Comprendere i componenti di Azure Data Factory
Una sottoscrizione di Azure può includere una o più istanze di Azure Data Factory. Azure Data Factory è costituito da quattro componenti chiave. Questi componenti forniscono la piattaforma nella quale è possibile comporre flussi di lavoro basati sui dati con passaggi per lo spostamento e la trasformazione dei dati stessi.
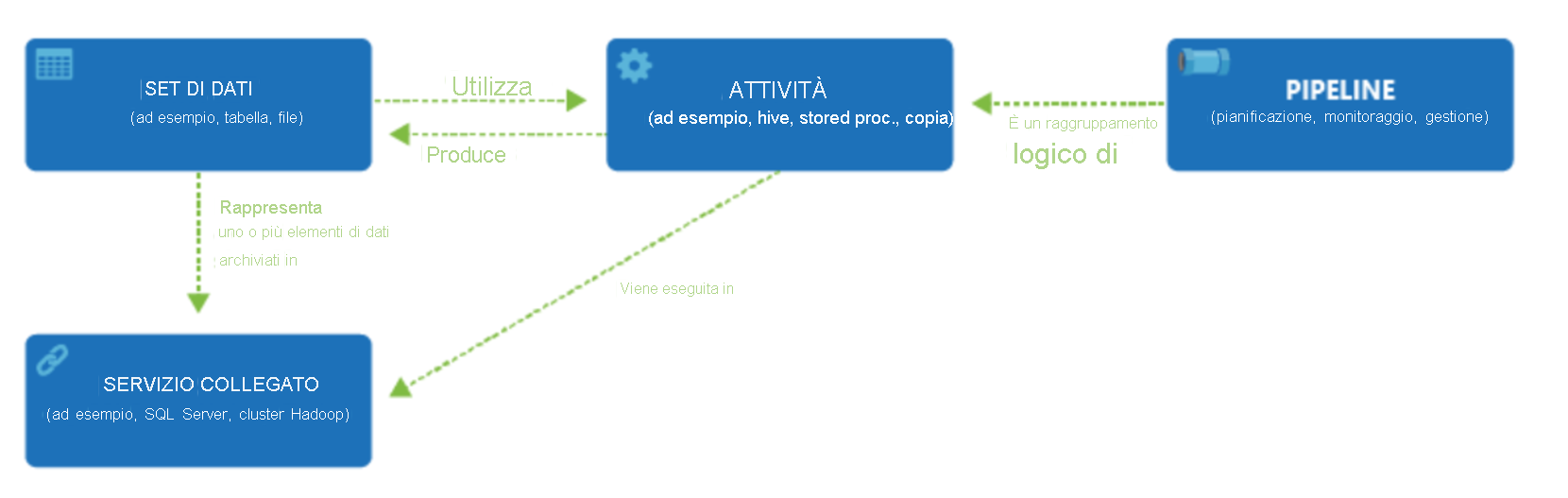
Data Factory supporta diverse origini dati a cui è possibile connettersi tramite la creazione di un oggetto chiamato servizio collegato che consente di inserire i dati di un'origine dati per preparare i dati per la trasformazione e/o l'analisi. I servizi collegati possono inoltre attivare servizi di calcolo su richiesta. È ad esempio possibile che venga richiesto di avviare un cluster HDInsight su richiesta allo scopo di elaborare solo i dati tramite una query Hive. I servizi collegati consentono di definire le origini dati o la risorsa di calcolo necessaria per inserire e preparare i dati.
Dopo aver definito il servizio collegato, Azure Data Factory sa quali set di dati deve usare per la creazione di un oggetto Dataset. I set di dati rappresentano strutture di dati all'interno dell'archivio dati a cui fa riferimento l'oggetto Servizio collegato. I set di dati possono essere usati anche da un oggetto di Azure Data Factory chiamato attività.
Le attività contengono in genere la logica di trasformazione o i comandi di analisi del lavoro di Azure Data Factory. Le attività includono l'attività di copia che può essere usata per inserire dati provenienti da origini dati diverse. Possono anche includere il flusso di dati per mapping per eseguire trasformazioni di dati senza codice. Possono anche includere l'esecuzione di una stored procedure, una query Hive o uno script Pig per trasformare i dati. È possibile eseguire il push dei dati in un modello di Machine Learning per eseguire l'analisi. Non è insolito che vengano eseguite più attività che possono includere la trasformazione dei dati tramite una stored procedure SQL e quindi l'analisi con Databricks. In questo caso, più attività possono essere raggruppate logicamente con un oggetto denominato pipeline ed è possibile pianificarne l'esecuzione oppure è possibile definire un trigger che determini quando è necessario avviare l'esecuzione di una pipeline. Esistono diversi tipi di trigger per i diversi tipi di eventi.
Il flusso di controllo è un'orchestrazione delle attività della pipeline che include il concatenamento di attività in una sequenza, la creazione di rami, la definizione di parametri a livello di pipeline e il passaggio di argomenti durante la chiamata della pipeline su richiesta o da un trigger. Include anche il passaggio di stati personalizzati e i contenitori di ciclo, oltre agli iteratori For-Each.
I parametri sono coppie chiave-valore della configurazione di sola lettura. I parametri sono definiti nella pipeline. Gli argomenti per i parametri definiti vengono passati durante l'esecuzione dal contesto di esecuzione creato da un trigger o da una pipeline eseguita manualmente. Le attività all'interno della pipeline usano i valori dei parametri.
Azure Data Factory ha un runtime di integrazione che consente di collegare l'attività e gli oggetti dei servizi collegati. Viene referenziato dal servizio collegato e fornisce l'ambiente di calcolo in cui l'attività viene eseguita o da cui viene inviata. In questo modo, l'attività può essere eseguita nell'area più vicina possibile. Sono disponibili tre tipi di runtime di integrazione, tra cui il runtime di Azure, il runtime Self-hosted e Azure-SSIS.
Al termine, è possibile usare Data Factory per pubblicare il set di dati finale in un altro servizio collegato che può quindi essere utilizzato da tecnologie come Power BI o Machine Learning.