Ridimensionamento automatico nel cloud
Le operazioni di aumento delle prestazioni o delle istanze per rispondere all'aumento della domanda e riduzione delle prestazioni o delle istanze per ridurre i costi al decrescere della stessa possono essere eseguite manualmente dagli amministratori cloud. Ad esempio, un amministratore attento può rilevare che la domanda sta crescendo e usare gli strumenti forniti dai provider di servizi cloud per portare online altre macchine virtuali (aumento delle istanze) o sostituire le macchine virtuali esistenti con VM più grandi, ossia con una maggiore quantità di CPU e di memoria (aumento delle prestazioni). La parola chiave è "attento". Se la domanda ha un picco e nessuno se ne accorge, l'intero sistema può diventare lento, persino smettere di rispondere. Viceversa, se si aumentano le prestazioni o le istanze per gestire carichi più pesanti e non le si riducono quando il carico diminuisce, si finisce per pagare per risorse non necessarie.
Questo è il motivo per cui le piattaforme cloud più diffuse offrono meccanismi di ridimensionamento automatico, per adattare le risorse alla fluttuazione della domanda senza bisogno di intervento umano. Esistono due approcci principali al ridimensionamento automatico:
Basato sul tempo - Ridimensionare le risorse in base a una pianificazione predeterminata. Ad esempio, se nel sito Web dell'organizzazione i carichi più elevati si verificano in orario lavorativo, configurare il ridimensionamento automatico in modo da aumentare le prestazioni o le istanze alle 8:00 ogni mattina e ridurle alle 17:00 ogni pomeriggio. Il ridimensionamento basato sul tempo viene talvolta definito ridimensionamento pianificato.
Basato su metriche - Se i carichi sono meno prevedibili, ridimensionare le risorse in base a metriche predefinite, ad esempio utilizzo della CPU, utilizzo della memoria o tempo medio di attesa delle richieste. Ad esempio, portare automaticamente online altre macchine virtuali se l'utilizzo medio della CPU raggiunge il 70% ed effettuare il deprovisioning delle macchine virtuali aggiuntive quando torna al 30%.
Che si scelga di ridimensionare in base al tempo, a metriche o a entrambi i fattori, il ridimensionamento automatico si fonda su regole di ridimensionamento o criteri di ridimensionamento configurati da un amministratore cloud. Le piattaforme cloud moderne supportano regole di ridimensionamento che vanno da regole semplici, ad esempio da due istanze a quattro ogni giorno alle 8:00 e tornare a due istanze alle 17:00, fino a regole complesse, ad esempio, aumentare il numero di macchine virtuali di uno se l'utilizzo massimo della CPU supera il 70% o il tempo medio di attesa delle richieste raggiunge i 5 secondi. Trovare la giusta combinazione di regole in genere richiede un po' di sperimentazione da parte dell'amministratore cloud.
Tutti i principali provider di servizi cloud, compresi Amazon, Microsoft e Google, supportano il ridimensionamento automatico. AWS Auto Scaling può essere applicato a istanze di EC2, tabelle DynamoDB e altri servizi cloud AWS. Azure fornisce opzioni di ridimensionamento automatico per servizi chiave tra cui il servizio app e Macchine virtuali. Google fa lo stesso per Google Compute Engine e Google App Engine.
In generale, i servizi di ridimensionamento automatico aumentano e riducono il numero di istanze anziché le prestazioni, in parte perché per aumentare e ridurre le prestazioni occorre sostituire un'istanza con un'altra e questo implica inevitabilmente un periodo di inattività mentre le nuove istanze vengono create e portate online.
Ridimensionamento automatico basato sul tempo
Il ridimensionamento automatico basato sul tempo è appropriato quando i carichi variano in modo prevedibile. Ad esempio, i sistemi IT di molte organizzazioni sperimentano il carico più elevato durante le ore lavorative e potrebbero registrare un carico minimo o nullo nelle prime del mattino. Il sito Web di Domino's Pizza può riscontrare carichi a tutte le ore del giorno, perché serve più di 16.000 negozi in quasi 100 paesi/aree geografiche. Tuttavia, in determinati periodi dell'anno si verificano prevedibilmente carichi più elevati rispetto al normale.
Entrambi gli scenari sono idonei per il ridimensionamento automatico basato sul tempo. La Figura 7 mostra come abilitare il ridimensionamento automatico pianificato in Azure. In questo esempio, un amministratore cloud configura un servizio app di Azure che ospita il sito Web dell'organizzazione per eseguire due istanze per impostazione predefinita, ma passare a quattro istanze tra le 6:00 e le 18:00 sei giorni alla settimana esclusa la domenica. Selezionando invece l'opzione "Specificare le date di inizio/fine", l'amministratore potrebbe semplicemente configurare il servizio app per salire fino a 10 istanze la domenica del Super Bowl. Potrebbe inoltre definire più condizioni di ridimensionamento per aumentare le istanze anche in altre date.
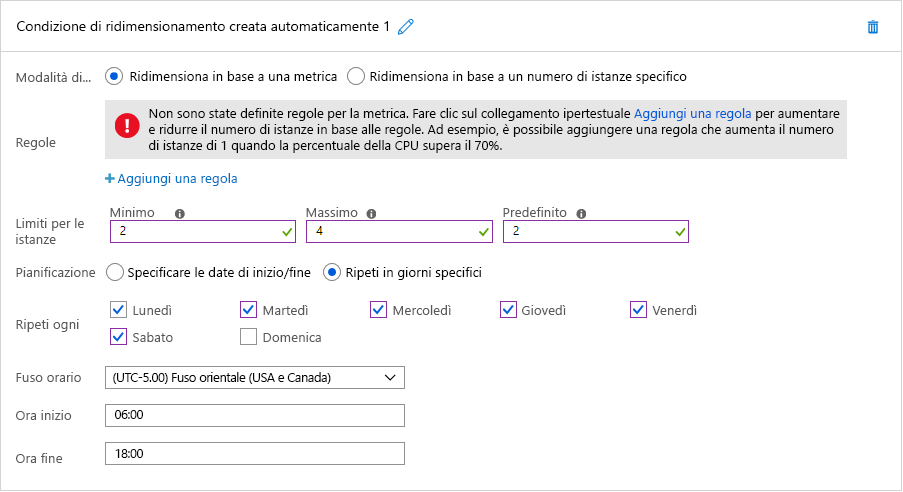
Figura 7: Ridimensionamento automatico pianificato in Azure.
Ridimensionamento automatico basato su metriche
Il ridimensionamento basato su metriche, ad esempio sull'utilizzo della CPU e sul tempo medio di attesa delle richieste, è appropriato quando i carichi sono meno prevedibili. Il monitoraggio è un elemento cruciale per l'efficacia del ridimensionamento automatico delle risorse in base alle metriche delle prestazioni. Consente infatti di analizzare i modelli di traffico o l'utilizzo delle risorse in modo da effettuare una valutazione ponderata su quando e come ridimensionare le risorse al fine di ottimizzare la qualità del servizio riducendo al minimo i costi.
Gli aspetti delle risorse che vengono monitorati per attivare il ridimensionamento sono diversi. La metrica più comune è l'utilizzo delle risorse. Un servizio di monitoraggio, ad esempio, può tenere traccia dell'utilizzo della CPU di ogni nodo delle risorse e ridimensionare le risorse se l'utilizzo è eccessivo o troppo basso. Se, ad esempio, l'utilizzo di ogni risorsa è superiore al 90%, probabilmente è consigliabile aggiungere altre risorse perché il sistema è sottoposto a un carico notevole. I provider di servizi in genere stabiliscono questi punti di attivazione analizzando il punto di rottura dei nodi delle risorse, in cui iniziano i malfunzionamenti, e registrandone il comportamento a diversi livelli di carico. Anche se, per motivi di costi, è importante utilizzare al massimo ogni risorsa, è consigliabile lasciare un certo margine al sistema operativo per l'esecuzione di attività di overhead. Analogamente, se l'utilizzo è inferiore, ad esempio, al 30%, è possibile che non tutti i nodi delle risorse siano necessari e che si possa annullare il provisioning di alcuni.
Nella pratica, i provider di servizi di solito monitorano una combinazione di diverse metriche di un nodo di risorse per valutare quando ridimensionare le risorse. Alcune di queste metriche sono l'utilizzo della CPU, l'utilizzo di memoria, la velocità effettiva e la latenza. AWS usa CloudWatch per monitorare le risorse di EC2 e fornire metriche di ridimensionamento (Figura 8). CloudWatch tiene traccia delle metriche per tutte le istanze di EC2 in un gruppo di ridimensionamento e genera un allarme quando una metrica specificata supera una soglia, ad esempio quando l'utilizzo della CPU è superiore al 70%. Quindi, AWS aumenta o diminuisce il numero di istanze di EC2 in base ai criteri di ridimensionamento configurati da un amministratore.
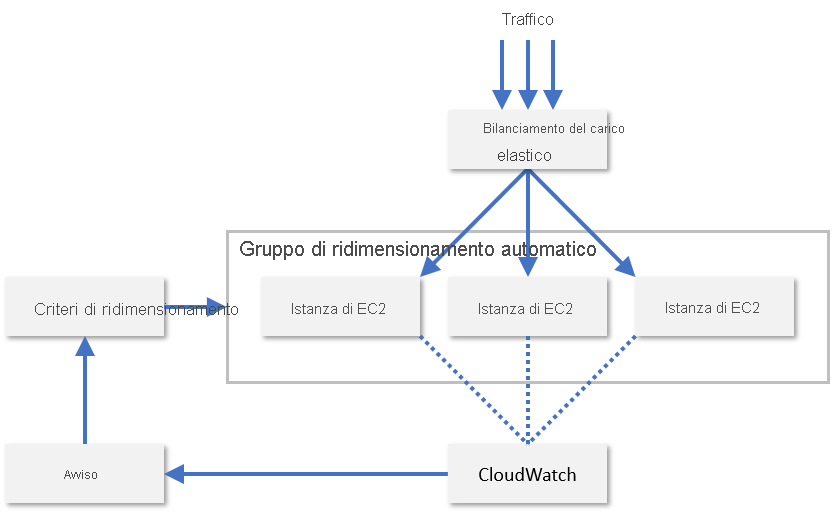
Figura 8: Ridimensionamento automatico di istanze di EC2 in AWS.
AWS supporta anche il ridimensionamento predittivo, che usa il Machine Learning per prevedere i modelli di traffico e gestire il numero delle istanze di conseguenza. L'obiettivo è quello di ridimensionare in modo intelligente le risorse cloud senza bisogno che un amministratore cloud configuri regole di ridimensionamento automatico. I principali provider di servizi cloud cercano continuamente nuovi modi per potenziare le proprie piattaforme con il Machine Learning. Microsoft, ad esempio, ora usa il Machine Learning per migliorare la resilienza delle macchine virtuali di Azure tramite la stima proattiva e la riduzione dell'impatto degli errori delle macchine virtuali1.
Riferimenti
- Microsoft (2018). Improving Azure Virtual Machine resiliency with predictive ML and live migration (Miglioramento della resilienza delle macchine virtuali di Azure con Machine Learning predittivo e migrazione in tempo reale). https://azure.microsoft.com/blog/improving-azure-virtual-machine-resiliency-with-predictive-ml-and-live-migration/.