Esercizio - Aggiungere una matrice di nodi personalizzata a un cluster HPC
Attenzione
Questo contenuto fa riferimento a CentOS, una distribuzione Linux con stato End Of Life (EOL). Valutare le proprie esigenze e pianificare di conseguenza. Per ulteriori informazioni, consultare la Guida alla fine del ciclo di vita di CentOS.
Un oggetto nodearray è una raccolta di nodi configurati in modo identico di un cluster Azure CycleCloud. Lo scopo è quello di offrire scalabilità orizzontale delle risorse di calcolo del cluster quando cambia il numero di processi in coda. Ogni oggetto nodearray ha un nome, un set di attributi che si applicano a ogni nodo e attributi facoltativi che descrivono come deve essere ridimensionato l'oggetto nodearray.
Nel pianificatore di processi Slurm le partizioni raggruppano i nodi in set logici potenzialmente sovrapposti. Lo scopo è quello di ottimizzare l'elaborazione dei processi rispettando i vincoli specifici, ad esempio i limiti di risorse o di tempo. L'utilità di pianificazione alloca i processi ai nodi all'interno di una partizione fino all'esaurimento delle risorse o all'elaborazione di tutti i processi.
Si vuole modificare il cluster gestito da Azure CycleCloud appena distribuito per soddisfare le esigenze di risorse specifiche del processo. A tale scopo, si decide di applicare altre modifiche al modello sottostante e convalidare l'approccio.
In questo esercizio si eseguiranno le seguenti attività:
- Attività 1: Aggiungere una definizione di oggetto nodearray al modello di Azure CycleCloud
- Attività 2: Aggiungere parametri di interfaccia grafica al modello di Azure CycleCloud
- Attività 3: Esportare le proprietà del cluster Azure CycleCloud
- Attività 4: Modificare il file delle proprietà per includere i nuovi parametri
- Attività 5: Importare il modello modificato e il file dei parametri nel cluster esistente
Nota
Assicurarsi di aver completato l'esercizio precedente prima di iniziare questo esercizio.
Attività 1: Aggiungere una definizione di oggetto nodearray al modello di Azure CycleCloud
Si inizierà aggiungendo una definizione di un oggetto nodearray nel modello Slurm che stato personalizzato nell'esercizio precedente di questo modulo. Il modello di esempio include due partizioni con etichetta hpc e htc. Verranno creati un'altra partizione e l'oggetto nodearray corrispondente per i processi che usano le funzionalità CUDA (Compute Unified Device Architecture).
Passare al portale di Azure. Quando richiesto, eseguire l'autenticazione con un account Microsoft o un account Microsoft Entra con il ruolo Collaboratore o Proprietario nella sottoscrizione di Azure usata in questo modulo.
Dal portale di Azure aprire Cloud Shell selezionando la relativa icona sulla barra degli strumenti accanto alla casella di testo di ricerca e assicurarsi di eseguire una sessione di Bash.
Eseguire il comando seguente in Cloud Shell per impostare la directory di lavoro su quella che ospita il repository GitHub recuperato nell'esercizio precedente:
cd ~/cyclecloud-slurm/templatesEseguire il comando seguente per aprire il modello scaricato nell'editor nano:
nano slurm.txtNell'interfaccia dell'editor nano scorrere fino alla sezione
[parameters About]e aggiungere il contenuto seguente direttamente prima di essa:[[nodearray cuda]] MachineType = $CUDAMachineType ImageName = $CUDAImageName MaxCoreCount = $MaxCUDAExecuteCoreCount AdditionalClusterInitSpecs = $CUDAClusterInitSpecs [[[configuration]]] slurm.autoscale = true slurm.hpc = true [[[cluster-init cyclecloud/slurm:execute]]] [[[network-interface eth0]]] AssociatePublicIpAddress = $ExecuteNodesPublicNota
Se si usa un computer Windows, è possibile incollare il contenuto degli Appunti usando la combinazione di tasti MAIUSC+INS.
Nota
Le modifiche definiscono un oggetto nodearray aggiuntivo.
Attività 2: Aggiungere parametri di interfaccia grafica al modello di Azure CycleCloud
Per poter modificare i valori dei parametri del modello nell'interfaccia grafica di Azure CycleCloud, verranno applicate altre modifiche al modello.
Nell'interfaccia dell'editor nano scorrere fino alla sezione
[[parameters Auto-Scaling]]e aggiungere il contenuto seguente direttamente prima di essa:[[[parameter CUDAMachineType]]] Label = CUDA VM Type Description = The VM type for CUDA execute nodes ParameterType = Cloud.MachineType DefaultValue = Standard_NC24Scorrere fino alla sezione
[[[parameter HPCMaxScalesetSize]]]e aggiungere il contenuto seguente direttamente prima di esso:[[[parameter MaxCUDAExecuteCoreCount]]] Label = Max CUDA Cores Description = The total number of CUDA execute cores to start DefaultValue = 100 Config.Plugin = pico.form.NumberTextBox Config.MinValue = 0 Config.IntegerOnly = trueScorrere fino alla sezione
[[[parameter SchedulerClusterInitSpecs]]]e aggiungere il contenuto seguente direttamente prima di esso:[[[parameter CUDAImageName]]] Label = CUDA OS ParameterType = Cloud.Image Config.OS = linux DefaultValue = cycle.image.centos7 Config.Filter := Package in {"cycle.image.centos7", "cycle.image.ubuntu18"}Scorrere fino alla sezione
[[parameters Advanced Networking]]e aggiungere il contenuto seguente direttamente prima di esso:[[[parameter CUDAClusterInitSpecs]]] Label = CUDA Cluster-Init DefaultValue = =undefined Description = Cluster init specs to apply to CUDA execute nodes ParameterType = Cloud.ClusterInitSpecsSselezionare la combinazione di tasti CTRL+O, premere INVIO e quindi selezionare la combinazione di tasti CTRL+X per salvare le modifiche apportate e chiudere il file.
Attività 3: Esportare le proprietà del cluster Azure CycleCloud
Prima di applicare le modifiche di configurazione apportate nel modello di Azure CycleCloud al cluster di destinazione, è necessario esportare le proprietà del cluster.
Eseguire il comando seguente in Cloud Shell per elencare i cluster esistenti:
cyclecloud show_clusterNota
Verificare che l'output includa la voce contoso-custom-slurm-lab-cluster.
Eseguire il comando seguente per esportare nel file params.json l'elenco di parametri del cluster contoso-custom-slurm-lab-cluster con i relativi valori:
cyclecloud export_parameters contoso-custom-slurm-lab-cluster > ~/params.jsonEseguire il comando seguente per esaminare l'elenco esportato di parametri con i relativi valori:
cat ~/params.json
Attività 4: Modificare il file delle proprietà per includere i nuovi parametri
Anche se le modifiche applicate al modello di Azure CycleCloud includono i valori predefiniti per tutti i parametri appena introdotti, può essere necessario apportare modifiche in base ai requisiti specifici. In questa attività si imposteranno i valori dei parametri CUDAMachineType e MaxCUDAExecuteCoreCount.
Eseguire il comando seguente in Cloud Shell per aprire il file dei parametri scaricato nell'editor nano:
nano ~/params.jsonNell'interfaccia dell'editor nano scorrere fino alla fine del file e aggiungere il contenuto seguente iniziando con una nuova riga prima della parentesi graffa di chiusura (}):
"CUDAMachineType" : "Standard_NC6", "MaxCUDAExecuteCoreCount" : 60Aggiungere una virgola alla fine della riga che precede la riga aggiunta nel passaggio precedente:
"CUDAMachineType" : "Standard_NC6"Sselezionare la combinazione di tasti CTRL+O, premere INVIO e quindi selezionare la combinazione di tasti CTRL+X per salvare le modifiche apportate e chiudere il file.
Attività 5: Importare il modello modificato e il file dei parametri nel cluster esistente
Per concludere questo esercizio, si importeranno il modello modificato e il relativo file dei parametri nel cluster esistente, sostituendo la configurazione corrente.
Eseguire il comando seguente in Cloud Shell per importare il modello modificato e il relativo file di parametri nel cluster esistente:
cyclecloud import_cluster contoso-custom-slurm-lab-cluster --file ~/cyclecloud-slurm/templates/slurm.txt -p ~/params.json -c Slurm --forceNota
È necessario specificare il nome del cluster di destinazione e il flag
--forceforce per sovrascrivere la configurazione del cluster esistente.Nel computer aprire un'altra finestra del browser e passare all'URL https://<IP_address>. Se viene richiesto, confermare di voler continuare.
Se viene richiesto di eseguire l'autenticazione, accedere fornendo le credenziali dello stesso account utente dell'applicazione Azure CycleCloud usato per configurare l'interfaccia della riga di comando di Azure CycleCloud.
Nell'interfaccia grafica di Azure CycleCloud passare alla pagina Clusters (Cluster). Nell'elenco dei cluster selezionare la voce contoso-custom-slurm-lab-cluster e quindi Edit (Modifica).
Nella finestra popoup Edit contoso-custom-slurm-lab-cluster (Modifica contoso-custom-slurm-lab-cluster), nella pagina About (Informazioni) selezionare Next (Avanti).
Nella pagina Required settings (Impostazioni obbligatorie) verificare la presenza della voce CUDA VM Type (Tipo VM CUDA) impostata sul valore Standard_NC6 e delle opzioni di scalabilità automatica corrispondenti:
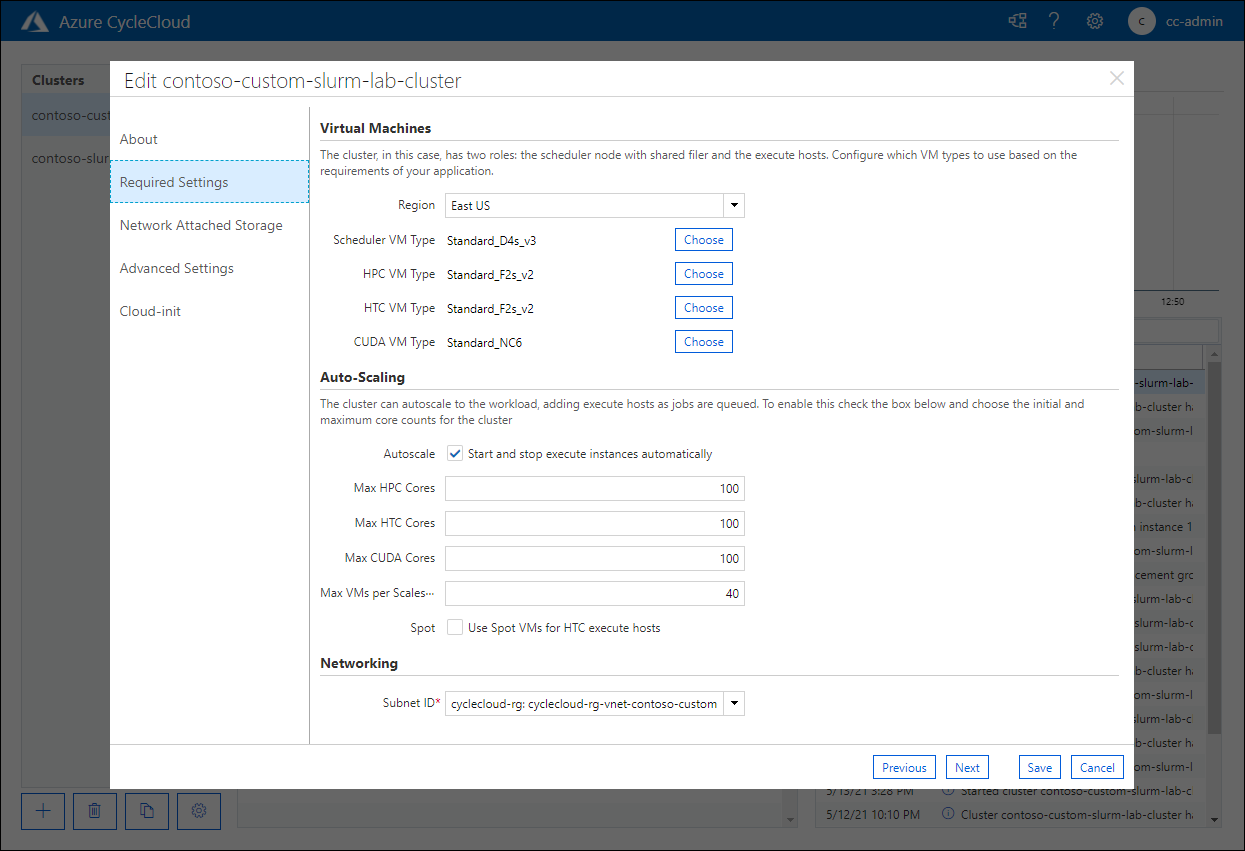
Complimenti. Il secondo esercizio del modulo è stato completato. In questo esercizio è stato ulteriormente personalizzato il cluster Azure CycleCloud usando un modello modificato che include la definizione di un nuovo oggetto nodearray con la partizione corrispondente. A tale scopo, dopo aver modificato il modello, il file dei parametri del cluster è stato esportato, modificato e importato, insieme al modello modificato, nel cluster.
Nota
Non eliminare le risorse distribuite e configurate in questo esercizio se si prevede di eseguire l'esercizio successivo. Queste risorse sono necessarie per completare l'esercizio successivo.