Creare e configurare un gruppo di disponibilità per SQL Server in Linux
Si applica a: ![]() SQL Server - Linux
SQL Server - Linux
Questa esercitazione illustra come creare e configurare un gruppo di disponibilità per SQL Server in Linux. A differenza di SQL Server 2016 (13.x) e versioni precedenti in Windows, è possibile abilitare i gruppi di disponibilità sia che si crei o non si crei prima il cluster Pacemaker sottostante. L'integrazione con il cluster, se necessaria, viene eseguita solo in un momento successivo.
L'esercitazione include le attività seguenti:
- Abilitare i gruppi di disponibilità.
- Creare endpoint e certificati per i gruppi di disponibilità.
- Usare SQL Server Management Studio (SSMS) o Transact-SQL per creare un gruppo di disponibilità.
- Creare l'account di accesso di SQL server e le autorizzazioni per Pacemaker.
- Creare risorse dei gruppi di disponibilità in un cluster Pacemaker (solo di tipo Esterno).
Prerequisiti
Distribuire il cluster a disponibilità elevata Pacemaker come descritto in Distribuire un cluster Pacemaker per SQL Server in Linux.
Abilitare la funzionalità dei gruppi di disponibilità
Diversamente da Windows, non è possibile usare PowerShell o Gestione configurazione SQL Server per abilitare la funzionalità dei gruppi di disponibilità. In Linux è necessario usare mssql-conf per abilitare la funzionalità. È possibile abilitare la funzionalità dei gruppi di disponibilità in due modi: usando l'utilità mssql-conf o modificando il file mssql.conf manualmente.
Importante
La funzionalità dei gruppi di disponibilità deve essere abilitata per le repliche di sola configurazione, anche in SQL Server Express.
Usare l'utilità mssql-conf
Alla richiesta, eseguire il comando seguente:
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
Modificare il file mssql.conf
È anche possibile modificare il file mssql.conf, che si trova nella cartella /var/opt/mssql, aggiungendo le righe seguenti:
[hadr]
hadr.hadrenabled = 1
Riavviare SQL Server
Come in Windows, dopo aver abilitato i gruppi di disponibilità è necessario riavviare SQL Server con il comando seguente:
sudo systemctl restart mssql-server
Creare endpoint e certificati del gruppo di disponibilità
Un gruppo di disponibilità usa gli endpoint TCP per le comunicazioni. In Linux gli endpoint per un gruppo di disponibilità sono supportati solo se per l'autenticazione vengono usati i certificati. È necessario ripristinare il certificato di un'istanza in tutte le altre istanze che saranno repliche che fanno parte dello stesso gruppo di disponibilità. Il processo di autenticazione tramite certificato è necessario anche per una replica di sola configurazione.
La creazione degli endpoint e il ripristino dei certificati possono essere eseguiti solo tramite Transact-SQL. Si possono usare anche certificati non generati da SQL Server. È necessario anche un processo per gestire e sostituire eventuali certificati scaduti.
Importante
Se si prevede di usare la procedura guidata di SQL Server Management Studio per creare il gruppo di disponibilità, è comunque necessario creare e ripristinare i certificati usando Transact-SQL in Linux.
Per la sintassi completa delle opzioni disponibili per i vari comandi (inclusa la sicurezza), vedere:
Nota
Anche se si sta creando un gruppo di disponibilità, il tipo di endpoint usa FOR DATABASE_MIRRORING, perché alcuni aspetti sottostanti erano condivisi con questa funzionalità ormai deprecata.
In questo esempio vengono creati i certificati per una configurazione a tre nodi. I nomi delle istanze sono LinAGN1, LinAGN2 e LinAGN3.
Eseguire il codice seguente in
LinAGN1per creare la chiave master, il certificato e l'endpoint e per eseguire il backup del certificato. In questo esempio per l'endpoint viene usata la porta TCP standard 5022.CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN1_Cert WITH SUBJECT = 'LinAGN1 AG Certificate'; GO BACKUP CERTIFICATE LinAGN1_Cert TO FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN1_Cert, ROLE = ALL ); GOEseguire la stessa operazione in
LinAGN2:CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN2_Cert WITH SUBJECT = 'LinAGN2 AG Certificate'; GO BACKUP CERTIFICATE LinAGN2_Cert TO FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN2_Cert, ROLE = ALL ); GOInfine, eseguire la stessa sequenza in
LinAGN3:CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN3_Cert WITH SUBJECT = 'LinAGN3 AG Certificate'; GO BACKUP CERTIFICATE LinAGN3_Cert TO FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN3_Cert, ROLE = ALL ); GOUsando
scpo un'altra utilità, copiare i backup del certificato in ogni nodo che farà parte del gruppo di disponibilità.Per questo esempio:
- Copiare
LinAGN1_Cert.cerinLinAGN2eLinAGN3. - Copiare
LinAGN2_Cert.cerinLinAGN1eLinAGN3. - Copiare
LinAGN3_Cert.cerinLinAGN1eLinAGN2.
- Copiare
Cambiare la proprietà e il gruppo associato ai file di certificato copiati in
mssql.sudo chown mssql:mssql <CertFileName>Creare gli account di accesso a livello di istanza e gli utenti associati a
LinAGN2eLinAGN3inLinAGN1.CREATE LOGIN LinAGN2_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN2_User FOR LOGIN LinAGN2_Login; GO CREATE LOGIN LinAGN3_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN3_User FOR LOGIN LinAGN3_Login; GOAttenzione
La password deve seguire i criteri password predefiniti di SQL Server. Per impostazione predefinita, la password deve essere composta da almeno otto caratteri e contenere caratteri di tre delle quattro categorie seguenti: lettere maiuscole, lettere minuscole, cifre in base 10 e simboli. Le password possono contenere fino a 128 caratteri. Usare password il più possibile lunghe e complesse.
Ripristinare
LinAGN2_CerteLinAGN3_CertinLinAGN1. La presenza dei certificati delle altre repliche è un aspetto importante della comunicazione e della sicurezza dei gruppi di disponibilità.CREATE CERTIFICATE LinAGN2_Cert AUTHORIZATION LinAGN2_User FROM FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GO CREATE CERTIFICATE LinAGN3_Cert AUTHORIZATION LinAGN3_User FROM FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GOConcedere agli account di accesso associati a
LinAG2eLinAGN3l'autorizzazione per la connessione all'endpoint inLinAGN1.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN2_Login; GO GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN3_Login; GOCreare gli account di accesso a livello di istanza e gli utenti associati a
LinAGN1eLinAGN3inLinAGN2.CREATE LOGIN LinAGN1_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN1_User FOR LOGIN LinAGN1_Login; GO CREATE LOGIN LinAGN3_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN3_User FOR LOGIN LinAGN3_Login; GORipristinare
LinAGN1_CerteLinAGN3_CertinLinAGN2.CREATE CERTIFICATE LinAGN1_Cert AUTHORIZATION LinAGN1_User FROM FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE CERTIFICATE LinAGN3_Cert AUTHORIZATION LinAGN3_User FROM FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GOConcedere agli account di accesso associati a
LinAG1eLinAGN3l'autorizzazione per la connessione all'endpoint inLinAGN2.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN1_Login; GO GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN3_Login; GOCreare gli account di accesso a livello di istanza e gli utenti associati a
LinAGN1eLinAGN2inLinAGN3.CREATE LOGIN LinAGN1_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN1_User FOR LOGIN LinAGN1_Login; GO CREATE LOGIN LinAGN2_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN2_User FOR LOGIN LinAGN2_Login; GORipristinare
LinAGN1_CerteLinAGN2_CertinLinAGN3.CREATE CERTIFICATE LinAGN1_Cert AUTHORIZATION LinAGN1_User FROM FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE CERTIFICATE LinAGN2_Cert AUTHORIZATION LinAGN2_User FROM FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GOConcedere agli account di accesso associati a
LinAG1eLinAGN2l'autorizzazione per la connessione all'endpoint inLinAGN3.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN1_Login; GO GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN2_Login; GO
Creare il gruppo di disponibilità
Questa sezione illustra come usare SQL Server Management Studio (SSMS) o Transact-SQL per creare il gruppo di disponibilità per SQL Server.
Usare SQL Server Management Studio
Questa sezione illustra come creare un gruppo di disponibilità con un tipo di cluster esterno usando SSMS con la Creazione guidata gruppo di disponibilità.
In SSMS espandere Disponibilità elevata Always On, fare clic con il pulsante destro del mouse su Gruppi di disponibilità e scegliere Creazione guidata Gruppo di disponibilità.
Nella finestra di dialogo Introduzione selezionare Avanti.
Nella finestra di dialogo Specificare le opzioni del gruppo di disponibilità immettere un nome per il gruppo di disponibilità e selezionare il tipo di cluster
EXTERNALoNONEnell'elenco a discesa. Per distribuire Pacemaker occorre usare il tipo Esterno. Nessuno è destinato a scenari specializzati, ad esempio la scalabilità in lettura. La selezione dell'opzione per il rilevamento dell'integrità a livello di database è facoltativa. Per altre informazioni su questa opzione, vedere Opzione di failover di rilevamento dell'integrità a livello di database di un gruppo di disponibilità. Selezionare Avanti.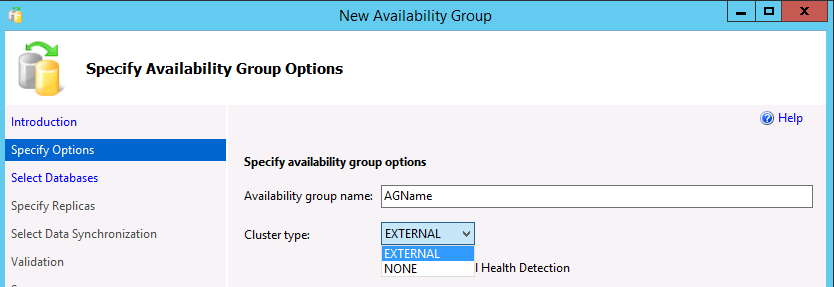
Nella finestra di dialogo Seleziona database selezionare i database che faranno parte del gruppo di disponibilità. Prima di aggiungere ogni database a un gruppo di disponibilità è necessario effettuarne un backup completo. Selezionare Avanti.
Nella finestra di dialogo Specifica repliche selezionare Aggiungi replica.
Nella finestra di dialogo Connetti al server immettere il nome dell'istanza di Linux di SQL Server che costituirà la replica secondaria e le credenziali per la connessione. Selezionare Connetti.
Ripetere i due passaggi precedenti per l'istanza che conterrà una replica di sola configurazione o un'altra replica secondaria.
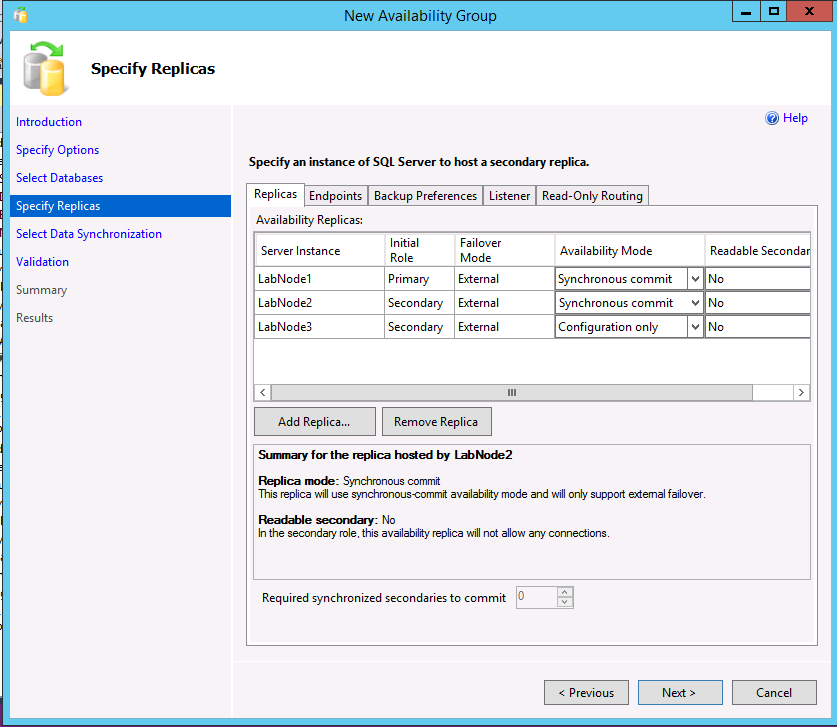
Ora tutte e tre le istanze dovrebbero essere elencate nella finestra di dialogo Specifica repliche. Se si usa il tipo di cluster Esterno, per la replica secondaria assicurarsi che la modalità di disponibilità corrisponda a quella della replica primaria e che la modalità di failover sia impostata su Esterno. Per la replica di sola configurazione, selezionare la modalità di disponibilità Sola configurazione.
L'esempio seguente illustra un gruppo di disponibilità con due repliche, un cluster di tipo Esterno e una replica di sola configurazione.
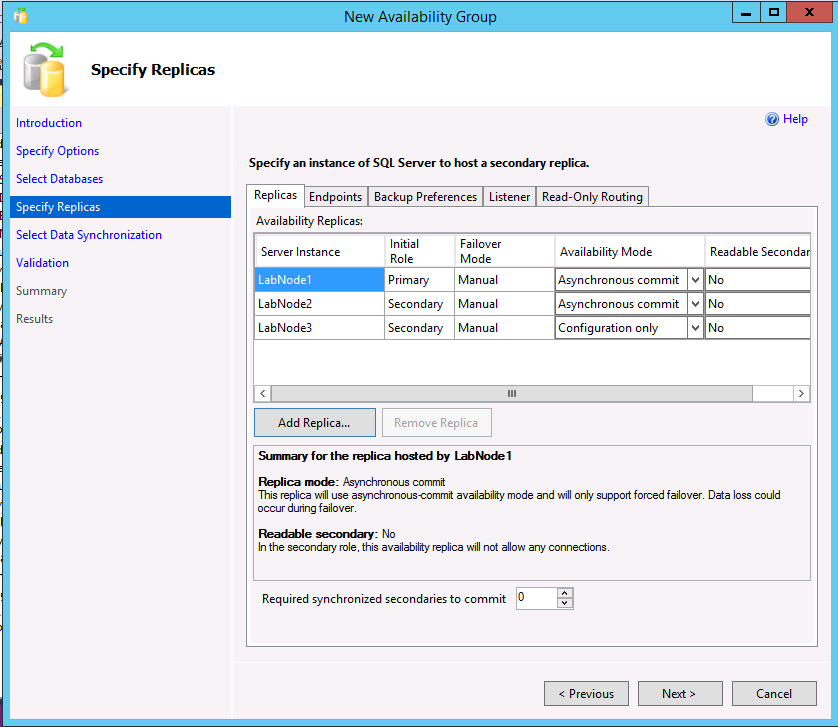
L'esempio seguente illustra un gruppo di disponibilità con due repliche, un cluster di tipo Nessuno e una replica di sola configurazione.
Se si vogliono modificare le preferenze di backup, selezionare la scheda Preferenze di backup. Per altre informazioni sulle preferenze di backup con i gruppi di disponibilità, vedere Configurare backup in repliche secondarie per un gruppo di disponibilità Always On.
Se si usano repliche secondarie leggibili o si crea un gruppo di disponibilità con un cluster di tipo Nessuno per la scalabilità in lettura, è possibile creare un listener selezionando la scheda Listener. Un listener può anche essere aggiunto in un secondo momento. Per creare un listener, scegliere l'opzione Crea un listener del gruppo di disponibilità e immettere un nome e una porta TCP/IP, oltre a specificare se usare un indirizzo IP DHCP statico o assegnato automaticamente. Tenere presente che per un gruppo di disponibilità con un tipo di cluster Nessuno l'indirizzo IP deve essere statico e impostato sull'indirizzo IP della replica primaria.
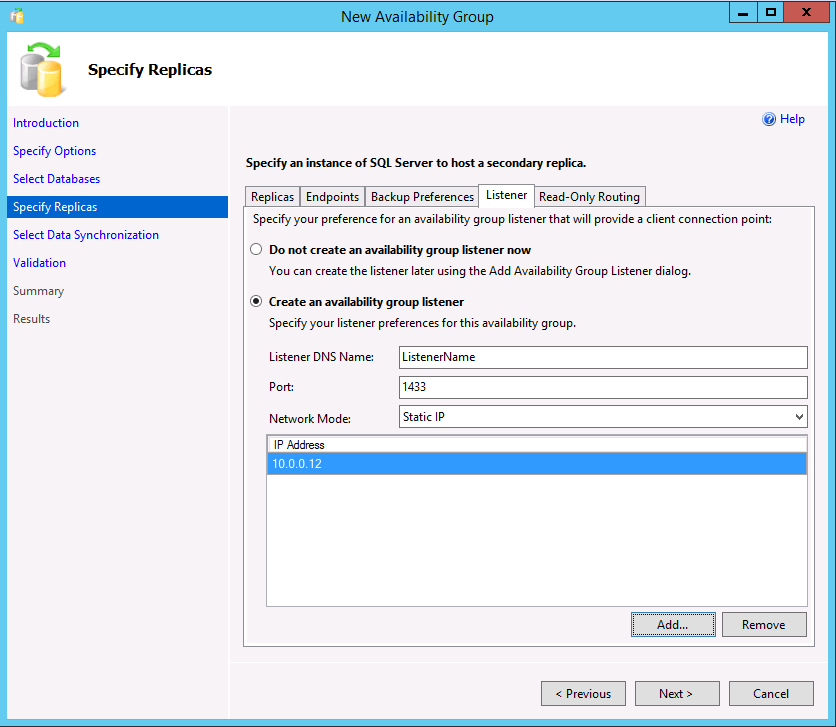
Se si crea un listener per scenari di repliche leggibili, SSMS 17.3 o versioni successive consente la creazione del routing di sola lettura nella procedura guidata. Il listener può anche essere aggiunto successivamente tramite SSMS o Transact-SQL. Per aggiungere subito il routing di sola lettura:
Selezionare la scheda Routing di sola lettura.
Immettere gli URL per le repliche di sola lettura. Questi URL sono simili agli endpoint, ad eccezione del fatto che usano la porta dell'istanza, non l'endpoint.
Selezionare ogni URL e nella parte inferiore selezionare le repliche leggibili. Per effettuare una selezione multipla, tenere premuto MAIUSC o selezionare e trascinare.
Selezionare Avanti.
Specificare la modalità di inizializzazione delle repliche secondarie. L'impostazione predefinita prevede l'uso del seeding automatico, che richiede lo stesso percorso in tutti i server che fanno parte del gruppo di disponibilità. È anche possibile indicare alla procedura guidata di eseguire un backup, una copia e un ripristino (seconda opzione), di procedere con l'aggiunta se è stato eseguito manualmente il backup, la copia e il ripristino del database nelle repliche (terza opzione) o di aggiungere il database in un secondo momento (ultima opzione). Come accade con i certificati, se si eseguono manualmente i backup e li si copia, le autorizzazioni per i file di backup devono essere impostate sulle altre repliche. Selezionare Avanti.
Se nella finestra di dialogo Convalida alcune operazioni sono indicate come non riuscite, ricercarne la causa. Alcuni avvisi sono accettabili e non indicano errori irreversibili, ad esempio nel caso in cui non si crea un listener. Selezionare Avanti.
Nella finestra di dialogo Riepilogo selezionare Fine. Viene avviato il processo di creazione del gruppo di disponibilità.
Una volta completata la creazione del gruppo di disponibilità, selezionare Chiudi nella finestra Risultati. Ora è possibile vedere il gruppo di disponibilità nelle repliche nelle viste a gestione dinamica (DMV) e nella cartella Disponibilità elevata Always On in SSMS.




Usare Transact-SQL
Questa sezione illustra alcuni esempi di creazione di un gruppo di disponibilità tramite Transact-SQL. Il listener e il routing di sola lettura possono essere configurati dopo la creazione del gruppo di disponibilità. Il gruppo di disponibilità stesso può essere modificato con ALTER AVAILABILITY GROUP, ma il tipo di cluster non può essere modificato in SQL Server 2017 (14.x). Se non si intende creare un gruppo di disponibilità con un cluster di tipo Esterno, è necessario eliminarlo e ricrearlo con un cluster di tipo Nessuno. Per altre informazioni e altre opzioni, vedere i collegamenti seguenti:
- CREATE AVAILABILITY GROUP (Transact-SQL)
- ALTER AVAILABILITY GROUP (Transact-SQL)
- Configurare il routing di sola lettura per un gruppo di disponibilità Always On
- Configurare un listener per un gruppo di disponibilità Always On
Esempio A - Due repliche con una replica di sola configurazione (cluster di tipo Esterno)
Questo esempio illustra come creare un gruppo di disponibilità con due repliche che usa una replica di sola configurazione.
Eseguire il codice di esempio sul nodo che sarà la replica primaria contenente la copia con funzioni di lettura/scrittura complete dei database. Questo esempio usa il seeding automatico.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = EXTERNAL) FOR DATABASE <DBName> REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N' TCP://LinAGN1.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC), N'LinAGN3' WITH ( ENDPOINT_URL = N'TCP://LinAGN3.FullyQualified.Name:5022', AVAILABILITY_MODE = CONFIGURATION_ONLY); GOIn una finestra di query connessa all'altra replica eseguire il codice seguente per aggiungere la replica al gruppo di disponibilità e avviare il processo di seeding dalla replica primaria alla replica secondaria.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GOIn una finestra di query connessa alla replica di sola configurazione aggiungere la replica al gruppo di disponibilità.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO
Esempio B - Tre repliche con routing di sola lettura (cluster di tipo Esterno)
Questo esempio mostra tre repliche complete e illustra il modo in cui il routing di sola lettura può essere configurato nell'ambito della creazione del gruppo di disponibilità iniziale.
Eseguire il codice di esempio sul nodo che sarà la replica primaria contenente la copia con funzioni di lettura/scrittura complete dei database. Questo esempio usa il seeding automatico.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = EXTERNAL) FOR DATABASE < DBName > REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N'TCP://LinAGN1.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN2.FullyQualified.Name', 'LinAGN3.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN1.FullyQualified.Name:1433') ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN1.FullyQualified.Name', 'LinAGN3.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN2.FullyQualified.Name:1433') ), N'LinAGN3' WITH ( ENDPOINT_URL = N'TCP://LinAGN3.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN1.FullyQualified.Name', 'LinAGN2.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN3.FullyQualified.Name:1433') ) LISTENER '<ListenerName>' ( WITH IP = ('<IPAddress>', '<SubnetMask>'), Port = 1433 ); GOEcco alcuni aspetti da considerare per questa configurazione:
AGNameè il nome del gruppo di disponibilità.DBNameè il nome del database che viene usato con il gruppo di disponibilità. Può anche essere un elenco di nomi separati da virgole.ListenerNameè un nome diverso da qualsiasi nodo/server sottostante. Verrà registrato nel DNS insieme aIPAddress.IPAddressè un indirizzo IP associato aListenerName. È inoltre univoco e non corrisponde ad alcuno dei server/nodi. Le applicazioni e gli utenti finali userannoListenerNameoIPAddressper connettersi al gruppo di disponibilità.SubnetMaskè la subnet mask diIPAddress. In SQL Server 2019 (15.x) e nelle versioni precedenti si tratta di255.255.255.255. In SQL Server 2022 (16.x) e nelle versioni successive si tratta di0.0.0.0.
In una finestra di query connessa all'altra replica eseguire il codice seguente per aggiungere la replica al gruppo di disponibilità e avviare il processo di seeding dalla replica primaria alla replica secondaria.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GORipetere il passaggio 2 per la terza replica.
Esempio C - Due repliche con routing di sola lettura (cluster di tipo Nessuno)
Questo esempio illustra la creazione di una configurazione a due repliche che usa un cluster di tipo Nessuno. Viene usata per lo scenario di scalabilità in lettura in cui non è previsto alcun failover. Viene creato il listener che è effettivamente la replica primaria, oltre al routing di sola lettura, usando la funzionalità di round robin.
- Eseguire il codice di esempio sul nodo che sarà la replica primaria contenente la copia con funzioni di lettura/scrittura complete dei database. Questo esempio usa il seeding automatico.
CREATE AVAILABILITY
GROUP [<AGName>]
WITH (CLUSTER_TYPE = NONE)
FOR DATABASE <DBName> REPLICA ON
N'LinAGN1' WITH (
ENDPOINT_URL = N'TCP://LinAGN1.FullyQualified.Name: <PortOfEndpoint>',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
PRIMARY_ROLE(
ALLOW_CONNECTIONS = READ_WRITE,
READ_ONLY_ROUTING_LIST = (('LinAGN1.FullyQualified.Name'.'LinAGN2.FullyQualified.Name'))
),
SECONDARY_ROLE(
ALLOW_CONNECTIONS = ALL,
READ_ONLY_ROUTING_URL = N'TCP://LinAGN1.FullyQualified.Name:<PortOfInstance>'
)
),
N'LinAGN2' WITH (
ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:<PortOfEndpoint>',
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC,
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = (
('LinAGN1.FullyQualified.Name',
'LinAGN2.FullyQualified.Name')
)),
SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN2.FullyQualified.Name:<PortOfInstance>')
),
LISTENER '<ListenerName>' (WITH IP = (
'<PrimaryReplicaIPAddress>',
'<SubnetMask>'),
Port = <PortOfListener>
);
GO
Dove:
AGNameè il nome del gruppo di disponibilità.DBNameè il nome del database che verrà usato con il gruppo di disponibilità. Può anche essere un elenco di nomi separati da virgole.PortOfEndpointè il numero di porta usato dall'endpoint creato.PortOfInstanceè il numero di porta usato dall'istanza d SQL Server.ListenerNameè un nome diverso da qualsiasi replica sottostante, ma non viene effettivamente usato.PrimaryReplicaIPAddressè l'indirizzo IP della replica primaria.SubnetMaskè la subnet mask diIPAddress. In SQL Server 2019 (15.x) e nelle versioni precedenti si tratta di255.255.255.255. In SQL Server 2022 (16.x) e nelle versioni successive si tratta di0.0.0.0.
Aggiungere la replica secondaria al gruppo di disponibilità e avviare il seeding automatico.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = NONE); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GO
Creare l'account di accesso di SQL server e le autorizzazioni per Pacemaker
Un cluster a disponibilità elevata Pacemaker sottostante a SQL Server in Linux deve poter accedere all'istanza di SQL Server e deve avere le autorizzazioni per il gruppo di disponibilità stesso. La procedura seguente crea l'account di accesso e le autorizzazioni associate, oltre a un file che indica a Pacemaker come accedere a SQL Server.
In una finestra di query connessa alla prima replica eseguire lo script seguente:
CREATE LOGIN PMLogin WITH PASSWORD ='<password>'; GO GRANT VIEW SERVER STATE TO PMLogin; GO GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::<AGThatWasCreated> TO PMLogin; GONel nodo 1 immettere il comando
sudo emacs /var/opt/mssql/secrets/passwdSi apre l'editor Emacs.
Immettere le due righe seguenti nell'editor:
PMLogin <password>Tenere premuto
Ctrle premereX, quindiCper uscire e salvare il file.Execute
sudo chmod 400 /var/opt/mssql/secrets/passwdper bloccare il file.
Ripetere i passaggi 1-5 negli altri server che fungeranno da repliche.
Creare le risorse dei gruppi di disponibilità nel cluster Pacemaker (solo di tipo Esterno)
Dopo aver creato un gruppo di disponibilità in SQL Server, è necessario creare le risorse corrispondenti in Pacemaker, quando viene specificato un tipo di cluster Esterno. A un gruppo di disponibilità sono associate due risorse: il gruppo di disponibilità stesso e un indirizzo IP. La configurazione della risorsa indirizzo IP è facoltativa se non si usa la funzionalità del listener, ma è tuttavia consigliata.
La risorsa gruppo di disponibilità creata è un tipo di risorsa chiamata clone. Sono presenti copie di questa risorsa in ogni nodo, con una risorsa con funzioni di controllo detta risorsa master. La risorsa master è associata al server che ospita la replica primaria. Le altre risorse ospitano le repliche secondarie (normali o di sola configurazione) e possono essere alzate al livello master in un failover.
Nota
Comunicazione senza distorsione
Questo articolo contiene riferimenti al termine slave, un termine che Microsoft considera offensivo se usato in questo contesto. Il termine viene visualizzato in questo articolo perché è attualmente incluso nel software. Quando il termine verrà rimosso dal software, verrà rimosso dall'articolo.
Per creare la risorsa gruppo di disponibilità, usare la sintassi seguente:
sudo pcs resource create <NameForAGResource> ocf:mssql:ag ag_name=<AGName> meta failure-timeout=30s --master meta notify=truedove
NameForAGResourceè il nome univoco assegnato a questa risorsa cluster per il gruppo di disponibilità eAGNameè il nome del gruppo di disponibilità creato.In RHEL 7.7 e Ubuntu 18.04 e versioni successive potrebbe essere visualizzato un avviso relativo all'uso di
--mastero un messaggio di errore simile asqlag_monitor_0 on ag1 'not configured' (6): call=6, status=complete, exitreason='Resource must be configured with notify=true'. Per evitare questa situazione, usare:sudo pcs resource create <NameForAGResource> ocf:mssql:ag ag_name=<AGName> meta failure-timeout=30s master notify=trueCreare la risorsa indirizzo IP del gruppo di disponibilità che verrà associata alla funzionalità del listener.
sudo pcs resource create <NameForIPResource> ocf:heartbeat:IPaddr2 ip=<IPAddress> cidr_netmask=<Netmask>dove
NameForIPResourceè il nome univoco della risorsa IP eIPAddressè l'indirizzo IP statico assegnato alla risorsa.Per fare in modo che la risorsa indirizzo IP e la risorsa gruppo di disponibilità siano in esecuzione nello stesso nodo, è necessario configurare un vincolo di condivisione del percorso.
sudo pcs constraint colocation add <NameForIPResource> <NameForAGResource>-master INFINITY with-rsc-role=MasterDove
NameForIPResourceè il nome della risorsa IP eNameForAGResourceè il nome della risorsa del gruppo di disponibilità.Creare un vincolo di ordinamento per fare in modo che la risorsa del gruppo di disponibilità sia attiva e in esecuzione prima dell'indirizzo IP. Mentre il vincolo di condivisione del percorso implica un vincolo di ordinamento, questo lo applica.
sudo pcs constraint order promote <NameForAGResource>-master then start <NameForIPResource>Dove
NameForIPResourceè il nome della risorsa IP eNameForAGResourceè il nome della risorsa del gruppo di disponibilità.
Passaggio successivo
In questa esercitazione si è appreso come creare e configurare un gruppo di disponibilità per SQL Server in Linux. Contenuto del modulo:
- Abilitare i gruppi di disponibilità.
- Creare endpoint e certificati per i gruppi di disponibilità.
- Usare SQL Server Management Studio (SSMS) o Transact-SQL per creare un gruppo di disponibilità.
- Creare l'account di accesso di SQL server e le autorizzazioni per Pacemaker.
- Creare le risorse del gruppo di disponibilità in un cluster Pacemaker.
Per informazioni sulla maggior parte delle attività di amministrazione dei gruppi di disponibilità, inclusi gli aggiornamenti e il failover, vedere: