Che cos'è AutoML?
AutoML è una funzionalità di Azure Databricks che consente di automatizzare il training e la valutazione di un modello di Machine Learning usando combinazioni diverse di valori di algoritmo e iperparametri. Usando AutoML, è possibile ridurre il lavoro richiesto in un processo di training del modello iterativo e creare un modello ottimale per i dati più rapidamente.
Come funziona AutoML?
AutoML funziona generando più esecuzioni dell'esperimento, ognuna delle quali esegue il training di un modello usando un algoritmo diverso e una combinazione di iperparametri. In ogni esecuzione viene eseguito il training e la valutazione di un modello in base ai dati e alla metrica predittiva specificata. Azure Databricks tiene traccia delle esecuzioni e dei modelli prodotti usando MLflow, consentendo di identificare il modello con prestazioni migliori e di distribuirlo nell'ambiente di produzione.
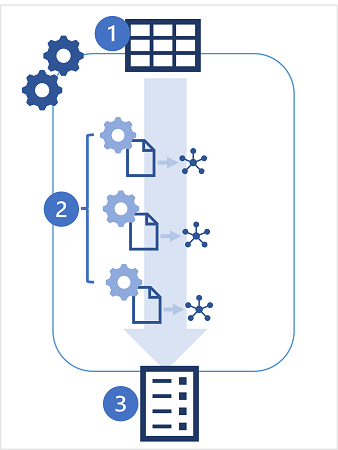
- Si avvia un esperimento AutoML, specificando una tabella nell'area di lavoro di Azure Databricks come origine dati per il training e la metrica delle prestazioni specifica che si vuole ottimizzare.
- L'esperimento AutoML genera più esecuzioni di MLflow, ognuna delle quali produce un notebook con codice per pre-elaborare i dati prima del training e convalidare un modello. I modelli sottoposti a training vengono salvati come artefatti nelle esecuzioni o nei file MLflow nell'archivio DBFS.
- Le esecuzioni dell'esperimento sono elencate in ordine di prestazioni, con i modelli con prestazioni migliori mostrati per primi. È possibile esplorare i notebook generati per ogni esecuzione, scegliere il modello da usare e quindi registrarlo e distribuirlo.
Suggerimento
Per informazioni dettagliate sulle trasformazioni di pre-elaborazione e sugli algoritmi di training specifici usati da AutoML, vedere Funzionamento di AutoML di Azure Databricks nella documentazione di Azure Databricks.
Preparare i dati per AutoML
AutoML richiede un'origine dati di training che include valori di funzionalità e etichette. Per fornire questi dati, creare una tabella nel metastore Hive nell'area di lavoro di Azure Databricks.
Un modo semplice per creare una tabella di dati di training per AutoML consiste nel caricare un file di dati nel portale di Azure Databricks, come illustrato di seguito.
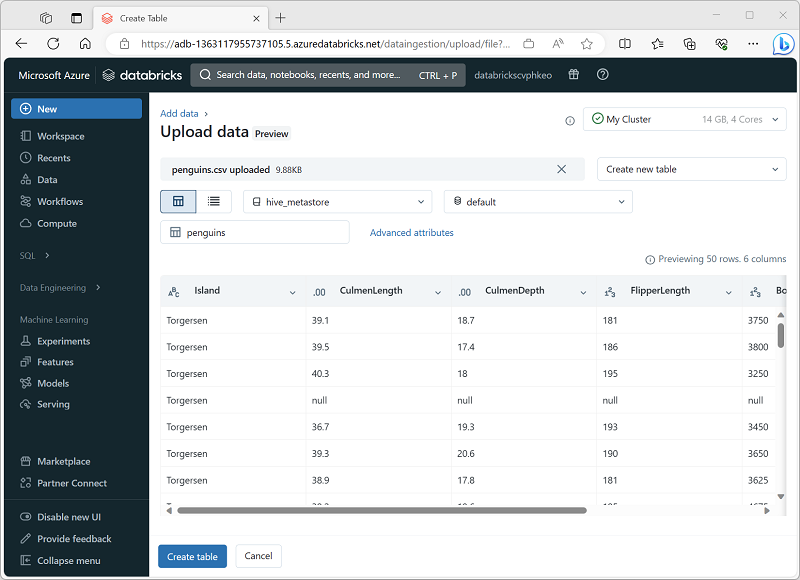
AutoML genera codice per gestire le attività comuni di pre-elaborazione dei dati; ad esempio la codifica di variabili categoriche, il ridimensionamento delle variabili numeriche, la gestione dei valori Null e la gestione di set di dati sbilanciati.