Indici columnstore: Panoramica
Si applica a: ![]() SQL Server
SQL Server![]() database SQL di Azure
database SQL di Azure![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure ![]() database SQL di Azure Synapse Analytics Platform
database SQL di Azure Synapse Analytics Platform![]() System (PDW)
System (PDW) ![]() in Microsoft Fabric
in Microsoft Fabric
Gli indici columnstore rappresentano lo standard per l'archiviazione di tabelle dei fatti di data warehousing di grandi dimensioni e per l'esecuzione di query su queste tabelle. Questo indice usa l'archiviazione dei dati basata su colonne e l'elaborazione di query per ottenere miglioramenti fino a 10 volte per le prestazioni delle query nel data warehouse rispetto all'archiviazione tradizionale orientata alle righe. È anche possibile migliorare fino a 10 volte la compressione dei dati rispetto alla dimensione dei dati non compressi. A partire da SQL Server 2016 (13.x) SP1, gli indici columnstore consentono l'analisi operativa, rendendo possibile l'esecuzione di analisi in tempo reale ad alte prestazioni su carichi di lavoro transazionali.
Informazioni su uno scenario correlato:
- Indici columnstore nel data warehousing
- Introduzione a columnstore per l'analisi operativa in tempo reale
Che cos'è un indice columnstore?
L'indice columnstore è una tecnologia per l'archiviazione, il recupero e la gestione dei dati tramite un formato di dati in colonna, detto columnstore.
Termini e concetti chiave
I seguenti concetti e termini chiave sono associati agli indici columnstore.
Columnstore
Un indice columnstore è costituito da dati organizzati logicamente in una tabella con righe e colonne e archiviati fisicamente in un formato di dati a colonne.
Rowstore
Un indice rowstore è costituito da dati organizzati logicamente in una tabella con righe e colonne e archiviati fisicamente in un formato di dati a righe. Questo formato ha rappresentato il metodo tradizionale per archiviare dati relazionali di tabella. In SQL Server, rowstore fa riferimento alla tabella in cui il formato di archiviazione dati sottostante è un heap, un indice cluster o una tabella ottimizzata per la memoria.
Nota
Quando si parla di indici columnstore, i termini rowstore e columnstore vengono usati per sottolineare il formato per l'archiviazione dei dati.
Rowgroup
Un rowgroup è un gruppo di righe che vengono compresse contemporaneamente nel formato columnstore. Un rowgroup contiene in genere il numero massimo di righe per rowgroup, pari a 1.048.576 righe.
Per garantire prestazioni elevate e un alto tasso di compressione, l'indice columnstore suddivide la tabella in rowgroup, quindi comprime ogni rowgroup per colonne. Il numero di righe nel rowgroup deve essere sufficientemente grande da migliorare il tasso di compressione e sufficientemente ridotto da poter trarre vantaggio dall'esecuzione delle operazioni in memoria.
Un rowgroup da cui sono stati eliminati tutti i dati passa dallo stato COMPRESSED allo stato TOMBSTONE e viene successivamente rimosso da un processo in background denominato motore di tuple. Per altre informazioni sugli stati dei rowgroup, vedere sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Suggerimento
La presenza di un numero eccessivo di rowgroup di piccole dimensioni riduce la qualità dell'indice columnstore. Fino a SQL Server 2017 (14.x), è necessaria un'operazione di riorganizzazione per unire i rowgroup compressi più piccoli in base a un criterio di soglia interna, che determina come rimuovere le righe eliminate e combinare i rowgroup compressi.
A partire da SQL Server 2019 (15.x), un'attività di unione in background funziona anche per unire i rowgroup compressi da cui è stato eliminato un numero elevato di righe.
Dopo l'unione di rowgroup di dimensioni minori, è necessario migliorare la qualità dell'indice.
Nota
A partire da SQL Server 2019 (15.x), database SQL di Azure, Istanza gestita di SQL di Azure e i pool SQL dedicati in Azure Synapse Analytics, il motore di tuple viene aiutato da un'attività di unione in background, che comprime automaticamente i rowgroup delta aperti più piccoli che sono esistiti per un dato periodo di tempo (come determinato da una soglia interna) oppure unisce i rowgroup compressi da cui è stato eliminato un numero elevato di righe. In questo modo viene migliorata la qualità dell'indice columnstore nel tempo.
Segmento di colonna
Un segmento di colonna è una colonna di dati all'interno del rowgroup.
- Ogni rowgroup contiene un segmento di colonna per ogni colonna della tabella.
- Ogni segmento di colonna è compresso e archiviato su un supporto fisico.
- Sono presenti metadati con ogni segmento per consentire l'eliminazione rapida dei segmenti senza leggerli.
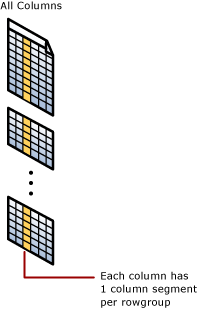
Indice columnstore cluster
Un indice columnstore cluster rappresenta l'archivio fisico per l'intera tabella.
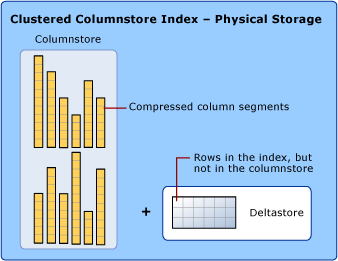
Per ridurre la frammentazione dei segmenti di colonna e migliorare le prestazioni, l'indice columnstore può archiviare temporaneamente alcuni dati in un indice cluster, detto deltastore, e in un elenco ad albero B di ID per le righe eliminate. Le operazioni deltastore sono gestite in modo automatico. Per tornare ai risultati della query corretti, l'indice columnstore cluster combina i risultati della query da columnstore e deltastore.
Nota
Nella documentazione viene usato in modo generico il termine albero B in riferimento agli indici. Negli indici rowstore, il motore di database implementa un albero B+. Ciò non si applica a indici columnstore o a indici in tabelle ottimizzate per la memoria. Per altre informazioni, vedere Architettura e guida per la progettazione degli indici di SQL Server e Azure SQL.
Rowgroup differenziale
Un rowgroup delta è un indice cluster dell'albero B che viene usato solo con indici columnstore. Migliora la compressione e le prestazioni dei columnstore archiviando le righe finché il numero di queste non raggiunge una soglia specifica (1.048.576 righe) e spostandole quindi nel columnstore.
Quando un rowgroup delta raggiunge il numero massimo di righe, passa dallo stato OPEN allo stato CLOSED. Un processo in background denominato motore di tuple controlla la presenza di rowgroup chiusi. Se il processo trova un rowgroup chiuso, comprime il rowgroup delta e lo archivia nel columnstore come rowgroup COMPRESSED.
Quando un rowgroup delta è stato compresso, il rowgroup delta esistente passa allo stato TOMBSTONE per essere poi rimosso dal motore di tuple quando non riceve nessun riferimento.
Per altre informazioni sugli stati dei rowgroup, vedere sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Nota
A partire da SQL Server 2019 (15.x), il motore di tuple viene aiutato da un'attività di unione in background, che comprime automaticamente i rowgroup delta aperti più piccoli che sono esistiti per un dato periodo di tempo (come determinato da una soglia interna) oppure unisce i rowgroup compressi da cui è stato eliminato un numero elevato di righe. In questo modo viene migliorata la qualità dell'indice columnstore nel tempo.
Deltastore
Un indice columnstore può includere più di un rowgroup differenziale. Tutti i rowgroup differenziali sono denominati collettivamente deltastore.
Durante un caricamento bulk di grandi dimensioni, la maggior parte delle righe viene direttamente indirizzata al columnstore senza passare per il deltastore. È possibile che alla fine del caricamento bulk il numero delle righe sia insufficiente a soddisfare le dimensioni minime di un rowgroup, pari a 102.400. Ne consegue che le righe finali vengono indirizzate al deltastore anziché al columnstore. Per i caricamenti bulk di piccole dimensioni, con meno di 102.400 righe, tutte le righe passano direttamente al deltastore.
indice columnstore non cluster
Un indice columnstore non cluster e un indice columnstore cluster funzionano allo stesso modo. La differenza è che un indice non cluster è un indice secondario creato per una tabella rowstore, mentre un indice columnstore cluster rappresenta l'archiviazione primaria per l'intera tabella.
L'indice non cluster contiene una copia totale o parziale delle righe e delle colonne della tabella sottostante. L'indice è definito sotto forma di una o più colonne della tabella e ha una condizione facoltativa che consente di filtrare le righe.
Un indice columnstore non cluster consente l'analisi operativa in tempo reale, durante la quale il carico di lavoro OLTP usa l'indice cluster sottostante, mentre l'analisi viene eseguita simultaneamente sull'indice columnstore. Per altre informazioni, vedere Introduzione a columnstore per l'analisi operativa in tempo reale.
Esecuzione in modalità batch
L'esecuzione in modalità batch è un metodo di elaborazione delle query con cui le query elaborano più righe contemporaneamente. L'esecuzione in modalità batch è strettamente integrata nel formato di archiviazione columnstore, per il quale è ottimizzata. L'esecuzione in modalità batch talvolta è detta esecuzione basata su vettore o vettorizzata. Le query sugli indici columnstore usano l'esecuzione in modalità batch, che migliora le prestazioni delle query in genere da due a quattro volte. Per altre informazioni, vedere Guida sull'architettura di elaborazione delle query.
Perché usare un indice columnstore?
Un indice columnstore può garantire un livello di compressione dei dati molto elevato, in genere di 10 volte, riducendo in modo significativo i costi di archiviazione del data warehouse. Per l'analisi, gli indici columnstore offrono anche prestazioni decisamente migliori rispetto agli indici dell'albero B. e rappresentano il formato di archiviazione di dati preferito per i carichi di lavoro di analisi e data warehousing. A partire da SQL Server 2016 (13.x), è possibile usare gli indici columnstore per l'analisi in tempo reale del carico di lavoro operativo.
Ecco perché gli indici columnstore sono così rapidi:
Le colonne archiviano valori provenienti dallo stesso dominio. Si tratta in genere di valori simili, il che consente un tasso di compressione elevato. I colli di bottiglia per le operazioni di I/O nel sistema sono ridotti al minimo o eliminati e il footprint di memoria viene ridotto significativamente.
Le frequenze di compressione elevate migliorano le prestazioni delle query utilizzando un footprint di memoria più piccolo. A loro volta, le prestazioni delle query costituiscono un miglioramento perché SQL Server può eseguire un numero maggiore di operazioni di dati e query in memoria.
L'esecuzione batch migliora le prestazioni delle query, in genere, da due a quattro volte grazie all'elaborazione di più righe contemporaneamente.
Le query spesso selezionano solo alcune colonne di una tabella, riducendo il totale delle operazioni di I/O su un supporto fisico.
Quando usare un indice columnstore?
Usi consigliati:
Usare un indice columnstore cluster per archiviare tabelle dei fatti e tabelle di grandi dimensioni per i carichi di lavoro di data warehousing. Questo metodo migliora le prestazioni delle query e la compressione dei dati fino a 10 volte. Per altre informazioni, vedere Indici columnstore per il data warehousing.
Usare un indice columnstore non cluster per eseguire l'analisi in tempo reale di un carico di lavoro OLTP. Per altre informazioni, vedere Introduzione a columnstore per l'analisi operativa in tempo reale.
Per altri scenari di utilizzo per gli indici columnstore, vedere Scegliere l'indice columnstore migliore per le proprie esigenze.
Come scegliere tra un indice rowstore e un indice columnstore?
Gli indici rowstore offrono prestazioni ottimali con le query che eseguono la ricerca di un valore specifico o all'interno di un intervallo di valori di piccole dimensioni. Usare gli indici rowstore con carichi di lavoro transazionali, poiché per i carichi di lavoro di questo tipo sono in genere necessarie ricerche all'interno delle tabelle anziché scansioni di queste.
Gli indici columnstore garantiscono prestazioni notevolmente elevate per le query analitiche su grandi quantità di dati, soprattutto per le tabelle di grandi dimensioni. Usare gli indici columnstore per i carichi di lavoro di data warehousing e analisi, soprattutto sulle tabelle dei fatti, poiché in genere questi carichi di lavoro richiedono scansioni complete delle tabelle anziché ricerche all'interno di queste.
Gli indici columnstore cluster ordinati migliorano le prestazioni per le query in base ai predicati di colonna ordinati. Gli indici columnstore ordinati possono migliorare l'eliminazione di gruppi di righe, che possono offrire miglioramenti delle prestazioni ignorando del tutto i gruppi di righe. Per altre informazioni, vedere Ottimizzazione delle prestazioni con indici columnstore cluster ordinati. Per la disponibilità dell'indice columnstore ordinato, vedere Disponibilità dell'indice di colonna ordinata.
È possibile combinare indici rowstore e columnstore nella stessa tabella?
Sì. A partire da SQL Server 2016 (13.x), è possibile creare un indice columnstore non cluster aggiornabile in una tabella rowstore. L'indice columnstore archivia una copia delle colonne selezionate. È quindi necessario spazio aggiuntivo per questi dati, ma la compressione applicata ai dati selezionati è in media di 10 volte. È possibile eseguire allo stesso tempo analisi sull'indice columnstore e transazioni sull'indice rowstore. Il columnstore viene aggiornato quando i dati nella tabella rowstore vengono modificati. In questo modo entrambi gli indici possono usare gli stessi dati.
A partire da SQL Server 2016 (13.x), è possibile avere uno o più indici rowstore non cluster su un indice columnstore ed eseguire ricerche efficienti in tabelle nel columnstore sottostante. Sono disponibili anche altre opzioni. È possibile, ad esempio, applicare un vincolo di chiave primaria tramite un vincolo UNIQUE nella tabella rowstore. Dato che non è possibile inserire un valore non univoco nella tabella rowstore, SQL Server non può inserire il valore nel columnstore.
Indici columnstore ordinati
Abilitando l'eliminazione efficiente dei segmenti, gli indici columnstore cluster ordinati offrono prestazioni molto più veloci ignorando grandi quantità di dati ordinati che non corrispondono al predicato di query. Il caricamento dei dati in una tabella con CCI ordinato può richiedere più tempo rispetto a una tabella con CCI non ordinato a causa dell'operazione di ordinamento dei dati, tuttavia le query possono essere eseguite più velocemente in seguito con un CCI ordinato.
- Per altre informazioni sull'ottimizzazione delle prestazioni dei carichi di lavoro di data warehousing nel motore di database SQL con indici columnstore cluster ordinati, vedere Ottimizzazione delle prestazioni con indici columnstore cluster ordinati.
- Per altre informazioni su quando usare il tipo di indice columnstore, vedere Scegliere l'indice columnstore migliore per le proprie esigenze.
Disponibilità dell'indice columnstore ordinato
Introdotta per la prima volta con ![]() SQL Server 2022 (16.x), gli indici columnstore ordinati sono disponibili nelle piattaforme seguenti.
SQL Server 2022 (16.x), gli indici columnstore ordinati sono disponibili nelle piattaforme seguenti.
| Piattaforma | Indici columnstore cluster ordinati | Indici columnstore non cluster ordinati |
|---|---|---|
| Database SQL di Azure | Sì | Sì |
| Database SQL in Microsoft Fabric | Sì* | Sì |
| SQL Server 2022 (16.x) | Sì | No |
| Istanza gestita di SQL di Azure | Sì | Sì |
| Pool SQL dedicato in Azure Synapse Analytics | Sì | No |
* Nel database SQL di Infrastruttura le tabelle con indici columnstore cluster non vengono rispecchiate in Fabric OneLake.
Metadati UFX
Tutte le colonne di un indice columnstore vengono archiviate nei metadati come colonne incluse. L'indice columnstore non contiene colonne chiave.
Attività correlate
Tutte le tabelle relazionali, se non specificate come indice columnstore cluster, usano rowstore come formato dei dati sottostanti. CREATE TABLE crea una tabella rowstore, a meno che non si specifichi l'opzione WITH CLUSTERED COLUMNSTORE INDEX.
Quando si crea una tabella con l'istruzione CREATE TABLE è possibile creare la tabella come columnstore specificando l'opzione WITH CLUSTERED COLUMNSTORE INDEX. Se si ha già una tabella rowstore e si vuole convertirla in una tabella columnstore, è possibile usare l'istruzione CREATE COLUMNSTORE INDEX.
| Attività | Articoli di riferimento | Note |
|---|---|---|
| Creare una tabella come columnstore. | CREATE TABLE (Transact-SQL) | A partire da SQL Server 2016 (13.x), è possibile creare la tabella come indice columnstore cluster. Non è necessario creare prima una tabella rowstore e quindi convertirla in columnstore. |
| Creare una tabella ottimizzata per la memoria con un indice columnstore. | CREATE TABLE (Transact-SQL) | A partire da SQL Server 2016 (13.x), è possibile creare una tabella ottimizzata per la memoria con un indice columnstore. L'indice columnstore può anche essere aggiunto dopo aver creato la tabella, usando la sintassi ALTER TABLE ADD INDEX. |
| Convertire una tabella rowstore in un columnstore. | CREATE COLUMNSTORE INDEX (Transact-SQL) | Convertire un heap o albero B esistente o in un columnstore. Gli esempi illustrano come gestire gli indici esistenti e il nome dell'indice quando si esegue questa conversione. |
| Convertire una tabella columnstore in un rowstore. | CREATE CLUSTERED INDEX (Transact-SQL) oppure Convertire una tabella columnstore di nuovo in un heap rowstore | Di solito non è necessario eseguire questa conversione, ma talvolta potrebbe presentarsene la necessità. Gli esempi illustrano come convertire un columnstore in un heap o in un indice cluster. |
| Creare un indice columnstore per una tabella rowstore. | CREATE COLUMNSTORE INDEX (Transact-SQL) | Una tabella rowstore può avere un solo indice columnstore. A partire da SQL Server 2016 (13.x), l'indice columnstore può avere una condizione di filtro. Gli esempi illustrano la sintassi di base. |
| Creare indici ad alte prestazioni per l'analisi operativa. | Introduzione a columnstore per l'analisi operativa in tempo reale | Descrive come creare indici columnstore e indici albero B complementari in modo che le query OLTP usino gli indici albero B e le query di analisi usino gli indici columnstore. |
| Creare indici columnstore efficienti per il data warehousing. | Indici columnstore per il data warehousing | Descrive come usare gli indici albero B con le tabelle columnstore per creare query di data warehousing ad alte prestazioni. |
| Usare un indice albero B per imporre un vincolo di chiave primaria per un indice columnstore. | Indici columnstore per il data warehousing | Illustra come combinare indici albero B e indici columnstore per imporre vincoli di chiave primaria per l'indice columnstore. |
| Rimuovere un indice columnstore. | DROP INDEX (Transact-SQL) | Per rimuovere un indice columnstore si usa la sintassi DROP INDEX standard usata dagli indici dell'albero B. La rimozione di un indice columnstore cluster converte la tabella columnstore in un heap. |
| Eliminare una riga da un indice columnstore. | DELETE (Transact-SQL) | Usare DELETE (Transact-SQL) per eliminare una riga. Riga columnstore: SQL Server contrassegna la riga come eliminata logicamente ma recupera lo spazio di archiviazione fisico della riga solo dopo che l'indice è stato ricompilato. Riga deltastore: SQL Server elimina la riga logicamente e fisicamente. |
| Aggiornare una riga nell'indice columnstore. | UPDATE (Transact-SQL) | Usare UPDATE (Transact-SQL) per aggiornare una riga. Riga columnstore: SQL Server contrassegna la riga come eliminata logicamente e quindi inserisce la riga aggiornata nel deltastore. Riga deltastore: SQL Server aggiorna la riga nel deltastore. |
| Caricare dati in un indice columnstore. | Caricamento dei dati di indici columnstore | |
| Forzare il passaggio di tutte le righe del deltastore nel columnstore. | ALTER INDEX (Transact-SQL) ... REBUILDOttimizzare la manutenzione dell'indice per migliorare le prestazioni delle query e ridurre il consumo di risorse |
ALTER INDEX con l'opzione REBUILD forza il passaggio di tutte le righe nel columnstore. |
| Deframmentare un indice columnstore. | ALTER INDEX (Transact-SQL) | ALTER INDEX ... REORGANIZE consente di deframmentare indici columnstore online. |
| Unire tabelle con indici columnstore. | MERGE (Transact-SQL) |
Contenuto correlato
- Novità degli indici columnstore
- Indici columnstore - Linee guida per il caricamento di dati
- Indici columnstore - Prestazioni delle query
- Introduzione a columnstore per l'analisi operativa in tempo reale
- Indici columnstore nel data warehousing
- Deframmentazione degli indici columnstore
- Architettura e guida per la progettazione degli indici di SQL Server
- Architettura degli indici columnstore
- CREATE COLUMNSTORE INDEX (Transact-SQL)