Informazioni su Analisi del testo
Prima di esplorare le funzionalità di analisi del testo del servizio Lingua di Azure AI, verranno esaminati alcuni principi generali e tecniche comuni usate per eseguire l'analisi del testo e altre attività di elaborazione del linguaggio naturale (NLP).
Alcune delle prime tecniche usate per analizzare il testo con i computer implicano l'analisi statistica di un corpo di testo (un corpus) per dedurre un qualche tipo di significato semantico. In parole povere, se si riesce a determinare le parole più usate in un determinato documento, spesso si può ottenere una buona idea sul contenuto del documento stesso.
Tokenizzazione
Il primo passaggio nell'analisi di un corpus consiste nell'suddividerlo in token. Per semplicità, si può considerare ogni parola distinta nel testo di training come un token,anche se, in realtà, i token possono essere generati per parole parziali o per combinazioni di parole e punteggiatura.
Si consideri ad esempio questa frase di un famoso discorso presidenziale degli Stati Uniti: "abbiamo scelto di andare sulla luna". La frase può essere suddivisa nei token seguenti, con identificatori numerici:
- we
- choose
- to
- GO
- il
- luna
Si noti che "to" (numero di token 3) viene usato due volte nel corpus. La frase "scegliamo di andare sulla luna" può essere rappresentata dai token [1,2,3,4,3,5,6].
Nota
È stato usato un semplice esempio in cui i token vengono identificati per ogni parola distinta nel testo. Tuttavia, si considerino i seguenti concetti che possono essere applicati alla tokenizzazione, a seconda del tipo specifico di problema NLP che si sta cercando di risolvere:
- Normalizzazione del testo: Prima di generare token, è possibile scegliere di normalizzare il testo rimuovendo la punteggiatura e modificando tutte le parole in lettere minuscole. Per l'analisi che si basa esclusivamente sulla frequenza delle parole, questo approccio migliora le prestazioni complessive. Tuttavia, un significato semantico può essere perso, ad esempio, considerare la frase "Mr Banks ha lavorato in molte banche". Si potrebbe volere voler distinguere nella propria analisi tra la persona Mr Banks e le banche in cui ha lavorato. Si può anche voler considerare "banche." come token separato per "banche" perché l'inclusione di un punto fornisce l'informazione che la parola si trova alla fine di una frase
- Eliminazione di parole inutili. Le parole non significative sono parole che devono essere escluse dall'analisi. Ad esempio, "il", "un", o"ciò" semplificano la lettura del testo, ma aggiungono un significato semantico minimo. Escludendo queste parole, una soluzione di analisi del testo può essere più in grado di identificare le parole importanti.
- n-grammi sono frasi multi-termine come "ho" o "ha camminato". Una singola frase è un unigramma, una frase a due parole è un bigramma, una frase a tre parole è un trigramma e così via. Considerando le parole come gruppi, un modello di Machine Learning può dare un senso migliore al testo.
- Lo Stemming è una tecnica che prevede l'applicazione di algoritmi per consolidare le parole prima di contarle, in modo che parole con la stessa radice, come "potere", "potenziato" e "potente", vengano interpretate come lo stesso token.
Analisi della frequenza
Dopo aver tokenizzato le parole, è possibile eseguire un'analisi per contare il numero di occorrenze di ogni token. Le parole più comunemente usate (diverse da parole non significative come "aun", "il" e così via) spesso possono fornire un indizio sull'oggetto principale di un corpus di testo. Ad esempio, le parole più comuni nell'intero testo del discorso "andare sulla luna" che abbiamo considerato in precedenza includono "nuovo", "andare", "spazio" e "luna". Se si dovesse tokenizzare il testo come bi-grammi (coppie di parole), il bi-grammo più comune nel discorso è "la luna". Da queste informazioni si può facilmente dedurre che il testo si occupa principalmente di viaggi nello spazio e di andare sulla luna.
Suggerimento
La semplice analisi di frequenza, in cui si conta semplicemente il numero di occorrenze di ciascun token, può essere un modo efficace per analizzare un singolo documento, ma quando è necessario differenziare tra più documenti dello stesso corpus, è necessario un modo per determinare quali token sono più rilevanti in ciascun documento. Frequenza termini: la frequenza documento inversa (TF-IDF) è una tecnica comune in cui un punteggio viene calcolato in base alla frequenza con cui una parola o un termine viene visualizzato in un documento rispetto alla frequenza più generale nell'intera raccolta di documenti. Con questa tecnica, si assume un alto grado di rilevanza per le parole che appaiono frequentemente in un particolare documento, ma relativamente poco frequentemente in un'ampia gamma di altri documenti.
Machine Learning per la classificazione del testo
Un'altra tecnica utile per l'analisi del testo consiste nell'utilizzare un algoritmo di classificazione, come la regressione logistica, per eseguire il training di un modello di apprendimento automatico che classifica il testo in base a un insieme noto di categorizzazioni. Un'applicazione comune di questa tecnica consiste nel eseguire il training di un modello che classifica il testo come positivo o negativo per eseguire l’analisi della valutazione o l’opinion mining.
Si considerino ad esempio le seguenti recensioni di ristoranti, già etichettate come 0 (negative) o 1 (positivo):
- Il cibo e il servizio erano entrambi ottimi: 1
- Un'esperienza davvero terribile: 0
- Mmm! cibo gustoso e un'atmosfera divertente: 1
- Servizio lento e cibo scadente: 0
Con revisioni etichettate sufficienti, è possibile eseguire il training di un modello di classificazione usando il testo con token come funzionalità e la valutazione (0 o 1) come etichetta. Il modello incapsula una relazione tra token e valutazione, ad esempio le recensioni con token per parole come "grande", "gustoso" o "divertente" hanno una maggiore probabilità di restituire una valutazione pari a 1 (positivo), mentre le recensioni con parole come "terribile", "lento" e "scadente" hanno una maggiore probabilità di restituire 0 (negativo).
Modelli linguistici semantici
Con il progredire dello stato dell'arte dell'NLP, la capacità di eseguire il training di modelli che incapsulano la relazione semantica tra i token ha portato alla nascita di potenti modelli linguistici. Al centro di questi modelli si trova la codifica dei token linguistici come vettori (matrici di numeri a più valori) noti come embedding.
Può essere utile considerare gli elementi in un vettore di incorporamento di token come coordinate in uno spazio multidimensionale, in modo che ogni token occupi una specifica "posizione". Più i token sono vicini tra loro lungo una determinata dimensione, più sono correlati semanticamente. In altre parole, le parole correlate vengono raggruppate tra loro. Come semplice esempio, si supponga che gli incorporamenti per i token siano costituiti da vettori con tre elementi:
- 4 ("cane"): [10,3,2]
- 5 ("abbaiare"): [10,2,2]
- 8 ("gatto"): [10,3,1]
- 9 ("miagolare"): [10,2,1]
- 10 ("skateboard"): [3,3,1]
È possibile tracciare la posizione dei token in base a questi vettori in uno spazio tridimensionale, come illustrato di seguito:
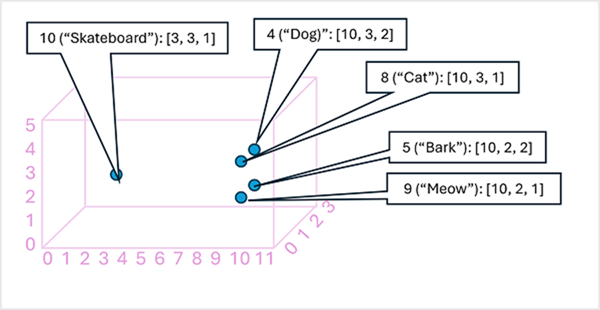
Le posizioni dei token nello spazio degli incorporamenti includono alcune informazioni su quanto i token siano strettamente correlati tra loro. Ad esempio, il token per "cane" è vicino a "gatto" e anche ad "abbaiare". I token per "gatto" e "abbaiare" sono vicini a "miagolare". Il token per "skateboard" è più lontano dagli altri token.
I modelli linguistici usati nel settore si basano su questi principi, ma hanno una maggiore complessità. Ad esempio, i vettori usati in genere hanno molte più dimensioni. Esistono anche diversi modi per calcolare gli incorporamenti appropriati per un determinato set di token. Metodi diversi generano stime diverse dai modelli di elaborazione del linguaggio naturale.
Una visualizzazione generalizzata delle soluzioni di elaborazione del linguaggio naturale più moderne è illustrata nel diagramma seguente. Un ampio corpus di testo non elaborato viene tokenizzato e usato per eseguire il training di modelli linguistici, che possono supportare molti tipi diversi di attività di elaborazione del linguaggio naturale.
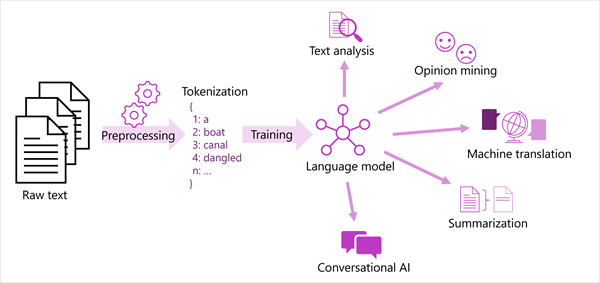
Le attività comuni NLP supportate dai modelli linguistici includono:
- Analisi del testo, ad esempio l'estrazione di termini chiave o l'identificazione di entità denominate nel testo.
- Analisi di valutazione e opinion mining per classificare il testo come positivo o negativo.
- Traduzione automatica, in cui il testo viene tradotto automaticamente da una lingua a un'altra.
- Riepilogo, in cui vengono riepilogati i punti principali di un corpo di testo di grandi dimensioni.
- Soluzioni di intelligenza artificiale conversazionale, ad esempio bot o assistenti digitali in cui il modello linguistico può interpretare l'input del linguaggio naturale e restituire una risposta appropriata.
Queste funzionalità e altro ancora sono supportate dai modelli nel servizio Lingua di Azure AI, che verranno esaminati di seguito.