Disponibilità elevata per livello di servizio
Per comprendere le funzionalità e le opzioni di disponibilità in Azure SQL, è necessario comprendere i livelli di servizio. Il livello di servizio selezionato determinerà l'architettura sottostante del database o dell'istanza gestita che si distribuisce.
Ci sono due modelli di acquisto da considerare: DTU e vCore. In questa unità vengono descritti i livelli di servizio vCore e le rispettive architetture per la disponibilità elevata. È possibile paragonare i livelli Basic e Standard del modello DTU al livello per utilizzo generico, nonché i livelli Premium a quelli business critical.
Utilizzo generico
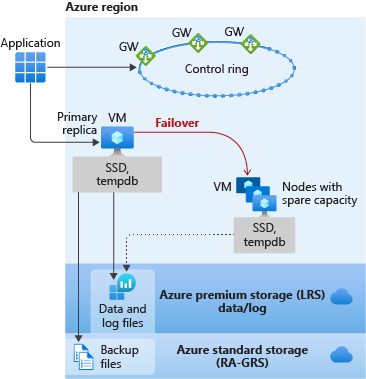
I database e le istanze gestite nel livello di servizio per utilizzo generico hanno la stessa architettura di disponibilità. Usando la figura seguente come guida, considerare prima di tutto l'applicazione e l'anello di controllo. L'applicazione si connette al nome del server, che si connette quindi a un gateway (GW) che punta la connessione dell'applicazione al server corretto, in esecuzione in una macchina virtuale. Con il modello per utilizzo generico, la replica primaria usa l'unità SSD collegata in locale per tempdb. I dati e i file di log vengono archiviati in Archiviazione Premium di Azure, un'archiviazione con ridondanza locale, ovvero con più copie in un'unica area. I file di backup vengono quindi archiviati in Archiviazione Standard di Azure, ovvero un'archiviazione con ridondanza geografica e accesso in lettura (RA-GRS) per impostazione predefinita. RA-GRS è un'archiviazione con ridondanza globale con copie in più aree.
Come illustrato in un modulo precedente di questo percorso di apprendimento, Azure SQL si basa su Azure Service Fabric, che rappresenta la struttura centrale di Azure. Se Azure Service Fabric determina che è necessario eseguire un failover, il failover sarà simile a quello di un'istanza del cluster di failover. Service Fabric cercherà un nodo con capacità disponibile e avvierà una nuova istanza di SQL Server. Verranno quindi collegati i file di database, verrà eseguito il ripristino e i gateway verranno aggiornati per puntare le applicazioni al nuovo nodo. Non sono necessari aggiornamenti, reti virtuali o listener. Questa funzionalità è integrata.
Business Critical
Il livello di servizio successivo da considerare è quello business critical, che in genere consente di ottenere la disponibilità e le prestazioni più elevate di tutti i livelli di servizio di Azure SQL, ovvero per utilizzo generico, Hyperscale e business critical. Il livello business critical è concepito per applicazioni cruciali che richiedono bassa latenza e tempo di inattività minimo.
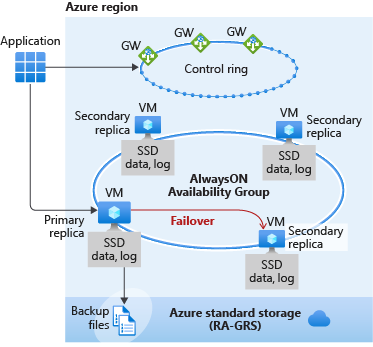
Il livello business critical è simile alla distribuzione di un gruppo di disponibilità Always On in background. A differenza del livello per utilizzo generico, i dati e i file di log nel livello business critical vengono tutti eseguiti su un'unità SSD collegata direttamente, riducendo in modo significativo la latenza di rete. Il livello per utilizzo generico usa l'archiviazione remota. In questo gruppo di disponibilità sono presenti tre repliche secondarie. È possibile usarne una come endpoint di sola lettura, senza costi aggiuntivi. Una transazione può completare un commit quando almeno una delle repliche secondarie ha applicato la protezione avanzata alla modifica per il relativo log delle transazioni.
La scalabilità in lettura con una delle repliche secondarie supporta la coerenza a livello di sessione, se quindi la sessione di sola lettura si riconnette dopo un errore di connessione causato dalla mancata disponibilità della replica, può venire reindirizzata a una replica che non è completamente aggiornata con la replica di lettura/scrittura. Analogamente, se un'applicazione scrive i dati usando una sessione di lettura/scrittura e li legge immediatamente usando una sessione di sola lettura, è possibile che gli aggiornamenti più recenti non siano immediatamente visibili nella replica. La latenza è causata da un'operazione di rollforward asincrona del log delle transazioni.
Se si verifica un errore di qualsiasi tipo e Service Fabric determina che è necessario un failover, il failover in una replica secondaria è rapido perché la replica è già presente e i dati sono collegati. In un failover non è necessario un listener. Il gateway reindirizza la connessione alla replica primaria anche dopo un failover. Questo passaggio avviene rapidamente, quindi Service Fabric si occupa dell'avvio di un'altra replica secondaria.
Hyperscale
Il livello di servizio Hyperscale è solo disponibile nel database SQL di Azure. Questo livello di servizio ha un'architettura unica in quanto usa un livello di cache a livelli e server di pagine per ampliare la possibilità di accedere rapidamente alle pagine del database senza dover accedere direttamente al file di dati.
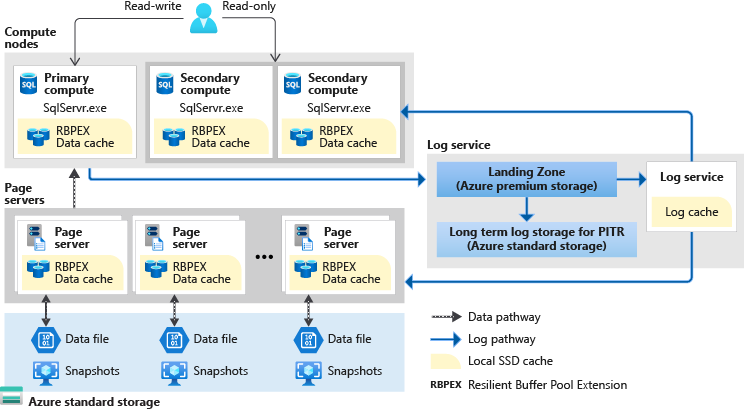
Poiché l'architettura usa server di pagine associati, è possibile aumentare il numero di istanze per inserire tutti i dati nei livelli di memorizzazione nella cache. Questa nuova architettura consente inoltre al livello Hyperscale di supportare database di dimensioni fino a 100 TB. Poiché usa gli snapshot, è possibile eseguire backup di database quasi istantanei, indipendentemente dalle dimensioni. Le operazioni di ripristino dei database richiedono minuti anziché ore o giorni. È anche possibile aumentare o ridurre le prestazioni in modo costante in base ai carichi di lavoro.
È interessante notare il modo in cui è stato eseguito il pull del servizio di log in questa architettura. Il servizio di log viene usato per il feed delle repliche e dei server di pagine. Le transazioni possono eseguire il commit quando il servizio di log applica la protezione avanzata alla zona di destinazione, pertanto per un commit non è necessario che una replica di calcolo secondaria usi le modifiche. A differenza degli altri livelli di servizio, è possibile determinare se usare le repliche secondarie. È possibile configurare da zero a quattro repliche secondarie, tutte utilizzabili per la scalabilità in lettura.
Come negli altri livelli di servizio, si verificherà un failover automatico se Service Fabric ne determina la necessità, ma il tempo di ripristino dipenderà dalla presenza delle repliche secondarie. Se, ad esempio, non sono presenti repliche e si verifica un failover, lo scenario sarà simile a quello del livello di servizio per utilizzo generico: Service Fabric deve prima di tutto trovare la capacità libera. Se sono presenti una o più repliche, il ripristino è più veloce e più allineato a quello del livello di servizio business critical.
Tuttavia, il livello di servizio Hyperscale consente di ottenere una velocità effettiva dei log superiore in termini di MB/secondo, offre le dimensioni massime del database e fino a quattro repliche secondarie per ottenere livelli più alti di scalabilità in lettura. Pertanto, nella scelta tra i due livelli è necessario prendere in considerazione il carico di lavoro.