DBCC SHOW_STATISTICS (Transact-SQL)
Si applica a: ![]() SQL Server
SQL Server ![]() Database SQL di Azure
Database SQL di Azure ![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Piattaforma di strumenti analitici (PDW)
Piattaforma di strumenti analitici (PDW) ![]() Endpoint di analisi SQL in Microsoft Fabric
Endpoint di analisi SQL in Microsoft Fabric ![]() Warehouse in Microsoft Fabric
Warehouse in Microsoft Fabric
Visualizza le statistiche di ottimizzazione delle query correnti per una tabella o vista indicizzata. Query Optimizer usa le statistiche per stimare la cardinalità o il numero di righe nel risultato delle query al fine di creare un piano di query di qualità elevata. Query Optimizer potrebbe ad esempio usare le stime relative alla cardinalità per scegliere l'operatore Index Seek anziché l'operatore Index Scan nel piano di query, evitando un'operazione di analisi dell'indice che usa un numero elevato di risorse e migliorando di conseguenza le prestazioni delle query.
Query Optimizer archivia le statistiche relative a una tabella oppure a una vista indicizzata in un oggetto statistiche. Per una tabella, l'oggetto statistiche viene creato in un indice oppure in un elenco di colonne della tabella. L'oggetto statistiche è costituito da un'intestazione con metadati relativi alle statistiche, un istogramma con la distribuzione dei valori nella prima colonna chiave dell'oggetto stesso e un vettore di densità per misurare la correlazione tra colonne. Il motore di database può calcolare le stime relative alla cardinalità con qualsiasi dato contenuto nell'oggetto statistiche. Per altre informazioni, vedere Statistiche e Stima della cardinalità (SQL Server).
DBCC SHOW_STATISTICS visualizza l'intestazione, l'istogramma e il vettore di densità in base ai dati archiviati nell'oggetto statistiche. La sintassi consente inoltre di specificare una tabella o una vista indicizzata con un nome di colonna, un nome di statistiche o un nome di indice di destinazione.
Aggiornamenti importanti nelle versioni precedenti di SQL Server:
A partire da SQL Server 2012 (11.x) Service Pack 1, la vista a gestione dinamica sys.dm_db_stats_properties è disponibile per recuperare a livello di codice le informazioni sull'intestazione contenute nell'oggetto statistiche per le statistiche non incrementali.
A partire da SQL Server 2014 (12.x) Service Pack 2 e SQL Server 2012 (11.x) Service Pack 1, la vista a gestione dinamica sys.dm_db_incremental_stats_properties è disponibile per recuperare le informazioni di intestazione contenute nell'oggetto statistiche per le statistiche incrementali.
A partire da SQL Server 2016 (13.x) Service Pack 1 CU 2, la vista a gestione dinamica sys.dm_db_stats_histogram è disponibile per recuperare a livello di codice le informazioni sull'istogramma contenute nell'oggetto statistiche.
-
Questa sintassi non è supportata da pool SQL serverless in Azure Synapse Analytics.
Per altre informazioni sulle statistiche in Microsoft Fabric, vedere Statistiche.
![]() Convenzioni relative alla sintassi Transact-SQL
Convenzioni relative alla sintassi Transact-SQL
Sintassi
Sintassi per SQL Server e database SQL di Azure:
DBCC SHOW_STATISTICS ( table_or_indexed_view_name , target )
[ WITH [ NO_INFOMSGS ] < option > [ , ...n ] ]
< option > ::=
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM
[ ; ]
Sintassi per Azure Synapse Analytics, Platform System (PDW) e Microsoft Fabric:
DBCC SHOW_STATISTICS ( table_name , target )
[ WITH { STAT_HEADER | DENSITY_VECTOR | HISTOGRAM } [ , ...n ] ]
[ ; ]
Argomenti
table_or_indexed_view_name
Nome della tabella o della vista indicizzata per la quale visualizzare le informazioni statistiche.
table_name
Nome della tabella contenente la statistica da visualizzare. La tabella non può essere una tabella esterna.
target
Nome dell'indice, delle statistiche o della colonna per cui visualizzare le informazioni statistiche. L'oggetto target è racchiuso tra parentesi quadre, virgolette singole, virgolette doppie o viene inserito senza virgolette.
- Se l'oggetto target è il nome di un indice o di statistiche esistenti in una tabella o in una vista indicizzata, vengono restituite le relative informazioni statistiche.
- Se target è il nome di una colonna esistente e per tale colonna esiste un oggetto statistiche creato automaticamente, vengono restituite le informazioni relative a tali statistiche.
Se non esiste una statistica creata automaticamente per una destinazione di colonna, viene restituito il messaggio di errore 2767.
In Azure Synapse Analytics and Analytics Platform System (PDW) la destinazione non può essere un nome di colonna.
In Warehouse in Microsoft Fabric la destinazione può essere il nome di un istogramma a colonna singola o di una colonna. Se per la destinazione viene usato un nome di colonna, questo comando restituisce informazioni di distribuzione solo sulla statistica istogramma generata automaticamente. Per visualizzare le informazioni su una statistica istogramma creata manualmente, specificare il nome delle statistiche come destinazione.
NO_INFOMSGS
Evita la visualizzazione di tutti i messaggi informativi con livello di gravità compreso tra 0 e 10.
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM [ , n ]
Specificando una o più opzioni tra quelle disponibili è possibile limitare i set di risultati restituiti dall'istruzione all'opzione o alle opzioni specificate. Se non si specifica alcuna opzione, vengono restituite tutte le informazioni statistiche.
STATS_STREAM è identificato solo a scopo informativo. Non supportato. Non è garantita la compatibilità con le versioni future.
Set di risultati
Nella tabella seguente vengono descritte le colonne restituite nel set di risultati quando si specifica l'opzione STAT_HEADER.
| Nome colonna | Descrizione |
|---|---|
| Name | Nome dell'oggetto statistiche. |
| Aggiornato | Data e ora dell'ultimo aggiornamento delle statistiche. La funzione STATS_DATE rappresenta un metodo alternativo per il recupero di queste informazioni. Per altre informazioni, vedere la sezione Osservazioni più avanti nella pagina. |
| Righe | Numero totale di righe della tabella o della vista indicizzata al momento dell'ultimo aggiornamento delle statistiche. Se le statistiche vengono filtrate o corrispondono a un indice filtrato, il numero di righe potrebbe essere inferiore al numero di righe della tabella. Per ulteriori informazioni, vedi Statistiche. |
| Rows Sampled | Numero totale di righe campionate per i calcoli statistici. Se Rows Sampled < Rows, l'istogramma e i risultati relativi alla densità visualizzati vengono stimati in base alle righe campionate. |
| Passaggi | Numero di intervalli nell'istogramma. Ogni intervallo comprende un insieme di valori di colonna seguiti da un valore di colonna pari al limite superiore. Gli intervalli dell'istogramma vengono definiti nella prima colonna chiave delle statistiche. Il numero massimo di intervalli è 200. |
| Densità | Valore calcolato come 1/ valori distinct per tutti i valori nella prima colonna chiave dell'oggetto statistiche, ad eccezione dei valori limite dell'istogramma. Questo valore di densità non viene usato da Query Optimizer e viene visualizzato per garantire la compatibilità con le versioni precedenti a SQL Server 2008 (10.0.x). |
| Average Key Length | Numero medio di byte per valore per tutte le colonne chiave nell'oggetto statistiche. |
| String Index | Il valore Yes indica che l'oggetto statistiche contiene statistiche di riepilogo delle stringhe per migliorare le stime relative alla cardinalità per i predicati della query che utilizzano l'operatore LIKE, ad esempio WHERE ProductName LIKE '%Bike'. Le statistiche di riepilogo delle stringhe vengono archiviate separatamente dall'istogramma e vengono create nella prima colonna chiave dell'oggetto statistiche quando è di tipo char, varchar, nchar, nvarchar, varchar(max), nvarchar(max), text o ntext.. |
| Espressione filtro | Predicato per il subset di righe della tabella incluso nell'oggetto statistiche. NULL = statistiche non filtrate. Per altre informazioni sui predicati di filtro, vedere Creare indici filtrati. Per altre informazioni sulle statistiche filtrate, vedere Statistiche. |
| Unfiltered Rows | Numero totale di righe nella tabella prima dell'applicazione dell'espressione di filtro. Se l'espressione di filtro è NULL, Unfiltered Rows è uguale a Rows. |
| Persisted Sample Percent | Percentuale di campionamento persistente usata per gli aggiornamenti delle statistiche che non specificano in modo esplicito una percentuale di campionamento. Se il valore è zero, non viene impostata alcuna percentuale di campionamento persistente per la statistica. Si applica a: SQL Server 2016 (13.x) Service Pack 1 CU 4 |
Nella tabella seguente vengono descritte le colonne restituite nel set di risultati quando si specifica l'opzione DENSITY_VECTOR.
| Nome colonna | Descrizione |
|---|---|
| All Density | Il valore Density viene calcolato come 1/ valori distinct. Nei risultati la densità viene visualizzata per ogni prefisso di colonna dell'oggetto statistiche, una riga per ogni densità. Un valore distinct è un elenco distinto dei valori delle colonne per riga e per prefisso di colonna. Se l'oggetto statistiche contiene, ad esempio, le colonne chiave (A, B, C), i risultati restituiscono la densità degli elenchi di valori distinct in ognuno di tali prefissi di colonna, ovvero (A), (A, B) e (A, B, C). Utilizzando il prefisso (A, B, C), ciascuno di questi elenchi è un elenco di valori distinct, ovvero (3, 5, 6), (4, 4, 6), (4, 5, 6), (4, 5, 7). Utilizzando il prefisso (A, B) agli stessi valori di colonna sono associati gli elenchi di valori distinct (3, 5), (4, 4) e (4, 5). |
| Average Length | Lunghezza media, in byte, per archiviare un elenco di valori di colonna per il prefisso di colonna. Se per ogni valore presente nell'elenco (3, 5, 6), ad esempio, sono necessari 4 byte, la lunghezza media è di 12 byte. |
| Colonne | Nomi delle colonne nel prefisso per cui sono visualizzati i valori di All Density e Average Length. |
Nella tabella seguente vengono descritte le colonne restituite nel set di risultati quando si specifica l'opzione HISTOGRAM.
| Nome colonna | Descrizione |
|---|---|
| RANGE_HI_KEY | Valore di colonna pari al limite superiore per un intervallo dell'istogramma. Il valore di colonna viene denominato anche valore chiave. |
| RANGE_ROWS | Numero stimato di righe il cui valore di colonna è compreso in un intervallo dell'istogramma, escluso il limite superiore. |
| EQ_ROWS | Numero stimato di righe il cui valore di colonna è uguale al limite superiore dell'intervallo dell'istogramma. |
| DISTINCT_RANGE_ROWS | Numero stimato di righe con un valore distinct di colonna compreso in un intervallo dell'istogramma, escluso il limite superiore. |
| AVG_RANGE_ROWS | Numero medio di righe con un valore di colonna duplicato compreso in un intervallo dell'istogramma, escluso il limite superiore. Quando DISTINCT_RANGE_ROWS è maggiore di 0, AVG_RANGE_ROWS viene calcolato dividendo RANGE_ROWS per DISTINCT_RANGE_ROWS. Quando DISTINCT_RANGE_ROWS è 0, AVG_RANGE_ROWS restituisce 1 per l'intervallo dell'istogramma. |
Osservazioni:
La data di aggiornamento delle statistiche viene archiviata nell'oggetto BLOB di statistiche insieme all'istogramma e al vettore di densità, non nei metadati. Quando non vengono letti dati per generare dati delle statistiche, il BLOB delle statistiche non viene creato, la data non è disponibile e la colonna aggiornata è NULL. Questo è il caso per le statistiche filtrate per cui il predicato non restituisce righe o per le nuove tabelle vuote.
Istogramma
Un istogramma misura la frequenza di occorrenza per ogni valore distinct in un set di dati. Query Optimizer calcola un istogramma nei valori di colonna nella prima colonna chiave dell'oggetto statistiche, selezionando i valori di colonna tramite il campionamento statistico delle righe o un'analisi completa di tutte le righe della tabella o della vista. Se l'istogramma viene creato da un set di righe campionato, i totali archiviati per il numero di righe e il numero di valori distinti sono stime e non devono essere interi.
Per creare l'istogramma, Query Optimizer ordina i valori di colonna, calcola il numero di valori che corrispondono a ogni valore distinct di colonna, quindi aggrega i valori di colonna in un massimo di 200 intervalli contigui dell'istogramma. Ogni intervallo comprende un insieme di valori di colonna seguiti da un valore di colonna pari al limite superiore. Nell'insieme sono inclusi tutti i possibili valori di colonna compresi tra i valori limite, esclusi questi ultimi. Il minore tra i valori di colonna ordinati costituisce il limite superiore per il primo intervallo dell'istogramma.
Nel diagramma seguente viene illustrato un istogramma con sei intervalli. L'area a sinistra del primo valore limite superiore è il primo intervallo.

Per ogni intervallo dell'istogramma:
- La riga in grassetto rappresenta il valore limite superiore (RANGE_HI_KEY) e il relativo numero di occorrenze (EQ_ROWS).
- L'area a tinta unita a sinistra di RANGE_HI_KEY rappresenta l'insieme di valori di colonna e il numero medio di occorrenze di ciascun valore (AVG_RANGE_ROWS) di colonna. Il valore AVG_RANGE_ROWS per il primo intervallo dell'istogramma è sempre 0.
- Le linee punteggiate rappresentano i valori campionati utilizzati per stimare il numero complessivo dei valori distinct nell'insieme (DISTINCT_RANGE_ROWS) e il numero complessivo dei valori nell'insieme (RANGE_ROWS). Query Optimizer usa RANGE_ROWS e DISTINCT_RANGE_ROWS per calcolare AVG_RANGE_ROWS e non archivia i valori campionati.
Query Optimizer definisce gli intervalli dell'istogramma in base al relativo significato statistico e utilizza un algoritmo per il calcolo della differenza massima per ridurre al minimo il numero di intervalli nell'istogramma, aumentando contemporaneamente la differenza tra i valori limite. Il numero massimo di intervalli è 200. Il numero di intervalli dell'istogramma può essere minore del numero di valori distinct, anche per le colonne con un numero di punti limite inferiore a 200. A una colonna con 100 valori distinct, ad esempio, può essere associato un istogramma con un numero di punti limite inferiore a 100.
Vettore di densità
Per ottimizzare le stime relative alla cardinalità per query che restituiscono più colonne della stessa tabella o vista indicizzata, Query Optimizer utilizza le densità. Il vettore di densità contiene una densità per ogni prefisso di colonna nell'oggetto statistiche. Se in un oggetto statistiche, ad esempio, sono presenti le colonne chiave CustomerId, ItemId e Price, la densità viene calcolata per ognuno dei prefissi di colonna seguenti.
| Prefisso di colonna | Densità calcolata su |
|---|---|
(CustomerId) |
Righe con valori corrispondenti per CustomerId |
(CustomerId, ItemId) |
Righe con valori corrispondenti per CustomerId e ItemId |
(CustomerId, ItemId, Price) |
Righe con valori corrispondenti per CustomerId, ItemId e Price |
Limiti
DBCC SHOW_STATISTICS non fornisce statistiche per gli indici spaziali né gli indici columnstore ottimizzati per la memoria.
Autorizzazioni per SQL Server e database SQL
Per visualizzare l'oggetto statistiche, l'utente deve avere l'autorizzazione SELECT per la tabella.
Affinché le autorizzazioni SELECT siano sufficienti per eseguire il comando, sono richiesti i requisiti seguenti:
- Gli utenti devono disporre delle autorizzazioni su tutte le colonne nell'oggetto statistiche
- Gli utenti devono disporre dell'autorizzazione su tutte le colonne in una condizione di filtro, se esistente
- La tabella non può avere criteri di sicurezza a livello di riga.
- Se una delle colonne all'interno di un oggetto statistiche è mascherata con regole Dynamic Data Masking, oltre all'autorizzazione
SELECT, l'utente deve disporre dell'autorizzazioneUNMASKo essere membro del ruolo db_ddladmin .
Nelle versioni precedenti a SQL Server 2012 (11.x) Service Pack 1, l'utente deve essere proprietario della tabella o l'utente deve essere membro del ruolo predefinito del server sysadmin , del ruolo predefinito del database db_owner o del ruolo predefinito del database db_ddladmin .
Nota
Per ripristinare il comportamento precedente a SQL Server 2012 (11.x) comportamento di Service Pack 1, usare il flag di traccia 9485.
Autorizzazioni per Azure Synapse Analytics e Piattaforma di strumenti analitici (PDW)
DBCC SHOW_STATISTICS richiede SELECT l'autorizzazione per la tabella o l'appartenenza al ruolo predefinito del server sysadmin , al ruolo predefinito del database db_owner o al ruolo predefinito del database db_ddladmin .
Limitazioni e restrizioni per Azure Synapse Analytics e Piattaforma di strumenti analitici (PDW)
DBCC SHOW_STATISTICS mostra le statistiche archiviate nel Shell database a livello di nodo di controllo. Non mostra statistiche create automaticamente da SQL Server nei nodi di calcolo.
DBCC SHOW_STATISTICS non è supportato nelle tabelle esterne.
In Microsoft Fabric DBCC SHOW_STATISTICS vengono visualizzati solo i risultati per le statistiche dell'istogramma, non le statistiche ACE-*.
Esempi: SQL Server e database SQL di Azure
R. Restituisce tutte le informazioni statistiche
Nell'esempio seguente vengono visualizzate tutte le informazioni sulle statistiche per l'indice AK_Address_rowguid della Person.Address tabella nel database AdventureWorks2022.
DBCC SHOW_STATISTICS ("Person.Address", AK_Address_rowguid);
GO
B. Specificare l'opzione HISTOGRAM
In questo modo le informazioni statistiche visualizzate per Customer_LastName vengono limitate ai dati HISTOGRAM.
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName) WITH HISTOGRAM;
GO
Esempi: Azure Synapse Analytics e Piattaforma di strumenti analitici (PDW)
C. Visualizzare il contenuto di un oggetto statistiche
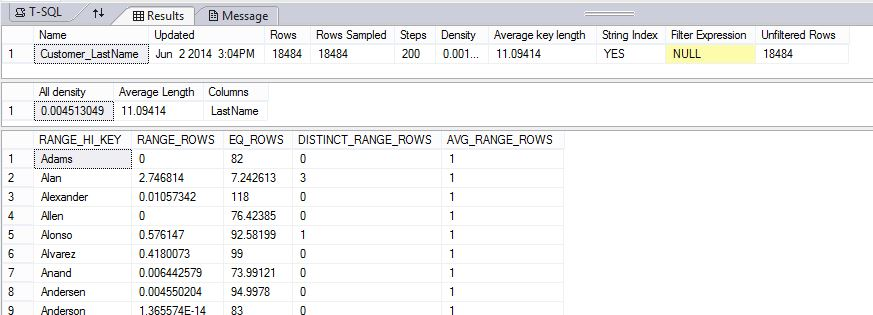
Nell'esempio seguente viene creato un oggetto statistiche e quindi viene visualizzato il contenuto delle Customer_LastName statistiche nella DimCustomer tabella nel database di esempio AdventureWorksPDW2022 .
-- Uses AdventureWorksPDW
--First, create a statistics object
CREATE STATISTICS Customer_LastName
ON AdventureWorksPDW2012.dbo.DimCustomer (LastName);
GO
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName);
GO
Nei risultati vengono visualizzati l'intestazione, il vettore di densità e parte dell'istogramma.
Vedi anche
- Statistica
- Statistiche in Microsoft Fabric
- sys.dm_db_stats_properties (Transact-SQL)
- sys.dm_db_stats_histogram (Transact-SQL)
- sys.dm_db_incremental_stats_properties (Transact-SQL)