Usare l'API Riconoscimento vocale di Azure AI
Il servizio Voce di Azure AI supporta il riconoscimento vocale attraverso due API REST:
- L'API Riconoscimento vocale, che costituisce la principale modalità di esecuzione del riconoscimento vocale.
- L'API Riconoscimento vocale, audio breve, ottimizzata per i flussi audio brevi (fino a 60 secondi).
È possibile usare una delle due API per il riconoscimento vocale interattivo, a seconda della lunghezza prevista dell'input parlato. È possibile usare l'API Riconoscimento vocale anche per la trascrizione batch, trascrivendo più file audio in testo sotto forma di operazione batch.
Per altre informazioni sulle API REST, vedere la documentazione dell'API REST Riconoscimento vocale. In pratica, la maggior parte delle applicazioni abilitate al riconoscimento vocale interattivo usa il servizio Voce tramite un SDK specifico del linguaggio di programmazione.
Uso dell'SDK di Voce di Azure AI
Anche se i dettagli specifici variano a seconda dell'SDK usato (Python, C# e così via), è riscontrabile un modello coerente per l'uso dell'API Riconoscimento vocale:
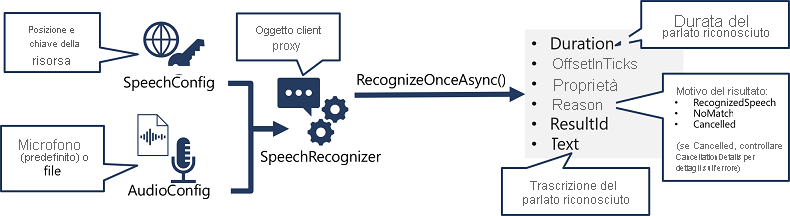
- Usare un oggetto SpeechConfig per incapsulare le informazioni necessarie per connettersi alla risorsa Voce di Azure AI. In particolare, la posizione e la chiave.
- È anche possibile usare un oggetto AudioConfig per definire l'origine di input per l'audio da trascrivere. Per impostazione predefinita, si tratta del microfono di sistema predefinito, ma è anche possibile specificare un file audio.
- Usare SpeechConfig e AudioConfig per creare un oggetto SpeechRecognizer. Questo oggetto è un client proxy dell'API Riconoscimento vocale.
- Usare i metodi dell'oggetto SpeechRecognizer per chiamare le funzioni API sottostanti. Ad esempio, il metodo RecognizeOnceAsync() usa il servizio Voce di Azure AI per trascrivere in modo asincrono una singola espressione parlata.
- Elaborare la risposta del servizio Voce di Azure AI. Nel caso del metodo RecognizeOnceAsync() il risultato è un oggetto SpeechRecognitionResult che include le proprietà seguenti:
- Durata
- OffsetInTicks
- Proprietà
- Motivo
- ResultId
- Testo
Se l'operazione ha esito positivo, la proprietà Reason ha il valore enumerato RecognizedSpeech e la proprietà Text contiene la trascrizione. Altri valori possibili per Result includono NoMatch (che indica che l'audio è stato analizzato correttamente ma non è stato riconosciuto alcun parlato) o Canceled, che indica che si è verificato un errore. In questo caso, è possibile controllare nella raccolta Properties la proprietà CancellationReason per determinare la causa dell'errore.