Informazioni sui concetti relativi ai database Lake
In un database relazionale tradizionale lo schema del database è composto da tabelle, visualizzazioni e altri oggetti. Le tabelle in un database relazionale definiscono le entità per cui vengono archiviati i dati, ad esempio un database di vendita al dettaglio può includere tabelle per prodotti, clienti e ordini. Ogni entità è costituita da un set di attributi definiti come colonne nella tabella e ogni colonna ha un nome e un tipo di dati. I dati per le tabelle vengono archiviati nel database e strettamente associati alla definizione della tabella; che applica tipi di dati, supporto dei valori Null, univocità delle chiavi e integrità referenziale tra le chiavi correlate. Tutte le query e le manipolazioni dei dati devono essere eseguite tramite il sistema di database.
In un data lake non esiste uno schema fisso. I dati vengono archiviati in file che possono essere strutturati, semistrutturati o non strutturati. Le applicazioni e gli analisti dei dati possono lavorare direttamente con i file nel data lake usando gli strumenti di propria scelta; senza i vincoli di un sistema di database relazionale.
Un database lake fornisce un livello di metadati relazionali su uno o più file in un data lake. È possibile creare un database lake che include definizioni per le tabelle, inclusi i nomi di colonna e i tipi di dati, nonché le relazioni tra le colonne chiave primaria ed esterna. Le tabelle fanno riferimento ai file nel data lake, consentendo di applicare la semantica relazionale per lavorare con i dati ed eseguire query tramite SQL. Tuttavia, lo spazio di archiviazione dei file di dati viene disaccoppiato dallo schema del database; consentendo una maggiore flessibilità rispetto a quella offerta in genere da un sistema di database relazionale.
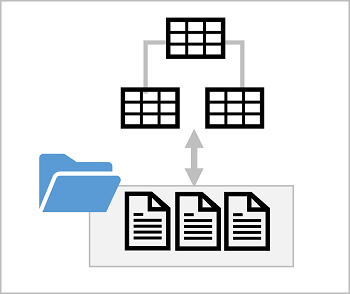
Schema del database lake
È possibile creare un database lake in Azure Synapse Analytics e definire le tabelle che rappresentano le entità per cui è necessario archiviare i dati. È possibile applicare principi di modellazione dei dati comprovati per creare relazioni tra tabelle e usare convenzioni di denominazione appropriate per tabelle, colonne e altri oggetti di database.
Azure Synapse Analytics include un'interfaccia grafica per la progettazione di database che è possibile usare per modellare schemi di database complessi, usando molte delle procedure consigliate per la progettazione dei database applicabili a un database tradizionale.
Spazio di archiviazione del database lake
I dati delle tabelle nel database lake vengono archiviati nel data lake come file Parquet o CSV. I file possono essere gestiti in modo indipendente dalle tabelle di database, semplificando la gestione e l'inserimento di dati con un'ampia gamma di strumenti e tecnologie di elaborazione dei dati.
Calcolo del database Lake
Per eseguire query e modificare i dati tramite le tabelle definite, è possibile usare un pool SQL serverless di Azure Synapse per eseguire query SQL o un pool di Apache Spark di Azure Synapse per lavorare con le tabelle usando l'API Spark SQL.