Azure Pipelines
Una soluzione per automatizzare i flussi di lavoro consiste nell'uso di Azure Pipelines, che fa parte di Azure DevOps Services. Con Azure Pipelines è possibile compilare, testare e distribuire automaticamente il codice.
All'interno di un progetto di Machine Learning è possibile usare Azure Pipelines per creare gli asset dell'area di lavoro di Azure Machine Learning, come l'area di lavoro stessa, gli asset di dati, i cluster di calcolo o i processi per eseguire le pipeline di Azure Machine Learning.
Nota
Per usare Azure Pipelines con le pipeline di Azure Machine Learning, è necessario connettere Azure DevOps all'area di lavoro di Azure Machine Learning tramite una connessione al servizio.
Si apprenderà come usare Azure Pipelines per eseguire una pipeline di Azure Machine Learning.
Creare una pipeline di Azure
Azure Pipelines consente di automatizzare il lavoro eseguendo i passaggi ogni volta che viene attivato un trigger. Per usare Azure Pipelines in modo da automatizzare i carichi di lavoro di Machine Learning, verrà attivata una pipeline di Azure Machine Learning con Azure Pipelines.
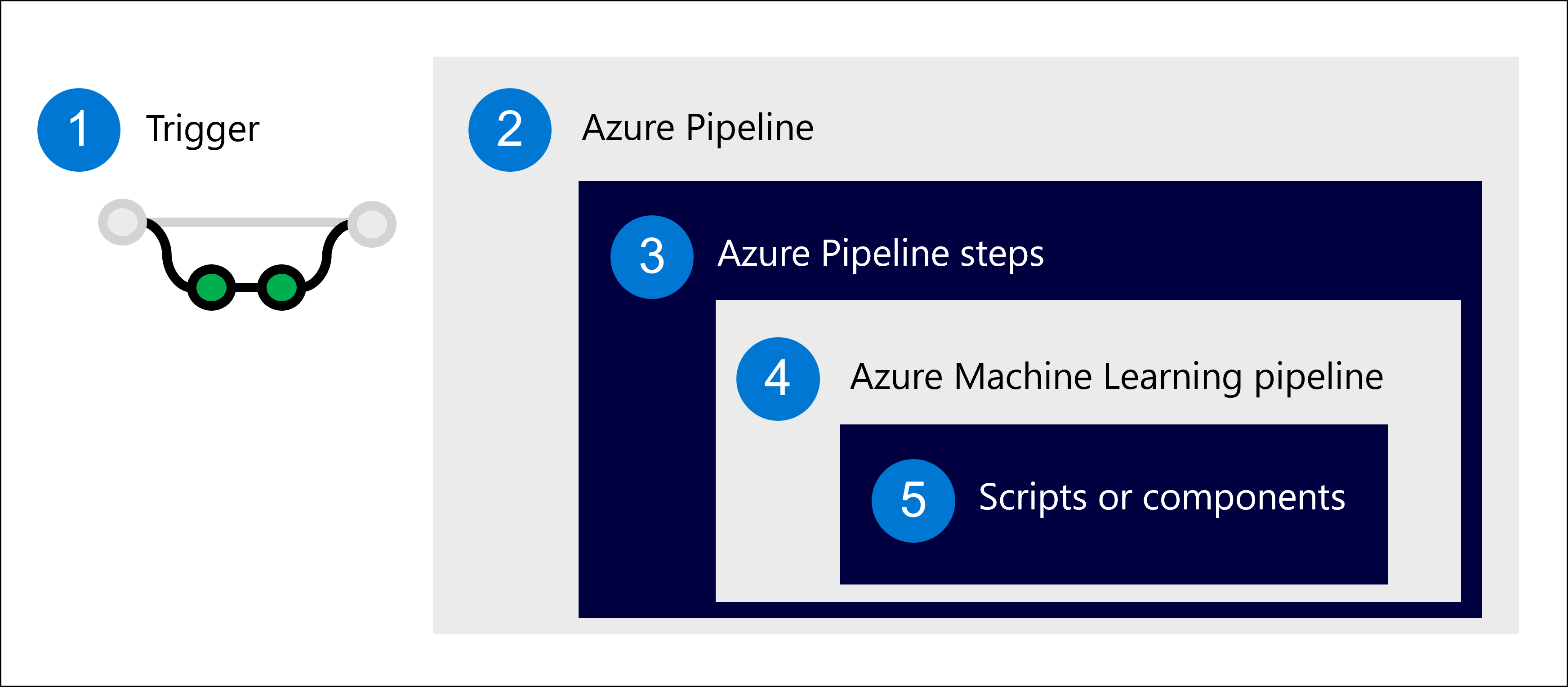
- Attivare una pipeline di Azure. In genere, con una modifica al repository (commit o richiesta pull).
- Eseguire la pipeline di Azure, un gruppo di processi costituiti da più passaggi.
- Un passaggio avvia una pipeline di Azure Machine Learning.
- Una pipeline di Azure Machine Learning esegue script o componenti di Azure Machine Learning.
- Uno script o un componente rappresenta un'attività di Machine Learning.
Per creare la pipeline di Azure, si definiscono i passaggi da includere in un file YAML. Nel file YAML della pipeline di Azure si includeranno:
- Trigger: l'evento che avvia la pipeline.
- Stage: un gruppo di processi comunemente allineati a diversi ambienti di sviluppo (dev/test/prod).
- Job: un set di passaggi che vengono eseguiti su un agente. Per i carichi di lavoro di Machine Learning, si userà probabilmente un agente Ubuntu ospitato da Microsoft.
- Step: uno script o un'attività da eseguire. Ad esempio, un comando dell'interfaccia della riga di comando, che avvia una pipeline di Azure Machine Learning (
az ml job create).
Suggerimento
Altre informazioni sui concetti chiave usati in Azure Pipelines.
Per eseguire una pipeline di Azure Machine Learning quando viene apportata una modifica al repository di Azure, è possibile usare un file YAML simile al seguente:
trigger:
- main
stages:
- stage: deployDev
displayName: 'Deploy to development environment'
jobs:
- deployment: publishPipeline
displayName: 'Model Training'
pool:
vmImage: 'Ubuntu-18.04'
environment: dev
strategy:
runOnce:
deploy:
steps:
- template: aml-steps.yml
parameters:
serviceconnectionname: 'spn-aml-workspace-dev'
Il processo nella pipeline usa aml-steps.yml per elencare i passaggi da eseguire. Per eseguire una pipeline di Azure Machine Learning definita in pipeline-job.yml è possibile usare l'interfaccia della riga di comando (v2). Per eseguire la pipeline di Azure Machine Learning come passaggio nella pipeline di Azure, saranno necessarie le operazioni seguenti:
- Installare l'estensione di Azure Machine Learning per l'interfaccia della riga di comando.
- Usare il comando
az ml job createper eseguire il processo della pipeline in Azure Machine Learning.
Il file aml-steps.yml per l'installazione e l'avvio del processo di Azure Machine Learning può essere simile al seguente:
parameters:
- name: serviceconnectionname
default: ''
steps:
- checkout: self
- script: az extension add -n ml -y
displayName: 'Install Azure ML CLI v2'
- task: AzureCLI@2
inputs:
azureSubscription: ${{ parameters.serviceconnectionname }}
scriptType: bash
scriptLocation: inlineScript
workingDirectory: $(Build.SourcesDirectory)
inlineScript: |
cd src
az ml job create --file aml_service/pipeline-job.yml --resource-group dev-ml-rg --workspace-name dev-ml-ws
displayName: 'Run Azure Machine Learning Pipeline'
Come illustrato nell'esempio, è possibile usare parametri in tutte le definizioni della pipeline (ad esempio, serviceconnectionname) per rendere i file YAML più riutilizzabili per altri progetti.
Eseguire una pipeline con Azure DevOps
Dopo aver creato i file YAML e archiviato tali file nel repository di Azure, è possibile configurare Azure DevOps per l'esecuzione della pipeline.
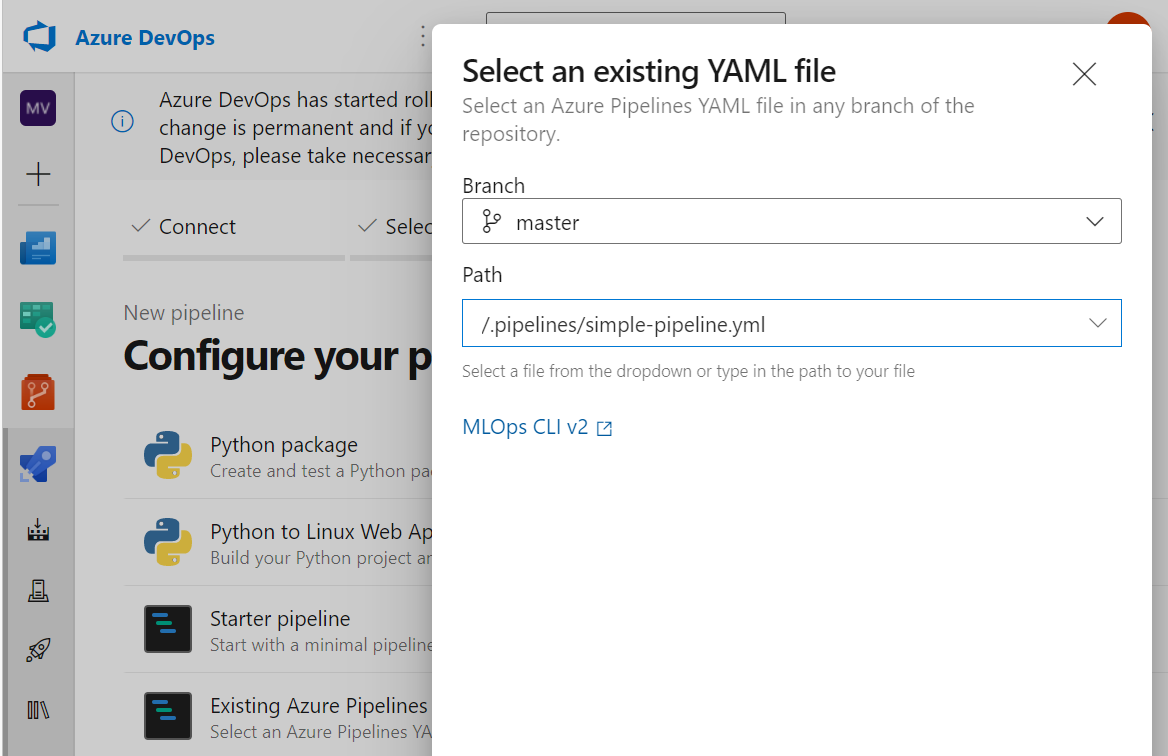
- In Azure DevOps passare alla scheda Pipeline e selezionare Pipeline.
- Creare una nuova pipeline.
- Selezionare GIT Azure Repos come percorso del codice.
- Scegliere il repository contenente il codice.
- Selezionare File YAML di Azure Pipelines esistente.
- Scegliere il percorso che punta al file YAML creato per la pipeline di Azure.
- Dopo aver esaminato la pipeline, è possibile scegliere Salva ed esegui.
La pipeline viene attivata da un commit nel ramo principale. Quando si configura la pipeline, Azure Pipelines esegue il commit di una modifica nel ramo principale, attivando così la prima esecuzione della pipeline. In qualsiasi momento dopo la configurazione, è possibile attivare la pipeline eseguendo il push dei commit nel repository da Visual Studio Code o Azure Repos.
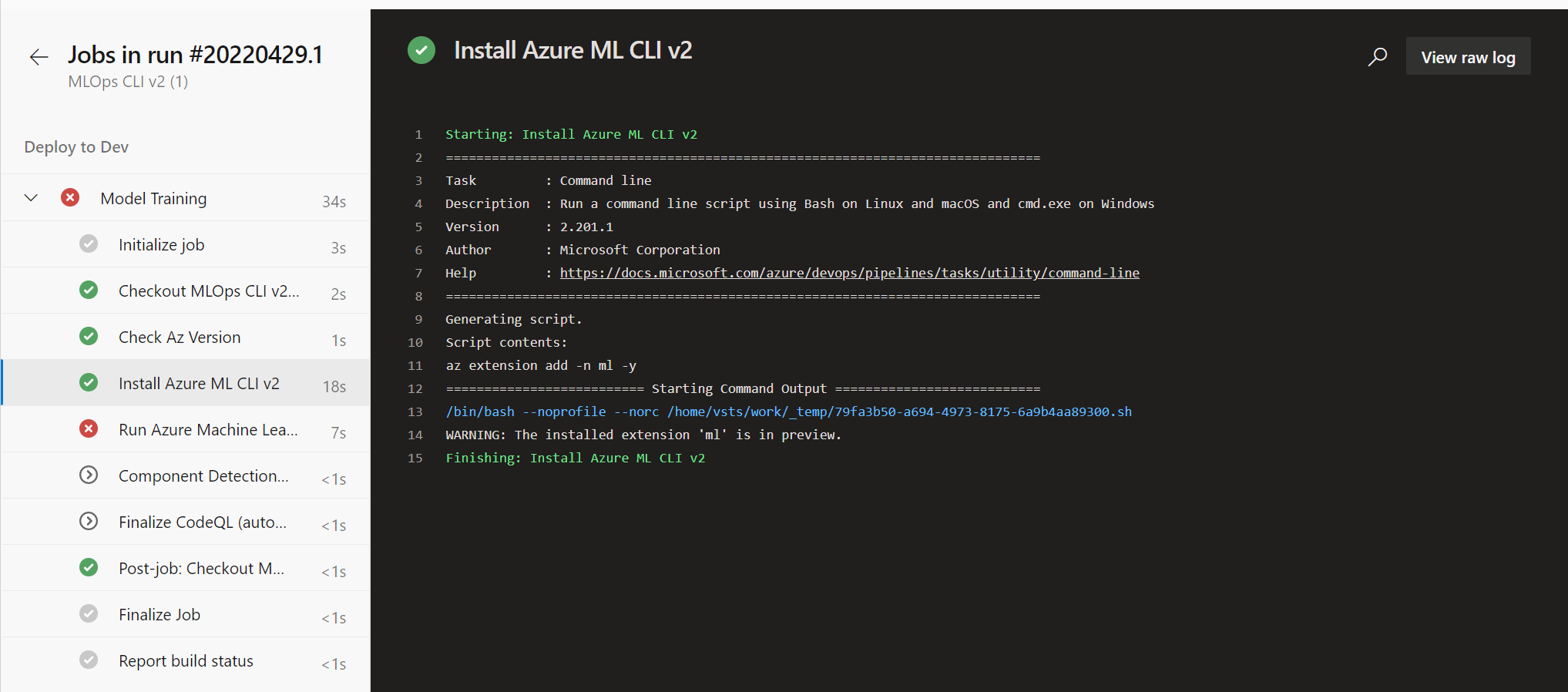
Quando si seleziona un processo, è possibile visualizzarne i passaggi. Ogni passaggio di un processo viene riflesso nel riquadro di spostamento a sinistra. La panoramica mostrerà quali passaggi sono stati eseguiti correttamente e quali hanno restituito errori. Tutti i potenziali messaggi di errore verranno visualizzati nell'interfaccia della riga di comando nel momento in cui si selezionerà il passaggio. Esaminando l'output sarà possibile risolvere l'errore.
Quando un'attività attiva l'esecuzione di una pipeline di Azure Machine Learning, è anche possibile esaminare l'esecuzione della pipeline nell'area di lavoro di Azure Machine Learning per visualizzare eventuali metriche o errori che potrebbero risultare interessanti.