Apertura di un Jupyter Notebook nel cluster Spark in HDInsight
Dopo aver creato il cluster Spark HDInsight, è possibile eseguire query o processi SQL Spark interattivi in un cluster Apache Spark in Azure HDInsight. A tale scopo, è necessario innanzitutto creare un notebook. Un notebook è un editor interattivo che consente agli ingegneri dei dati e agli scienziati dei dati di usare una gamma di linguaggi per interagire con i dati. Questi possono includere Python, SQL, Scala e altri linguaggi. Per l'interazione con i dati HDInsight supporta Jupyter, Zeppelin e Livy. Il livello di interazione dipende dal carico di lavoro che si sta gestendo.
Apache Spark in HDInsight supporta i carichi di lavoro seguenti:
Analisi dei dati interattivi e Business Intelligence
È possibile usare un notebook per inserire dati non strutturati o semistrutturati e quindi definire uno schema all'interno del notebook. È quindi possibile usare lo schema per creare un modello in strumenti quali Power BI che consentirà agli utenti aziendali di eseguire l'analisi dei dati contenuti nel notebook
Machine Learning in Spark
È possibile usare un notebook per usare MLlib, una libreria di Machine Learning basata su Spark, per creare applicazioni di Machine Learning
Analisi dei dati in tempo reale e streaming in Spark
I cluster Spark in HDInsight offrono un supporto completo per la creazione di soluzioni di analisi in tempo reale. Anche se Spark dispone già di connettori per inserire dati da molte origini, ad esempio Kafka, Flume, X, ZeroMQ o TCP socket, Spark in HDInsight aggiunge il supporto di prima classe per l'inserimento di dati da Hub eventi di Azure.
Creare un notebook Jupyter
Usare la procedura seguente per creare un notebook Jupyter nel portale di Azure.
Dal portale, nella sezione Dashboard cluster selezionare Jupyter Notebook. Se richiesto, immettere le credenziali di accesso del cluster.
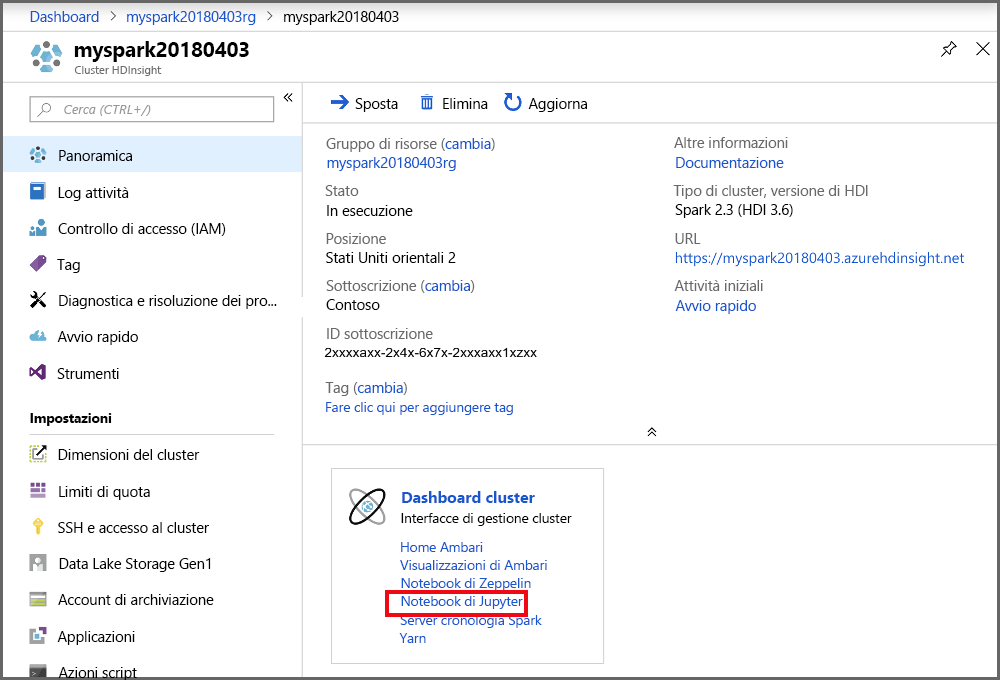
Per creare un notebook, selezionare Nuovo> PySpark.
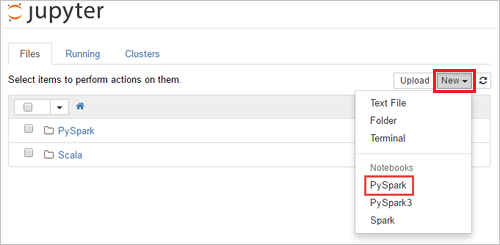
Viene creato e aperto un nuovo notebook con il nome Untitled (Untitled.pynb) che consente di iniziare a creare processi ed eseguire query