchina virtuale saranno associati almeno due dischi:
Disco del sistema operativo: per ogni macchina virtuale è necessario un disco del sistema operativo contenente il volume di avvio. Questo disco è l'unità C: nel caso di una macchina virtuale della piattaforma Windows oppure /dev/sda1 in Linux. Il sistema operativo viene installato automaticamente nel disco del sistema operativo.
Disco temporaneo: in ogni macchina virtuale è incluso un disco usato per l'archiviazione temporanea. Questa risorsa di archiviazione è destinata a essere usata per i dati non permanenti, ad esempio i file di paging o di scambio. Poiché il disco è temporaneo, non è consigliabile usarlo per archiviare informazioni critiche, ad esempio file di database o file registro transazioni, perché vanno perse durante la manutenzione o il riavvio della macchina virtuale. Questa unità viene montata come disco D:\ in Windows e /dev/sdb1 in Linux.
Inoltre, è possibile e opportuno aggiungere altri dischi dati alle macchine virtuali di Azure che eseguono SQL Server.
- Dischi dati: il termine disco dati viene usato nel portale di Azure, ma in pratica si tratta solo di dischi gestiti supplementari aggiunti a una macchina virtuale. Questi dischi possono essere raggruppati in pool per aumentare le operazioni di I/O al secondo e la capacità di archiviazione disponibili usando spazi di archiviazione in Windows o la gestione dei volumi logici in Linux.
Inoltre, ogni disco può essere di uno dei tipi seguenti:
| Funzionalità | Disco Ultra | SSD Premium | SSD Standard | Unità disco rigido Standard |
|---|---|---|---|---|
| Tipo di disco | SSD | SSD | SSD | HDD |
| Ideale per | Carico di lavoro con elevata attività di I/O | Carico di lavoro con requisiti particolari di prestazioni | Carichi di lavoro leggeri | Carichi di lavoro di backup non critici |
| Dimensioni massime disco | 65.536 GiB | 32.767 GiB | 32.767 GiB | 32.767 GiB |
| Velocità effettiva massima | 2.000 MB/s | 900 MB/s | 750 MB/s | 500 MB/s |
| Operazioni di I/O al secondo max | 160.000 | 20.000 | 6.000 | 2.000 |
Le procedure consigliate per SQL Server in Azure prevedono l'uso di dischi Premium in pool per aumentare le operazioni di I/O al secondo e la capacità di archiviazione. I file di dati devono essere archiviati nel rispettivo pool con memorizzazione nella cache di lettura nei dischi di Azure.
I file registro transazioni non traggono vantaggio dalla memorizzazione nella cache, quindi devono essere inseriti nel rispettivo pool senza memorizzazione nella cache. TempDB può facoltativamente essere inserito nel rispettivo pool o usare il disco temporaneo della macchina virtuale, che offre bassa latenza poiché è fisicamente collegato al server fisico in cui sono in esecuzione le macchine virtuali. Il disco SSD Premium configurato correttamente visualizzerà la latenza in pochi millisecondi. Per i carichi di lavoro cruciali che richiedono una latenza inferiore è opportuno provare a usare il disco Ultra SSD.
Considerazioni relative alla sicurezza
Esistono diversi standard e normative del settore conformi ad Azure che consentono di creare una soluzione conforme a SQL Server in esecuzione su una macchina virtuale.
Microsoft Defender per SQL
Microsoft Defender per SQL offre funzionalità del Centro sicurezza di Azure, ad esempio valutazioni della vulnerabilità e avvisi di sicurezza.
Azure Defender per SQL può essere usato per identificare e attenuare potenziali vulnerabilità nel database e nell'istanza di SQL Server. La funzionalità di valutazione della vulnerabilità può rilevare potenziali rischi nell'ambiente di SQL Server e contribuire a correggerli. Fornisce inoltre dati analitici sullo stato della sicurezza e azioni utili per risolvere i problemi di sicurezza.
Centro sicurezza di Azure
Centro sicurezza di Azure è un sistema di gestione della sicurezza unificato che valuta e offre opportunità per migliorare diversi aspetti legati alla sicurezza dell'ambiente dati. Centro sicurezza di Azure offre anche una panoramica completa dell'integrità della sicurezza di tutte le risorse cloud ibride.
Considerazioni sulle prestazioni
La maggior parte delle funzionalità per le prestazioni locali esistenti di SQL Server è disponibile anche nelle macchine virtuali di Azure. Tra le opzioni offerte è presente la compressione dei dati, che può migliorare le prestazioni dei carichi di lavoro con elevata attività di I/O, riducendo le dimensioni del database. In modo analogo, il partizionamento di tabelle e indici può migliorare le prestazioni delle query di tabelle di grandi dimensioni, migliorando le prestazioni e la scalabilità.
Partizionamento delle tabelle
Il partizionamento delle tabelle offre molti vantaggi, ma spesso questa strategia viene presa in considerazione solo quando la tabella diventa abbastanza grande da iniziare a compromettere le prestazioni delle query. L'identificazione delle tabelle candidate per il partizionamento è una procedura consigliata che può comportare un numero minore di interruzioni e interventi. Quando si filtrano i dati tramite la colonna di partizione, viene eseguito l'accesso solo a un subset dei dati, non all'intera tabella. In modo analogo, le operazioni di manutenzione in una tabella partizionata riducono la durata della manutenzione stessa, ad esempio comprimendo dati specifici in una determinata partizione o ricompilando partizioni specifiche di un indice.
Per definire una partizione di tabella sono necessari quattro passaggi principali:
- Creazione di filegroup, per definire i file coinvolti quando vengono create le partizioni.
- Creazione della funzione di partizione, per definire le regole di partizione in base alla colonna specificata.
- Creazione dello schema di partizione, per definire il filegroup di ogni partizione.
- Tabella da partizionare.
L'esempio seguente illustra come creare una funzione di partizione per il 1° gennaio 2021 fino al 1° dicembre 2021 e come distribuire le partizioni tra filegroup diversi.
-- Partition function
CREATE PARTITION FUNCTION PartitionByMonth (datetime2)
AS RANGE RIGHT
-- The boundary values defined is the first day of each month, where the table will be partitioned into 13 partitions
FOR VALUES ('20210101', '20210201', '20210301',
'20210401', '20210501', '20210601', '20210701',
'20210801', '20210901', '20211001', '20211101',
'20211201');
-- The partition scheme below will use the partition function created above, and assign each partition to a specific filegroup.
CREATE PARTITION SCHEME PartitionByMonthSch
AS PARTITION PartitionByMonth
TO (FILEGROUP1, FILEGROUP2, FILEGROUP3, FILEGROUP4,
FILEGROUP5, FILEGROUP6, FILEGROUP7, FILEGROUP8,
FILEGROUP9, FILEGROUP10, FILEGROUP11, FILEGROUP12);
-- Creates a partitioned table called Order that applies PartitionByMonthSch partition scheme to partition the OrderDate column
CREATE TABLE Order ([Id] int PRIMARY KEY, OrderDate datetime2)
ON PartitionByMonthSch (OrderDate) ;
GO
Compressione dei dati
SQL Server offre diverse opzioni per comprimere i dati. Mentre SQL Server archivia ancora i dati compressi in pagine da 8 KB, quando i dati vengono compressi, è possibile archiviare più righe di dati in una determinata pagina in modo da consentire alla query di leggere un numero inferiore di pagine. La lettura di un numero inferiore di pagine offre due vantaggi: riduce la quantità di I/O fisico eseguito e consente di archiviare più righe nel pool di buffer, rendendo più efficiente l'uso della memoria. È consigliabile abilitare la compressione della pagina del database in base alle esigenze.
I compromessi per la compressione risiedono nel fatto che quest'ultima richiede un sovraccarico limitato della CPU, ma nella maggior parte dei casi i vantaggi di I/O di archiviazione superano in modo significativo qualsiasi utilizzo aggiuntivo del processore.
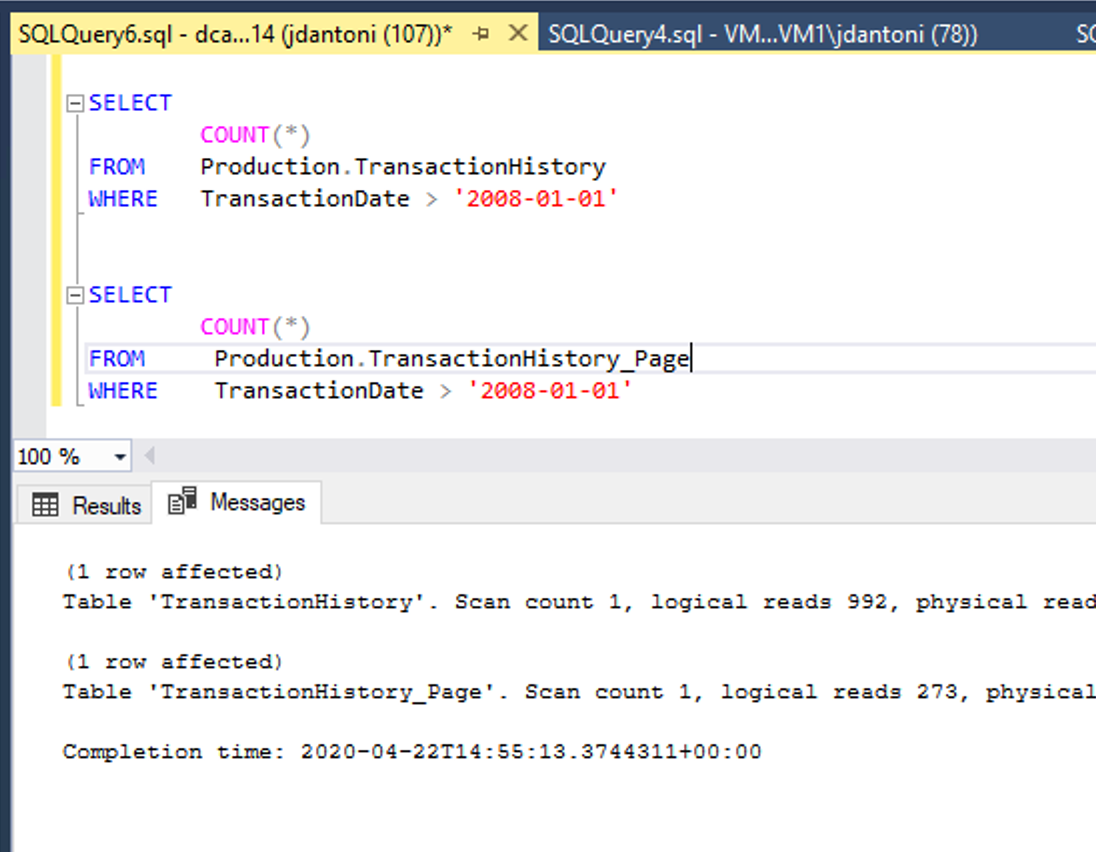
L'immagine precedente mostra i vantaggi in termini di prestazioni. Queste tabelle hanno gli stessi indici sottostanti e l'unica differenza consiste nel fatto che gli indici cluster e non cluster nella tabella Production.TransactionHistory_Page sono compressi in pagine. La query sull'oggetto pagina compressa esegue il 72% in meno di letture logiche rispetto alla query che usa gli oggetti non compressi.
La compressione è implementata in SQL Server a livello di oggetti. Ogni indice o tabella può essere compressa singolarmente ed è possibile scegliere di comprimere le partizioni all'interno di una tabella o di un indice partizionato. È possibile valutare la quantità di spazio che verrà risparmiata usando la stored procedure di sistema sp_estimate_data_compression_savings. Nelle versioni precedenti a SQL Server 2019, questa procedura non supportava gli indici columnstore o la compressione di archiviazione columnstore.
Compressione di riga: la compressione di riga è piuttosto semplice e non comporta un sovraccarico eccessivo, ma non offre lo stesso livello di compressione (misurato in base alla percentuale di riduzione dello spazio di archiviazione necessario) offerto dalla compressione di pagina. La compressione di riga archivia ogni valore in ogni colonna di una riga nella quantità minima di spazio necessario per archiviare il valore. Usa un formato di archiviazione a lunghezza variabile per i tipi di dati numerici, come integer, float e decimal, e archivia stringhe di caratteri a lunghezza fissa usando il formato a lunghezza variabile.
Compressione di pagina: la compressione di pagina è un superset della compressione di riga poiché tutte le pagine sono sottoposte inizialmente alla compressione di riga che consente di applicare poi la compressione di pagina. Viene quindi applicata ai dati una combinazione di tecniche chiamata compressione basata su prefisso e dizionario. La compressione basata su prefisso elimina i dati ridondanti in una singola colonna, archiviando i puntatori nell'intestazione di pagina. Dopo questa operazione, la compressione basata su dizionario cerca i valori ripetuti in una pagina e li sostituisce con i puntatori, riducendo ulteriormente lo spazio di archiviazione. Maggiore è la ridondanza dei dati, maggiore è il risparmio di spazio quando si comprimono i dati.
Compressione di archiviazione columnstore: gli oggetti columnstore sono sempre compressi, ma possono essere ulteriormente compressi tramite la compressione di archiviazione che usa l'algoritmo XPRESS di Microsoft sui dati. Questo tipo di compressione è ideale per i dati che vengono letti raramente, ma che devono essere conservati per motivi normativi o aziendali. Anche se questi dati vengono compressi ulteriormente, l'impegno della CPU per la decompressione tende a superare i miglioramenti alle prestazioni derivanti dalla riduzione dell'I/O.
Opzioni aggiuntive
Di seguito è riportato un elenco di funzionalità e azioni aggiuntive di SQL Server da prendere in considerazione per i carichi di lavoro di produzione:
- Abilitare la compressione del backup
- Abilitare l'inizializzazione immediata dei file di dati
- Limitare l'aumento automatico del database
- Disabilitare le funzioni autoshrink/autoclose per i database
- Spostare tutti i database su dischi dati, inclusi i database di sistema
- Spostare le directory dei file di traccia e dei log degli errori di SQL Server sui dischi dati
- Impostare il limite massimo di memoria per SQL Server
- Abilitare il blocco delle pagine nella memoria
- Abilitare l'ottimizzazione per carichi di lavoro ad hoc per ambienti OLTP pesanti
- Abilitare Query Store.
- Pianificare i processi di SQL Server Agent per eseguire DBCC CHECKDB, riorganizzare e ricompilare gli indici e aggiornare i processi di statistica
- Monitorare e gestire l'integrità e le dimensioni dei file di log delle transazioni
Per altre informazioni sulle procedure consigliate per le prestazioni, vedere Procedure consigliate per SQL Server in macchine virtuali di Azure.