Competenza di classificazione personalizzata del testo
La classificazione personalizzata del testo consente di eseguire il mapping di un passaggio di testo a diverse classi definite dall'utente. È ad esempio possibile eseguire il training di un modello in base alla trama sulla copertina posteriore dei libri per identificare automaticamente il genere di un libro. È quindi possibile usare il genere identificato per arricchire il motore di ricerca del negozio online con un facet relativo al genere.
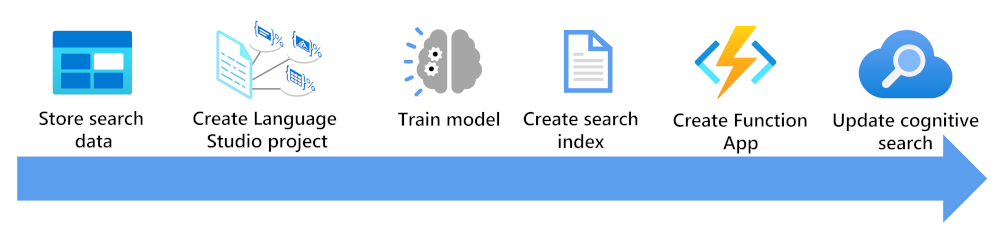
Di seguito sono illustrati gli aspetti da prendere in considerazione per arricchire un indice di ricerca usando un modello di classificazione personalizzata del testo:
- Archiviare i documenti in modo che siano accessibili da Language Studio e dagli indicizzatori di Azure AI Search.
- Creare un progetto di classificazione personalizzata del testo.
- Eseguire il training e il test del modello.
- Creare un indice di ricerca basato sui documenti archiviati.
- Creare un'app per le funzioni che usa il modello sottoposto a training distribuito.
- Aggiornare la soluzione di ricerca, l'indice, l'indicizzatore e il set di competenze personalizzato.
Archiviare i dati
È possibile accedere all'archiviazione BLOB di Azure sia da Language Studio che da Servizi di Azure AI. Il contenitore deve essere accessibile, quindi l'opzione più semplice è quella di scegliere il servizio contenitore, ma è anche possibile usare contenitori privati con alcuni passaggi di configurazione aggiuntivi.
Oltre ai dati, è anche necessario assegnare classificazioni per ogni documento. Language Studio offre uno strumento grafico che è possibile usare per classificare ogni singolo documento manualmente.
È possibile scegliere tra due tipi diversi di progetto. Se un documento esegue il mapping a una singola classe usa un singolo progetto di classificazione delle etichette. Se si vuole eseguire il mapping di un documento a più classi, usare il progetto di classificazione con più etichette.
Se non si vuole classificare manualmente ogni documento, è possibile etichettare tutti i documenti prima di creare il progetto di Lingua di Azure AI. Questo processo comporta la creazione di un documento JSON di etichette in questo formato:
{
"projectFileVersion": "2022-05-01",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomMultiLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project-description",
"language": "en-us"
},
"assets": {
"projectKind": "CustomMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
}
]
}
Alla matrice classes è possibile aggiungere tutte le classi necessarie. Aggiungere una voce per ogni documento nella matrice documents, incluse le classi corrispondenti al documento.
Creare il progetto del linguaggio di Lingua di Azure AI
Ci sono due modi per creare il progetto di Lingua di Azure AI. Se si inizia a usare Language Studio senza prima creare un servizio di linguaggio nel portale di Azure, Language Studio consente di crearne uno automaticamente.
Il modo più flessibile per creare un progetto di Lingua di Azure AI consiste nel creare prima di tutto il servizio di linguaggio usando il portale di Azure. Se si sceglie questa opzione, è possibile aggiungere funzionalità personalizzate.
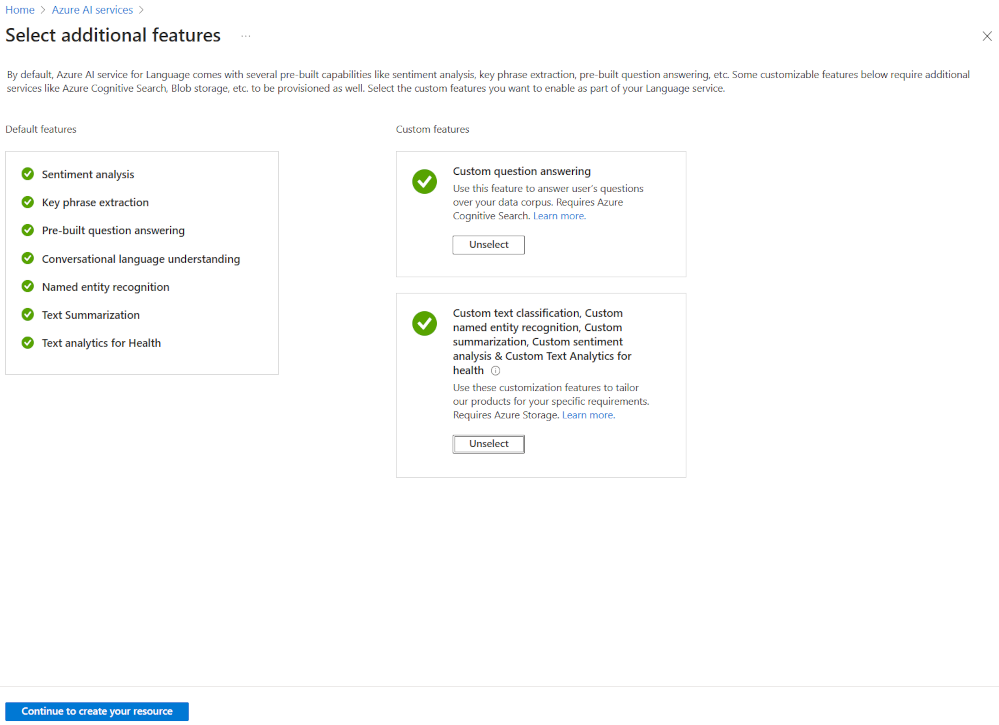
Poiché si creerà una classificazione personalizzata del testo, selezionare tale funzionalità personalizzata quando si crea il servizio di linguaggio. Si collegherà inoltre il servizio di linguaggio a un account di archiviazione usando questo metodo.
Dopo aver distribuito la risorsa, è possibile passare direttamente a Language Studio dal riquadro di panoramica del servizio di linguaggio. È quindi possibile creare un nuovo progetto di classificazione personalizzata del testo.
Nota
Se è stato creato il servizio lingua da Language Studio, potrebbe essere necessario seguire questi passi. Impostare i ruoli per la risorsa di lingua di Azure e l'account di archiviazione per connettere il contenitore di archiviazione al progetto di classificazione personalizzata del testo.
Eseguire il training del modello di classificazione
Come per tutti i modelli di intelligenza artificiale, è necessario avere identificato i dati che è possibile usare per il training. Il modello richiede esempi di come eseguire il mapping dei dati a una classe e alcuni esempi da usare per testare il modello stesso. È possibile scegliere di consentire al modello di dividere automaticamente i dati di training. Per impostazione predefinita, l'80% dei documenti verrà usato per eseguire il training del modello e il 20% per i blind test. Se si dispone di alcuni documenti specifici con cui si vuole testare il modello, è possibile etichettare i documenti per il test.

Nel progetto in Language Studio selezionare Etichettatura dei dati. Verranno visualizzati tutti i documenti. Selezionare ogni documento da aggiungere al set di test e quindi selezionare Test delle prestazioni del modello. Salvare le etichette aggiornate e quindi creare un nuovo processo di training.
Creare un indice di ricerca
Non è necessario eseguire alcuna operazione specifica per creare un indice di ricerca che verrà arricchito da un modello di classificazione personalizzata del testo. Seguire la procedura descritta in Creare una soluzione di Azure AI Search. Dopo aver creato un'app per le funzioni, si aggiorneranno l'indice, l'indicizzatore e la competenza personalizzata.
Creare un'app per le funzioni di Azure
È possibile scegliere il linguaggio e le tecnologie desiderati per l'app per le funzioni. L'app deve essere in grado di passare codice JSON all'endpoint di classificazione personalizzata del testo, ad esempio:
{
"displayName": "Extracting custom text classification",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en-us",
"text": "This film takes place during the events of Get Smart. Bruce and Lloyd have been testing out an invisibility cloak, but during a party, Maraguayan agent Isabelle steals it for El Presidente. Now, Bruce and Lloyd must find the cloak on their own because the only non-compromised agents, Agent 99 and Agent 86 are in Russia"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"project-name": "movie-classifier",
"deployment-name": "test-release"}
}
]
}
Elaborare quindi la risposta JSON dal modello, ad esempio:
{
"jobId": "be1419f3-61f8-481d-8235-36b7a9335bb7",
"lastUpdatedDateTime": "2022-06-13T16:24:27Z",
"createdDateTime": "2022-06-13T16:24:26Z",
"expirationDateTime": "2022-06-14T16:24:26Z",
"status": "succeeded",
"errors": [],
"displayName": "Extracting custom text classification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomMultiLabelClassificationLROResults",
"taskName": "Multi Label Classification",
"lastUpdateDateTime": "2022-06-13T16:24:27.7912131Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"class": [
{
"category": "Action",
"confidenceScore": 0.99
},
{
"category": "Comedy",
"confidenceScore": 0.96
}
],
"warnings": []
}
],
"errors": [],
"projectName": "movie-classifier",
"deploymentName": "test-release"
}
}
]
}
}
La funzione restituisce quindi un messaggio JSON strutturato a un set di competenze personalizzato in AI Search, ad esempio:
[{"category": "Action", "confidenceScore": 0.99}, {"category": "Comedy", "confidenceScore": 0.96}]
Ecco cinque elementi che un'app per le funzioni deve conoscere:
- Testo da classificare.
- Endpoint per il modello distribuito di classificazione personalizzata del testo sottoposto a training.
- Chiave primaria per il progetto di classificazione personalizzata del testo.
- Nome del progetto.
- Nome della distribuzione.
Il testo da classificare viene passato dal set di competenze personalizzato in AI Search alla funzione come input. Gli altri quattro elementi sono disponibili in Language Studio.

Il nome dell'endpoint e quello della distribuzione si trovano nel riquadro relativo alla distribuzione di un modello.

Il nome del progetto e la chiave primaria si trovano nel riquadro delle impostazioni del progetto.
Aggiornare la soluzione Azure AI Search
Nel portale di Azure è necessario apportare tre modifiche per arricchire l'indice di ricerca:
- È necessario aggiungere un campo all'indice per archiviare l'arricchimento della classificazione personalizzata del testo.
- È necessario aggiungere un set di competenze personalizzato per chiamare l'app per le funzioni con il testo da classificare.
- È necessario eseguire il mapping della risposta dal set di competenze all'indice.
Aggiungere un campo a un indice esistente
Nel portale di Azure passare alla risorsa AI Search, selezionare l'indice e aggiungere codice JSON in questo formato:
{
"name": "classifiedtext",
"type": "Collection(Edm.ComplexType)",
"analyzer": null,
"synonymMaps": [],
"fields": [
{
"name": "category",
"type": "Edm.String",
"facetable": true,
"filterable": true,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "standard.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
{
"name": "confidenceScore",
"type": "Edm.Double",
"facetable": true,
"filterable": true,
"retrievable": true,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
]
}
Questo codice JSON aggiunge un campo composto all'indice per archiviare la classe in un campo category in cui è possibile eseguire ricerche. Il secondo campo confidenceScore archivia la percentuale di attendibilità in un campo di tipo double.
Modificare il set di competenze personalizzato
Nel portale di Azure selezionare il set di competenze e aggiungere codice JSON in questo formato:
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "Genre Classification",
"description": "Identify the genre of your movie from its summary",
"context": "/document",
"uri": "https://learn-acs-lang-serives.cognitiveservices.azure.com/language/analyze-text/jobs?api-version=2022-05-01",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "lang",
"source": "/document/language"
},
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "text",
"targetName": "class"
}
],
"httpHeaders": {}
}
Questa definizione di competenza WebApiSill specifica che la lingua e il contenuto di un documento vengono passati come input all'app per le funzioni. L'app restituirà testo JSON con un oggetto class denominato.
Eseguire il mapping dell'output dell'app per le funzioni all'indice
L'ultima modifica consiste nell'eseguire il mapping dell'output all'indice. Nel portale di Azure selezionare l'indicizzatore e modificare il codice JSON in modo da avere un nuovo mapping di output:
{
"sourceFieldName": "/document/class",
"targetFieldName": "classifiedtext"
}
L'indicizzatore ora sa che l'output dell'oggetto document/class dell'app per le funzioni deve essere archiviato nel campo classifiedtext. Poiché il campo è stato definito come campo composto, l'app per le funzioni deve restituire una matrice JSON contenente un campo category e un campo confidenceScore.
È ora possibile eseguire una ricerca del testo classificato personalizzato in un indice di ricerca arricchito.