Configurare un gruppo di disponibilità Always On di SQL Server in Windows e Linux (multipiattaforma)
Si applica a: ![]() SQL Server 2017 (14.x) e versioni successive
SQL Server 2017 (14.x) e versioni successive
Questo articolo illustra la procedura da seguire per creare un gruppo di disponibilità Always On con una replica in un server Windows e l'altra replica in un server Linux.
Importante
I gruppi di disponibilità multipiattaforma di SQL Server, che includono repliche eterogenee con supporto completo per la disponibilità elevata e ripristino di emergenza, sono disponibili con DH2i DxEnterprise. Per altre informazioni, vedere Gruppi di disponibilità di SQL Server con sistemi operativi misti.
Vedere il video seguente per informazioni sui gruppi di disponibilità multipiattaforma con DH2i.
Questa è una configurazione multipiattaforma perché le repliche si trovano in sistemi operativi diversi. Usare questa configurazione per la migrazione da una piattaforma all'altra o per il ripristino di emergenza. Questa configurazione non supporta la disponibilità elevata.

Prima di procedere, è necessario avere familiarità con l'installazione e la configurazione per le istanze di SQL Server in Windows e Linux.
Scenario
In questo scenario, due server si trovano in sistemi operativi diversi. Un'istanza di Windows Server 2022 denominata WinSQLInstance ospita la replica primaria. e un server Linux denominato LinuxSQLInstance ospita quella secondaria.
Configurare il gruppo di disponibilità
La procedura per creare il gruppo di disponibilità è identica a quella adottata per creare un gruppo di disponibilità per i carichi di lavoro con scalabilità in lettura. Il tipo di cluster del gruppo di disponibilità è NONE perché non è presente alcun gestore di cluster.
Per gli script in questo articolo, le parentesi uncinate < e > identificano i valori che è necessario sostituire per l'ambiente in uso. Non occorre usare le parentesi acute negli script.
Installa SQL Server 2022 (16.x) in Windows Server 2022, abilita Gruppi di disponibilità Always On da Gestione configurazione SQL Server e imposta l'autenticazione in modalità mista.
Suggerimento
Se si convalida questa soluzione in Azure, posizionare entrambi i server nello stesso set di disponibilità per assicurarsi che siano separati nel data center.
Abilitare i gruppi di disponibilità
Per istruzioni dettagliate, vedere Abilitare o disabilitare la funzionalità dei gruppi di disponibilità Always On.
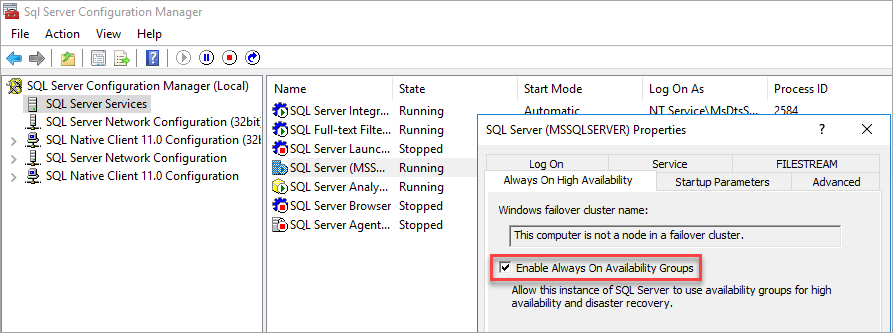
Gestione configurazione SQL Server rileva che il computer non è un nodo in un cluster di failover.
Dopo aver abilitato Gruppi di disponibilità, riavviare SQL Server.
Impostare l'autenticazione in modalità mista
Per istruzioni, vedere Modifica della modalità di autenticazione del server.
Installa SQL Server 2022 (16.x) in Linux. Per istruzioni dettagliate, vedere Linee guida per l'installazione di SQL Server in Linux. Abilita
hadrcon mssql-conf.Per abilitare
hadrtramite mssql-conf da un prompt della shell, esegui il comando seguente:sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1Dopo aver abilitato
hadr, riavvia l'istanza di SQL Server:sudo systemctl restart mssql-server.serviceConfigura il file
hostsin entrambi i server o registra i nomi dei server con DNS.Apri le porte del firewall per TCP 1433 e 5022 in Windows e Linux.
Nella replica primaria creare un account di accesso al database con la relativa password.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GOAttenzione
La password deve seguire i criteri password predefiniti di SQL Server. Per impostazione predefinita, la password deve essere composta da almeno otto caratteri e contenere caratteri di tre delle quattro categorie seguenti: lettere maiuscole, lettere minuscole, cifre in base 10 e simboli. Le password possono contenere fino a 128 caratteri. Usare password il più possibile lunghe e complesse.
Nella replica primaria creare una chiave master e un certificato e quindi eseguire il backup del certificato con una chiave privata.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.cer' WITH PRIVATE KEY ( FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<private-key-password>' ); GOAttenzione
La password deve seguire i criteri password predefiniti di SQL Server. Per impostazione predefinita, la password deve essere composta da almeno otto caratteri e contenere caratteri di tre delle quattro categorie seguenti: lettere maiuscole, lettere minuscole, cifre in base 10 e simboli. Le password possono contenere fino a 128 caratteri. Usare password il più possibile lunghe e complesse.
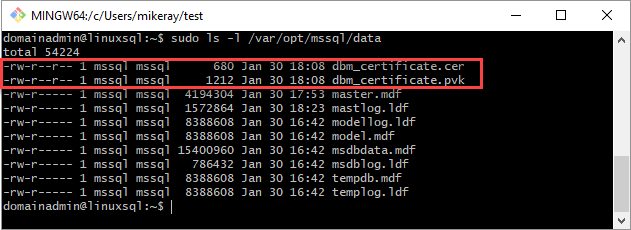
Copiare il certificato e la chiave privata nel server Linux (replica secondaria) in
/var/opt/mssql/data. Per copiare i file nel server Linux è possibile usarepscp.Impostare il gruppo e la proprietà della chiave privata e del certificato su
mssql:mssql.Lo script seguente imposta il gruppo e la proprietà dei file.
sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.pvk sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.cerNel diagramma seguente la proprietà e il gruppo sono impostati correttamente per il certificato e la chiave.
Nella replica secondaria creare un account di accesso al database con la relativa password e creare una chiave master.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GOAttenzione
La password deve seguire i criteri password predefiniti di SQL Server. Per impostazione predefinita, la password deve essere composta da almeno otto caratteri e contenere caratteri di tre delle quattro categorie seguenti: lettere maiuscole, lettere minuscole, cifre in base 10 e simboli. Le password possono contenere fino a 128 caratteri. Usare password il più possibile lunghe e complesse.
Nella replica secondaria ripristinare il certificato copiato in
/var/opt/mssql/data.CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<private-key-password>' ); GONell'esempio precedente sostituire
<private-key-password>con la stessa password usata durante la creazione del certificato nella replica primaria.Nella replica primaria creare un endpoint.
CREATE ENDPOINT [Hadr_endpoint] AS TCP ( LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022 ) FOR DATABASE_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login]; GOImportante
Il firewall deve essere aperto per la porta TCP del listener. Nello script precedente la porta è 5022. Usare qualsiasi porta TCP disponibile.
Nella replica secondaria creare l'endpoint. Ripetere lo script precedente nella replica secondaria per creare l'endpoint.
Nella replica primaria creare il gruppo di disponibilità con
CLUSTER_TYPE = NONE. Lo script di esempio usaSEEDING_MODE = AUTOMATICper creare il gruppo di disponibilità.Nota
Quando l'istanza di SQL Server in Windows usa percorsi diversi per i file di dati e i file di log, viene eseguito il failover automatico del seeding nell'istanza di SQL Server in Linux perché questi percorsi non esistono nella replica secondaria. Per usare lo script seguente per un gruppo di disponibilità multipiattaforma, il database richiede lo stesso percorso per i file di dati e di log in Windows Server. In alternativa, è possibile aggiornare lo script con l'impostazione
SEEDING_MODE = MANUALe quindi eseguire il backup e il ripristino del database conNORECOVERYper il seeding del database.Questo comportamento si applica alle immagini di Azure Marketplace.
Per altre informazioni sul seeding automatico, vedere Seeding automatico - Layout dei dischi.
Prima di eseguire lo script, aggiornare i valori per i gruppi di disponibilità.
Sostituire
<WinSQLInstance>con il nome del server dell'istanza di SQL Server della replica primaria.Sostituire
<LinuxSQLInstance>con il nome del server dell'istanza di SQL Server della replica secondaria.
Per creare il gruppo di disponibilità, aggiornare i valori ed eseguire lo script nella replica primaria.
CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'<WinSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<WinSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'<LinuxSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<LinuxSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL); ) GOPer altre informazioni, vedere CREARE GRUPPO DI DISPONIBILITÀ.
Nella replica secondaria aggiungere il gruppo di disponibilità.
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOCreare un database per il gruppo di disponibilità. Nella procedura di esempio viene usato un database denominato
TestDB. Se si usa il seeding automatico, impostare lo stesso percorso per i file di dati che per i file di log.Prima di eseguire lo script, aggiornare i valori per il database.
Sostituire
TestDBcon il nome del database.Sostituire
<F:\Path>con il percorso dei file di database e di log. Usare lo stesso percorso per i file di database e di log.
È anche possibile usare i percorsi predefiniti.
Per creare il database, eseguire lo script.
CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY(NAME = N'TestDB', FILENAME = N'<F:\Path>\TestDB.mdf') LOG ON (NAME = N'TestDB_log', FILENAME = N'<F:\Path>\TestDB_log.ldf'); GOEseguire un backup completo del database.
Se non usi il seeding automatico, ripristina il database nel server della replica secondaria (Linux). Eseguire la migrazione di un database di SQL Server da Windows a Linux tramite backup e ripristino. Ripristinare il database
WITH NORECOVERYnella replica secondaria.Aggiungere il database al gruppo di disponibilità. Aggiornare lo script di esempio. Sostituire
TestDBcon il nome del database. Nella replica primaria esegui la query T-SQL per aggiungere il database al gruppo di disponibilità.ALTER AG [ag1] ADD DATABASE TestDB; GOVerificare che il database venga popolato nella replica secondaria.

Eseguire il failover della replica primaria
Ogni gruppo di disponibilità include solo una replica primaria, che consente operazioni di lettura e scrittura. Per modificare la replica primaria, è possibile effettuare il failover. In un gruppo di disponibilità tipico il processo di failover è automatizzato da Gestione cluster. In un gruppo di disponibilità con tipo di cluster NONE, il processo di failover è manuale.
Esistono due modi per effettuare il failover della replica primaria in un gruppo di disponibilità con tipo di cluster NONE:
- Failover manuale senza perdita di dati
- Failover manuale forzato con perdita di dati
Failover manuale senza perdita di dati
Usare questo metodo quando la replica primaria è disponibile, ma è necessario modificare temporaneamente o definitivamente l'istanza che ospita la replica primaria. Per evitare una potenziale perdita di dati, prima di effettuare il failover manuale, verificare che la replica secondaria di destinazione sia aggiornata.
Per effettuare il failover manuale senza perdita di dati:
Impostare la replica primaria corrente e la replica secondaria di destinazione come
SYNCHRONOUS_COMMIT.ALTER AVAILABILITY GROUP [AGRScale] MODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Per verificare che per le transazioni attive venga eseguito il commit della replica primaria e di almeno una replica secondaria sincrona, eseguire la query seguente:
SELECT ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag WHERE drs.group_id = ag.group_id;La replica secondaria è sincronizzata quando
synchronization_state_descèSYNCHRONIZED.Aggiornare
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITsu 1.Lo script seguente imposta
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITsu 1 in un gruppo di disponibilità denominatoag1. Prima di eseguire lo script seguente, sostituireag1con il nome del gruppo di disponibilità:ALTER AVAILABILITY GROUP [AGRScale] SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Questa impostazione assicura che per ogni transazione attiva venga eseguito il commit della replica primaria e di almeno una replica secondaria sincrona.
Nota
Questa impostazione non è specifica del failover e deve essere impostata in base ai requisiti dell'ambiente.
Imposta la replica primaria e le repliche secondarie che non partecipano al failover offline per prepararti alla modifica del ruolo:
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEAlzare il livello della replica secondaria di destinazione a replica primaria.
ALTER AVAILABILITY GROUP AGRScale FORCE_FAILOVER_ALLOW_DATA_LOSS;Aggiorna il ruolo della replica primaria precedente e di altre secondarie in
SECONDARY, quindi esegui il comando seguente nell'istanza di SQL Server che ospita la replica primaria precedente:ALTER AVAILABILITY GROUP [AGRScale] SET (ROLE = SECONDARY);Nota
Per eliminare un gruppo di disponibilità, usare DROP AVAILABILITY GROUP. Per un gruppo di disponibilità creato con il tipo di cluster NONE o EXTERNAL, eseguire il comando su tutte le repliche che fanno parte del gruppo di disponibilità.
Riprendere lo spostamento dati, eseguire il comando seguente per ogni database nel gruppo di disponibilità nell'istanza di SQL Server che ospita la replica primaria:
ALTER DATABASE [db1] SET HADR RESUMERicreare ogni listener creato a scopo di scalabilità in lettura e che non rientra nella gestione cluster. Se il listener originale punta alla replica primaria precedente, rimuoverlo e ricrearlo in modo che punti a quella nuova.
Failover manuale forzato con perdita di dati
Se la replica primaria non è disponibile e non può essere ripristinata immediatamente, è necessario forzare un failover nella replica secondaria con perdita di dati. Tuttavia, se la replica primaria originale viene ripristinata dopo il failover, assumerà il ruolo primario. Per evitare che ogni replica si trovi in uno stato diverso, rimuovere la replica primaria originale dal gruppo di disponibilità dopo un failover forzato con perdita di dati. Quando la replica primaria originale torna online, rimuovere completamente il gruppo di disponibilità.
Per forzare un failover manuale con perdita di dati dalla replica primaria N1 alla replica secondaria N2, seguire questa procedura:
Nella replica secondaria (N2) avviare il failover forzato:
ALTER AVAILABILITY GROUP [AGRScale] FORCE_FAILOVER_ALLOW_DATA_LOSS;Nella nuova replica primaria (N2) rimuovere la replica primaria originale (N1):
ALTER AVAILABILITY GROUP [AGRScale] REMOVE REPLICA ON N'N1';Verificare che tutto il traffico dell'applicazione punti al listener e/o alla nuova replica primaria.
Se la replica primaria originale (N1) torna online, portare immediatamente offline AGRScale del gruppo di disponibilità nella replica primaria originale (N1):
ALTER AVAILABILITY GROUP [AGRScale] OFFLINESe sono presenti dati o modifiche non sincronizzate, conservare questi dati tramite backup o altre opzioni di replica dei dati adatte alle esigenze aziendali.
Rimuovere quindi il gruppo di disponibilità dalla replica primaria originale (N1):
DROP AVAILABILITY GROUP [AGRScale];Eliminare il database del gruppo di disponibilità nella replica primaria originale (N1):
USE [master] GO DROP DATABASE [AGDBRScale] GO(Facoltativo) Se lo si desidera, è ora possibile aggiungere di nuovo N1 come nuova replica secondaria ad AGRScale del gruppo di disponibilità.
In questo articolo è stata illustrata la procedura per creare un gruppo di disponibilità multipiattaforma per supportare i carichi di lavoro di migrazione o di scalabilità in lettura. La procedura può essere usata per il ripristino di emergenza manuale. È stato inoltre illustrato come eseguire il failover del gruppo di disponibilità. Un gruppo di disponibilità multipiattaforma usa il tipo di cluster NONE e non supporta la disponibilità elevata.