Errori e tolleranza di errore
Di norma si parla in modo piuttosto approssimativo dei motivi per cui i sistemi smettono di funzionare. Sbaglio, errore, guasto, bug, difetto: questi termini vengono per lo più usati senza distinzione. Nell'ambito del data center i professionisti non dovrebbero mai confondere queste parole o usarne una al posto di un'altra. Di seguito viene data una definizione precisa dei termini rilevanti quando si parla di tolleranza di errore:
Un bug è un'anomalia nella progettazione di un sistema che fa sì che il suo comportamento sia costantemente diverso rispetto ai requisiti o alle aspettative. In un certo senso, potrebbe essere considerato un guasto del sistema o del software che non soddisfa le aspettative, ma un bug non è un guasto del sistema. Molti bug sono di fatto il prodotto di sistemi che funzionano esattamente come sono stati progettati, contrariamente alle intenzioni. La parola chiave qui è "coerente". Il comportamento di un bug può essere riprodotto in tutte le istanze del sistema. Il debug è l'atto di riprogettare il sistema in modo che i bug vengano eliminati.
Un errore è un'anomalia in un sistema che fa sì che si comporti in modo contrario a come è stato progettato o che smetta di funzionare del tutto. In questo caso, la progettazione del sistema potrebbe non presentare imperfezioni, ma un'implementazione o un'istanza di tale progettazione potrebbe non funzionare correttamente. Un errore causa un comportamento che non può essere riprodotto in nessun'altra istanza del sistema. L'atto di eliminare un errore è detto riparazione. Un errore di sistema può manifestarsi in uno dei tre modi seguenti:
Un errore permanente è un'interruzione di un sistema di cui non è possibile risolvere la causa senza sostituire completamente il componente responsabile
Un errore temporaneo è un'interruzione temporanea, anche se in genere non ripetuta, del sistema, di cui è possibile riparare o correggere la causa sul posto o che può plausibilmente risolversi senza alcun intervento
Un errore intermittente è un'interruzione temporanea, in genere ripetuta, del sistema, spesso causata dalla riduzione delle prestazioni o dalla progettazione non corretta di un componente e che, se non corretta, può generare un errore permanente.
Un guasto è il collasso completo di un intero sistema o di parte di esso, spesso generato da un errore non risolto. In questo caso, l'errore è la causa e il guasto è il risultato. Un sistema a tolleranza di errore si comporta come previsto, ovvero secondo le aspettative del contratto di servizio, in circostanze avverse e quindi previene un guasto anche in presenza di errori.
Un difetto è un'anomalia nella produzione di un componente hardware o nella creazione di un'istanza di un componente software, che causa un errore nel funzionamento e, probabilmente, il guasto di un sistema che implementa tale componente. Tale anomalia può essere risolta solo tramite sostituzione.
Uno sbaglio è il prodotto di un'operazione che genera un risultato indesiderato o non corretto. In un dispositivo di elaborazione, uno sbaglio può essere sintomo di un bug nella progettazione o di un errore nell'implementazione e può essere un indicatore efficace di un guasto imminente.
La manutenzione dei sistemi a tolleranza di errore deve essere affidata a uno specialista IT, un amministratore o un operatore che comprenda questi concetti e conosca le differenze tra di essi. Una piattaforma di cloud computing è, per definizione, un sistema a tolleranza di errore. È progettata e compilata in previsione degli errori e funziona in modo tale da evitare guasti del servizio. Dal punto di vista della progettazione, questa resilienza è implicita nel concetto di "cloud". Quando i tecnici telefonici usarono per la prima volta il simbolo di una nuvola (cloud, in inglese) nei diagrammi dei sistemi, questa rappresentava i componenti della rete che non dovevano essere visti o conosciuti, ma i cui livelli di servizio erano così affidabili da non dover entrare nel diagramma, ovvero che potevano essere nascosti da una nuvola.
Quando un sistema informatico, ad esempio una rete IT aziendale, entra in contatto con una piattaforma cloud pubblico, tale piattaforma deve comportarsi come un sistema a tolleranza di errore. Tuttavia non accresce, né può farlo, la tolleranza di errore del sistema con cui comunica. La tolleranza di errore non è un'immunità né una garanzia dell'inesistenza di errori in un sistema. Più precisamente, un sistema a tolleranza di errore non è necessariamente privo di errori. La tolleranza di errore è piuttosto la capacità di un sistema di mantenere i livelli di servizio previsti quando sono presenti errori.
Lo scopo di qualsiasi sistema informatico è automatizzare le funzioni che utilizzano le informazioni. La tolleranza di errore di per sé può essere automatizzata solo in modo limitato. La tolleranza di errore era uno degli obiettivi principali della stessa rete Internet, fin dalla sua forma originale ARPANET. In caso di emergenza, è possibile reindirizzare le comunicazioni digitali per ignorare un sistema il cui indirizzo non è più raggiungibile. Tuttavia Internet non è un computer autosufficiente, nessun sistema informatico lo è.
È sempre necessario l'intervento umano perché qualsiasi sistema informatico possa raggiungere e mantenere gli obiettivi di servizio. I sistemi migliori rendono l'intervento umano e la correzione semplici, immediati e conformi alla pianificazione.
Tolleranza di errore nelle piattaforme cloud
Le prime piattaforme di servizi cloud erano, per essere onesti, meno tolleranti agli errori di quanto volessero gli architetti. Ad esempio, la possibilità per un cliente di effettuare il provisioning eccessivo delle risorse per i servizi, come più istanze di database o cache di memoria duplicate, si è rivelata inefficace a fronte di un monitoraggio insufficiente, che a volte ha reso non disponibili in situazioni di emergenza i backup o le repliche. In più, il provisioning eccessivo è contrario a uno dei principi fondamentali del modello aziendale basato sul cloud: pagare solo per le risorse necessarie. Un'organizzazione non può risparmiare sulle spese operative se noleggia istanze di macchine virtuali aggiuntive nell'eventualità che la macchina virtuale primaria smetta di funzionare.
Un sistema a tolleranza di errore consente la ridondanza, ma in modo sensato e dinamico, in base alle esigenze e ai limiti di disponibilità delle risorse in un determinato momento. All'epoca dei client/server, veniva eseguito il backup di interi server, inclusi i volumi di archiviazione dei dati locali e i volumi di archiviazione di rete a cui erano collegati, a intervalli regolari. Il "backup di tutto" divenne un'etica aziendale a sé. Una volta che i servizi cloud pubblici sono diventati sia convenienti che pratici, le organizzazioni hanno iniziato a usarli per "eseguire il backup di tutto". Con il tempo, hanno capito che il cloud poteva fare di più che perpetuare i vecchi metodi. Le piattaforme cloud potevano essere progettate per la tolleranza di errore fin dall'inizio, non solo dopo l'implementazione.
Tecniche reattive
Indipendentemente dall'accuratezza con cui un sistema è stato progettato, il livello di tolleranza di errore dipenderà da quanto efficacemente il sistema e le persone che lo gestiscono risponderanno alla prima traccia di errore. Di seguito sono riportate alcune delle tecniche reattive usate dalle organizzazioni per attenuare gli errori quando si verificano.
Migrazione di processi non preventiva
La tecnica di migrazione dei processi non preventiva garantisce che l'host di un carico di lavoro in cui si è evidentemente verificato un errore non venga riassegnato come host dello stesso carico di lavoro. Questo vantaggio protegge il "processo", anche se potrebbe impedire al sistema di raccogliere le istanze ripetute di uno sbaglio come prova di un errore, di cui potrebbe essere più facile tenere traccia tramite un percorso accuratamente registrato.
Replica delle attività
Molti sistemi informatici distribuiti eseguono contemporaneamente più istanze (o repliche nell'orchestrazione Kubernetes) di un'attività. I sistemi di gestione basata su criteri possono essere progettati per replicare un'attività in caso di errori di sistema evidenti o sospetti.
Checkpoint e punti di ripristino
Nella forma più semplice, i checkpoint e i punti di ripristino comportano l'acquisizione di snapshot di un sistema in diversi punti nel tempo e consentono agli amministratori di eseguire il rollback fino a un punto nel tempo specificato, qualora si renda necessario il ripristino. Questa strategia diventa più complessa quando sono coinvolte le transazioni, ad esempio quando un'applicazione esegue due o più azioni su un database che devono avere esito positivo o negativo come unità ("transazione"). Un esempio comune è rappresentato da un'applicazione che accredita denaro da un conto mentre lo addebita da un altro. Queste operazioni devono avere esito positivo o negativo come unità per evitare la creazione o l'eliminazione definitiva di asset finanziari.
In un sistema di ripristino del checkpoint in transazioni, i record richiamabili delle transazioni vengono archiviati in memoria in un albero dei processi. In determinati punti durante una transazione, le risorse della memoria usate vengono replicate e depositate in un pool di ripristino. Nel caso in cui l'analisi dei log indichi un errore probabilmente causato dal software, viene creata una copia tramite fork dell'albero dei processi, lo stato della transazione torna a un punto precedente e viene tentata una nuova transazione. Se la nuova transazione restituisce un risultato migliore di quella in cui si è verificato l'errore (ad esempio, se un test di correzione degli errori risulta pulito), il ramo precedente del processo viene eliminato e il nuovo ramo è seguito da questo punto in avanti dell'albero, per ciò che i tecnici chiamano un cambio di contesto.1
Una versione sofisticata di questa metodologia implementa un sistema di traccia all'interno dell'albero dei processi, in modo che, quando un errore si ripete, il sistema possa risalire all'indietro nel processo e tracciare la causa dell'errore. Può quindi selezionare un punto di ripristino appropriato ("punto di salvataggio") prima che l'errore venga generato.[2]
Un'altra implementazione, denominata SGuard, è stata creata dai ricercatori della University of Washington e di Microsoft Research per l'elaborazione a tolleranza di errore di flussi di dati di grandi dimensioni. SGuard sfrutta HDFS (Hadoop Distributed File System) per pianificare la scrittura simultanea di più snapshot di flussi di dati durante l'elaborazione. Questi snapshot sono divisi in parti più piccole in base alle necessità, che a propria volta suddividono l'elaborazione dei flussi in segmenti più piccoli. I checkpoint sono archiviati in HDFS. Questo sistema ha il pregio di mantenere non solo un record delle transazioni di dati in streaming, ma anche più repliche valide dei dati in streaming in posizioni altamente distribuite. Nonostante sia necessario un notevole lavoro di preparazione per implementarlo, SGuard viene tuttavia considerato una tecnica di tolleranza di errore reattiva perché l'operazione principale viene attivata in risposta a un evento di errore.3
Tecniche proattive
Una tecnica di tolleranza di errore proattiva viene applicata prima che emerga l'esistenza di qualsiasi errore. La sua finalità è quella di essere preventiva, ma nell'implementazione moderna acquista sempre più i caratteri di una metodologia. Di seguito sono riportate alcune delle tecniche usate attualmente dalle piattaforme cloud moderne.
Replica delle risorse
La chiave di un'efficace strategia di replica delle risorse potrebbe non essere semplicemente "eseguire il backup di tutto". Un analista di sistema deve riuscire a verificare quali risorse in un sistema (ad esempio, un motore di database, un server Web o un router di rete virtuale) possono essere ripristinate in seguito a un guasto e quali potrebbero non essere recuperabili. La replica intelligente può essere la prima linea di difesa in un sistema a tolleranza di errore.
Esistono quattro comuni strategie per implementare la replica delle risorse, tutte illustrate nella figura 1:
Replica attiva: tutte le risorse replicate sono simultaneamente attive, ma ognuna mantiene in modo indipendente il proprio stato, ovvero i dati locali che la rendono funzionante. Questa proprietà indica che la richiesta di un client viene ricevuta da tutte le risorse replicate in una classe e tutte le risorse elaborano una risposta. Tuttavia a essere recapitata al client è la risposta della risorsa primaria designata in tale classe. Se una risorsa ha esito negativo, incluso il nodo primario, un altro nodo viene designato come successore. Questo sistema richiede che l'elaborazione tra il nodo primario e quello della replica sia deterministica, ovvero da effettuarsi in tandem e in base a un itinerario impostato.
Replica semi-attiva: la replica semi-attiva è simile a una replica attiva, con la differenza che i nodi di replica possono elaborare le richieste in modo non deterministico o non in tandem con il nodo primario. Gli output delle risorse secondarie vengono eliminati e registrati e sono pronti per il cambio non appena si verifica un errore della risorsa primaria.
Replica passiva: solo il nodo della risorsa primaria elabora le richieste, mentre gli altri (le repliche) mantengono lo stato e attendono di essere designati come primari se si verifica un errore. La risorsa primaria con cui il client è in contatto inoltra eventuali modifiche di stato a tutte le repliche. Tutti gli originali e le repliche che appartengono a una classe sono considerati "membri" di un gruppo e un membro può essere escluso dal gruppo se sembra aver avuto esito negativo (anche se di fatto non è così). La possibilità esiste per le latenze o per la riduzione della qualità del servizio (QoS) durante un evento di errore, anche se la replica passiva utilizza meno risorse durante il normale funzionamento.
Replica semi-passiva: questa metodologia ha lo stesso modello di relazione della replica passiva, con la differenza che non esistono risorse primarie permanenti. Il ruolo di coordinatore viene invece attribuito a turno a ogni risorsa e il coordinamento dei turni è determinato da un modello di passaggio dei token, chiamato paradigma della rotazione del coordinatore.
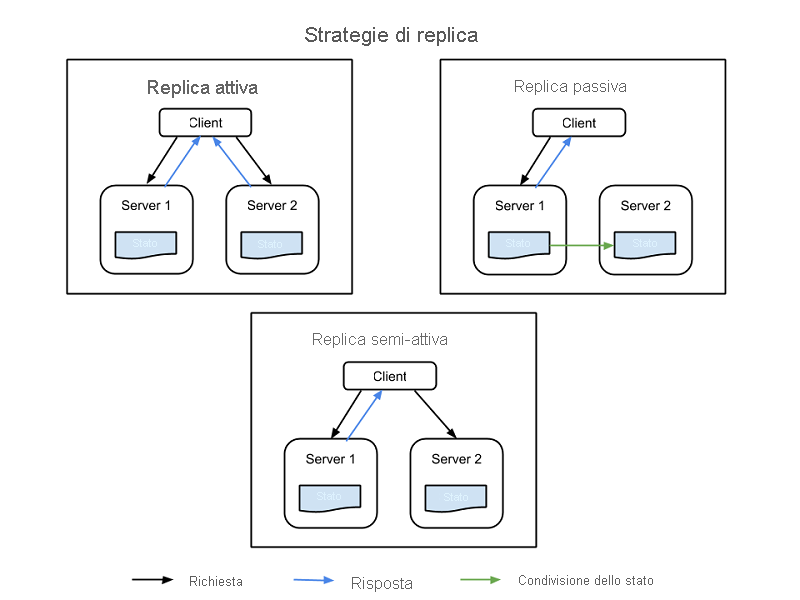
Figura 1: Nodi client, nodi primari e nodi di replica in un sistema informatico replicato.
Bilanciamento del carico
I servizi di bilanciamento del carico distribuiscono le richieste provenienti da diversi client tra più server che eseguono la stessa applicazione, distribuendo così il carico di lavoro e riducendo lo stress sui componenti di sistema. Un effetto collaterale positivo dell'uso di un servizio di bilanciamento del carico è che il traffico verrà automaticamente allontanato dai server che non rispondono, riducendo di conseguenza le probabilità di errori globali. Nei derivati più moderni, in cui il software è stato progettato per essere distribuito in una piattaforma cloud (ad esempio, nei microservizi), i carichi di lavoro sono suddivisi tra funzioni separate, che a loro volta vengono distribuite tra i processori lato server con l'obiettivo di ottenere una distribuzione equa e livelli di utilizzo moderati.
La virtualizzazione (l'elemento chiave del cloud computing) consente di distribuire i carichi di lavoro in modo più uniforme tra i processori rendendoli portabili, in modo che possano essere spostati nel processore fisico che potrà usarli in modo ottimale. La containerizzazione migliora questa tecnica separando i carichi di lavoro virtualizzati dai processori virtuali, in modo che si trovino nel nodo server con il sistema operativo più appropriato. Questo principio è la chiave per l'orchestrazione dei carichi di lavoro dimostrata da sistemi come Kubernetes.
Rinnovamento e riconfigurazione
Nei sistemi informatici in cui le istanze di software sono distribuite per periodi di tempo prolungati, può essere necessario riavviare il software. Mentre alcune piattaforme cloud precedenti hanno provato a campionare nel tempo i livelli di servizio delle istanze di software per determinare quando il riavvio diventa necessario, le versioni successive sono ricorse al più semplice metodo della programmazione di riavvii periodici. Durante queste fasi di riavvio, i file di configurazione di avvio possono essere regolati automaticamente per tener conto delle mutate circostanze del sistema o per prevenire un potenziale errore dopo l'avvio.
Migrazione preventiva
Quando la virtualizzazione è stata introdotta per la prima volta nei data center, la migrazione preventiva è stata suggerita come metodo per bilanciare lo stress esercitato sull'hardware dei server ruotando le assegnazioni dei carichi di lavoro ai processori, possibilmente in base al round robin. Le piattaforme cloud ridistribuiscono i carichi di lavoro nell'infrastruttura virtuale con una frequenza tale che questo metodo è diventato per lo più inutile. Tuttavia, l'argomento è emerso di nuovo nelle recenti discussioni, in combinazione con metodi basati sull'intelligenza artificiale per prevedere lo stress dei carichi di lavoro in diversi sistemi informatici. Tali sistemi potrebbero elaborare regole proprie per deviare i carichi di lavoro più critici dai nodi server in cui è più probabile che si verifichi un errore.
Riparazione automatica
In un sistema informatico ampiamente distribuito, ad esempio una rete per la distribuzione di contenuti (rete CDN) o una piattaforma di social media, le funzioni dei singoli server possono essere distribuite su più indirizzi, in genere in posizioni o data center diversi. Una rete in grado di ripararsi automaticamente esegue il polling delle varie connessioni a intervalli regolari (ad esempio una piattaforma di gestione delle prestazioni) per il flusso di traffico e la velocità di risposta. Ogni volta che è presente un divario nelle prestazioni, i router possono deviare le richieste dai componenti sospetti, arrestando eventualmente il flusso del traffico attraverso tali componenti. Lo stato operativo di tale componente può quindi essere testato per verificare la presenza di errori. Il componente può quindi essere riavviato per verificare se il comportamento persiste e torna allo stato attivo solo se la diagnostica non indica la possibilità di un errore. Questo tipo di reattività transazionale automatizzata è un esempio moderno di riparazione automatica nei data center altamente distribuiti.4
Pianificazione di processi basati sul baratto
Una piattaforma cloud (che include servizi basati sul cloud pubblico, ma che può anche includere l'infrastruttura locale) riesce a segnalare in modo univoco il proprio stato. Quando nel 2009 Amazon ha iniziato a implementare un modello SaaS modificato, i suoi tecnici hanno ideato un concetto chiamato pianificazione di istanze Spot. In questo sistema, un proxy invisibile all'utente che agisce per conto del cliente annuncia i requisiti relativi alle risorse per un determinato processo e trasmette una sorta di richiesta di offerte, in particolare dai nodi server in tutta la piattaforma cloud. Ogni nodo segnala la propria capacità di soddisfare i requisiti dell'offerta in termini di tempo e risorse utilizzate. L'offerente meno caro si aggiudica il contratto e viene designato come istanza Spot per il processo. Questo tipo di pianificazione è attualmente un'opzione di Amazon Elastic Compute Cloud.5
Riferimenti
Ioana, Cristescu. A Record-and-Replay Fault Tolerant System for Multithreading Applications (Sistema a tolleranza di errore basato su registrazione e riproduzione per le applicazioni multithreading). Università tecnica di Cluj Napoca. http://scholar.harvard.edu/files/cristescu/files/paper.pdf.
Sidiroglou, Stelios e altri.ASSURE: Automatic Software Self-healing Using Rescue Points (Riparazione automatica del software tramite punti di ripristino). Columbia University, 2009.
Kwon Yong-Chul e altri. Fault-tolerant Stream Processing Using a Distributed, Replicated File System* (Elaborazione di flussi a tolleranza di errore tramite un file system replicato distribuito). Association for Computing Machinery, 2008. https://db.cs.washington.edu/projects/moirae/moirae-vldb08.pdf.
Yang, Chen. Checkpoint and Restoration of Micro-service in Docker Containers (Checkpoint e ripristino di un microservizio in contenitori Docker). School of Information Security Engineering, Shanghai Jiao Tong University, Cina, 2015. https://download.atlantis-press.com/article/25844460.pdf.
Amazon Web Services, Inc. Richieste Istanza Spot Amazon, 2020. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/spot-requests.html.