Ridimensionamento delle risorse di calcolo
Uno dei principali vantaggi del cloud è la possibilità di ridimensionare le risorse in un sistema su richiesta. L'aumento delle prestazioni (provisioning di risorse più grandi) o l'aumento del numero di istanze (provisioning di risorse aggiuntive) consentono di ridurre il carico su un sistema diminuendo l'utilizzo per effetto della maggiore capacità o della distribuzione più ampia del carico di lavoro.
Il ridimensionamento contribuisce a migliorare i tempi di risposta e le prestazioni percepite dal punto di vista dell'utente aumentando la velocità effettiva, perché ora è possibile gestire un numero maggiore di richieste. Questo può essere utile anche per ridurre la latenza durante i picchi di carico, perché in queste circostanze viene inserito in coda un numero inferiore di richieste per singola risorsa. Inoltre, il ridimensionamento può migliorare l'affidabilità del sistema riducendo l'utilizzo delle risorse e impedendo che arrivino al limite.
È importante notare che, anche se il cloud consente di effettuare facilmente il provisioning di risorse nuove o migliori, il costo è sempre un fattore da considerare. Pertanto, anche se è vantaggioso aumentare le prestazioni o le istanze, è importante riconoscere anche quando è opportuno ridurle per contenere i costi.
Scalabilità orizzontale (aumento e riduzione di istanze)
La scalabilità orizzontale è una strategia in cui, nel tempo, risorse aggiuntive vengono aggiunte al sistema oppure risorse estranee vengono rimosse dal sistema. Questo tipo di ridimensionamento è vantaggioso per il livello server quando il carico del sistema fluttua in modo irregolare o imprevedibile. La natura del carico fluttuante rende essenziale il provisioning della quantità corretta di risorse per gestire il carico in qualsiasi momento.
Ecco alcuni fattori che rendono questa attività complessa:
- tempo di attivazione di un'istanza, ad esempio una macchina virtuale
- modello di prezzi del provider di servizi cloud
- potenziale perdita di ricavi a seguito di una riduzione della qualità del servizio (QoS) causata dal non aver ridimensionato tempestivamente le risorse.
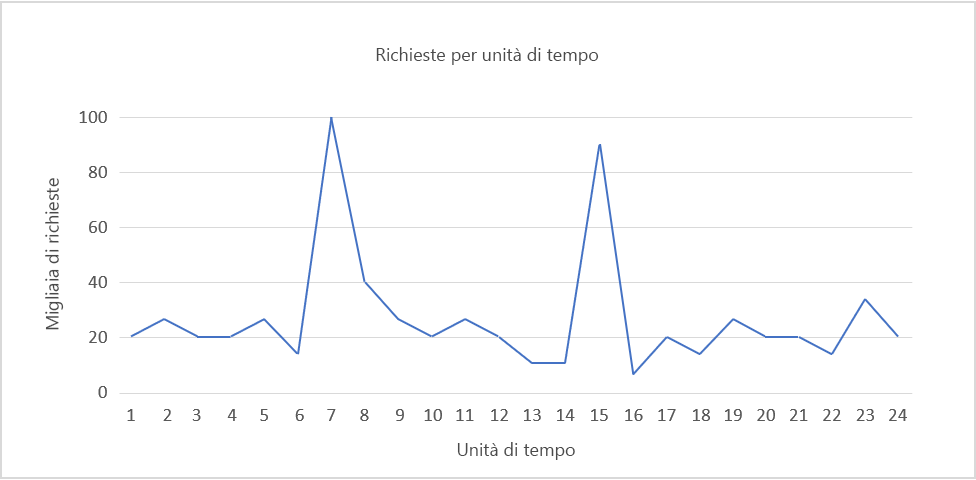
Figura 5: Modello di carico di esempio.
Ad esempio, considerare il modello di carico nella Figura 5.
Si supponga di usare Amazon Web Services, che ogni unità di tempo equivalga a 1 ora di tempo effettivo e che per gestire 5.000 richieste sia necessario un server. La domanda riscontra un picco tra le unità di tempo 6 e 8 e le unità di tempo 14 e 16. Si prenda come esempio quest'ultimo intervallo. È possibile rilevare un calo della domanda intorno all'unità di tempo 16 e iniziare a ridurre il numero di risorse allocate. Dal momento che si passerà da circa 90.000 richieste a 10.000 nello spazio di 3 ore, matematicamente è possibile risparmiare il costo di una decina o più di istanze aggiuntive che sarebbero state online all'unità di tempo 15.
La Figura 6 illustra un modello di ridimensionamento che adatta in tempo reale il numero di istanze al modello di carico, con il numero di istanze visualizzato in rosso. Nei periodi di picco della domanda, il numero di istanze viene aumentato rispettivamente a 20 e 18 per fornire le risorse necessarie per gestire il traffico. Negli altri momenti, il numero di istanze viene ridotto per mantenere l'utilizzo delle risorse relativamente costante. Se si presuppone che ogni istanza costi 20 centesimi all'ora, il costo del mantenimento di 20 istanze in esecuzione per 24 ore è di 96 euro. Il ridimensionamento del numero di istanze come illustrato riduce il costo di circa 42 euro, per un risparmio annuo superiore a 15.000 euro. Si tratta di una cifra considerevole per qualsiasi budget IT.
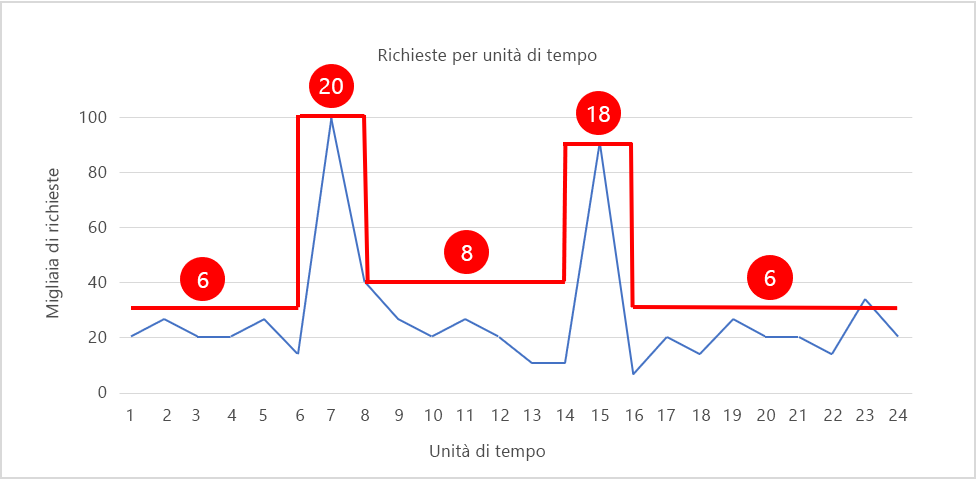
Figura 6: Aumento e riduzione di istanze in base alla domanda.
Il ridimensionamento dipende dalle caratteristiche del traffico e dal carico risultante generato in un servizio Web. Se il traffico segue un modello prevedibile, ad esempio basato su un comportamento umano come lo streaming di film da un servizio Web nelle ore serali, il ridimensionamento può essere predittivo per mantenere una qualità del servizio costante. In molti casi non è tuttavia possibile prevedere il traffico e i sistemi di ridimensionamento devono essere reactive e basati su criteri diversi.
È interessante notare che si può aumentare o ridurre il numero di istanze usando istanze di contenitori oltre che istanze di macchine virtuali. I carichi di lavoro vengono tradizionalmente eseguiti nel cloud all'interno di macchine virtuali, ma sta diventando sempre più comune l'esecuzione in contenitori. Il ridimensionamento dei carichi di lavoro basati su macchina virtuale si esegue aumentando e riducendo il numero di VM. Analogamente, i carichi di lavoro basati su contenitore possono essere ridimensionati variando il numero di contenitori. Poiché i contenitori tendono ad avviarsi più rapidamente rispetto alle macchine virtuali, l'elasticità è leggermente superiore perché le nuove istanze di contenitori possono essere portate online in meno tempo rispetto alle istanze di macchine virtuali.
Scalabilità verticale (aumento e riduzione delle prestazioni)
La scalabilità orizzontale è un modo per realizzare l'elasticità, ma non è l'unico. Si supponga che il traffico verso il proprio sito Web sia raramente superiore a 15.000 richieste per unità di tempo e di aver effettuato il provisioning di una singola istanza di grandi dimensioni in grado di gestirne 20.000, sufficiente per gestire bene il traffico normale e anche picchi di lieve entità. Se il carico sul sito Web aumenta, si può tranquillamente supportare l'aumento del traffico sostituendo l'istanza del server con una dotata del doppio dei core CPU e del doppio della quantità di RAM. Questo è noto come aumento delle prestazioni.
La principale sfida della scalabilità verticale è che in genere comporta un tempo di sostituzione che può essere considerato come tempo di inattività. Ciò è dovuto al fatto che per spostare tutte le operazioni dall'istanza più piccola a un'istanza più grande, anche se il tempo di sostituzione è di pochi minuti, durante questo intervallo la qualità del servizio diminuisce.
Un altro limite della scalabilità verticale è la scarsa granularità. Se si hanno 10 istanze di server online ed è necessario aumentare temporaneamente la capacità del 10%, è possibile aumentare le istanze da 10 a 11 e ottenere il risultato desiderato. Con la scalabilità verticale, tuttavia, in genere l'istanza successiva di dimensioni maggiori ha una capacità circa doppia rispetto alla precedente, il che equivale ad aumentare le istanze da 10 a 20 solo per rispondere a un aumento di traffico del 10%. Si tratta di una soluzione meno conveniente in termini di costi rispetto alla scalabilità orizzontale.
Un'ultima considerazione da fare rispetto alla scalabilità verticale riguarda la disponibilità. Se si ha un'istanza di grandi dimensioni che gestisce tutti i clienti di un sito Web e l'istanza diventa inattiva, diventa inattivo anche il sito Web. Al contrario, se si effettua il provisioning di 10 istanze di piccole dimensioni per gestire lo stesso carico e una di esse diventa inattiva, gli utenti potrebbero notare una lieve riduzione delle prestazioni, ma saranno comunque in grado di accedere al sito. Di conseguenza, anche se il carico è prevedibile e aumenta in modo costante di pari passo con la popolarità del servizio, molti amministratori cloud optano per la scalabilità orizzontale anziché verticale.
Ridimensionamento del livello server
La scalabilità è talvolta un processo più articolato rispetto al semplice provisioning di più risorse (aumento delle istanze) o di risorse più grandi (aumento delle prestazioni). A livello server, l'aumento della domanda può accrescere la competizione per specifici tipi di risorse, ad esempio CPU, memoria e larghezza di banda di rete. I provider di servizi cloud in genere offrono macchine virtuali ottimizzate per carichi di lavoro a elevato utilizzo di calcolo, a elevato utilizzo di memoria e a elevato utilizzo di rete. Conoscere il proprio carico di lavoro e scegliere il tipo corretto di macchina virtuale è essenziale quanto scegliere se aumentare il numero o le dimensioni delle macchine virtuali per affrontare il problema. È preferibile avere cinque macchine virtuali che gestiscono carichi di lavoro a elevato utilizzo di calcolo piuttosto che 10, anche se le VM ottimizzate per carichi di lavoro con utilizzo intensivo della CPU costano il 20% rispetto alle VM generiche.
Aumentare le risorse hardware non è sempre la soluzione migliore per aumentare le prestazioni di un servizio. Aumentare l'efficienza degli algoritmi usati dal servizio può anche ridurre la contesa di risorse e migliorare l'utilizzo, eliminando la necessità di ridimensionare le risorse fisiche.
Una considerazione importante per quanto riguarda il ridimensionamento è la presenza o meno di informazioni sullo stato. Un design di servizio senza stato si presta a un'architettura scalabile. Servizio senza stato vuol dire essenzialmente che la richiesta del client contiene tutte le informazioni necessarie perché il server possa gestirla. Il server non archivia informazioni relative al client nell'istanza e non archivia informazioni relative alla sessione nell'istanza del server.
Avere un servizio senza stato consente di commutare le risorse in base alle esigenze, senza bisogno di alcuna configurazione per mantenere il contesto (stato) della connessione client per le richieste successive. Se il servizio è con stato, il ridimensionamento delle risorse richiede una strategia per il trasferimento del contesto dalla configurazione esistente alla nuova configurazione. Si noti che esistono tecniche per l'implementazione di servizi con stato, ad esempio mantenere una cache di rete in modo da poter condividere il contesto tra i server.
Ridimensionamento del livello dati
Nelle applicazioni orientate ai dati, che prevedono un numero elevato di letture e scritture (o entrambe) in un database o un sistema di archiviazione, il tempo di round trip per ogni richiesta è spesso limitato dai tempi di lettura e scrittura del disco rigido. Le istanze più grandi offrono prestazioni di I/O superiori, che possono migliorare i tempi di ricerca sul disco rigido e, di conseguenza, la latenza del servizio. Anche se la presenza di più istanze di dati nel livello dati può migliorare l'affidabilità e la disponibilità dell'applicazione, fornendo ridondanza del failover, la replica dei dati tra più istanze offre ulteriori vantaggi consentendo di ridurre la latenza di rete se il client viene servito da un data center fisicamente più vicino. Il partizionamento orizzontale dei dati tra più risorse è un'altra strategia di scalabilità orizzontale dei dati in cui, anziché semplicemente replicati tra più istanze, i dati vengono partizionati in segmenti e archiviati in più server di dati.
Un ulteriore problema in fatto di ridimensionamento del livello dati è quello di mantenere la coerenza (un'operazione di lettura è la stessa in tutte le repliche), la disponibilità (letture e scritture hanno sempre esito positivo) e la tolleranza di partizione (quando degli errori impediscono le comunicazioni tra i nodi, le proprietà garantite nel sistema vengono mantenute). Questo è spesso definito teorema CAP. Afferma che un sistema di database distribuito può difficilmente fornire simultaneamente tutte e tre le proprietà, di conseguenza può offrire al massimo una combinazione di due delle proprietà1.
Riferimenti
- Wikipedia. Teorema CAP. https://en.wikipedia.org/wiki/CAP_theorem.