Risolvere i problemi di un notebook pyspark
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
Questo articolo illustra come risolvere i problemi di un notebook pyspark che presenta errori.
Architettura di un processo PySpark in Azure Data Studio
Azure Data Studio comunica con l'endpoint livy nei cluster Big Data di SQL Server.
L'endpoint livy esegue comandi spark-submit all'interno del cluster Big Data. Ogni comando spark-submit ha un parametro che specifica YARN come gestione risorse cluster.
Per risolvere in modo efficiente i problemi della sessione PySpark, sarà necessario raccogliere ed esaminare i log all'interno di ogni livello: Livy, YARN e Spark.
Questa procedura per la risoluzione dei problemi richiede:
- Interfaccia della riga di comando di Azure Data (
azdata) installata e con la configurazione correttamente impostata sul cluster. - Familiarità con l'esecuzione di comandi Linux e alcune competenze per la risoluzione dei problemi relativi ai log.
Passaggi per la risoluzione dei problemi
Esaminare lo stack e i messaggi di errore in
pyspark.Ottenere l'ID applicazione nella prima cella del notebook. Usare questo ID applicazione per esaminare i log di
livy, YARN e Spark.SparkContextusa questo ID applicazione YARN.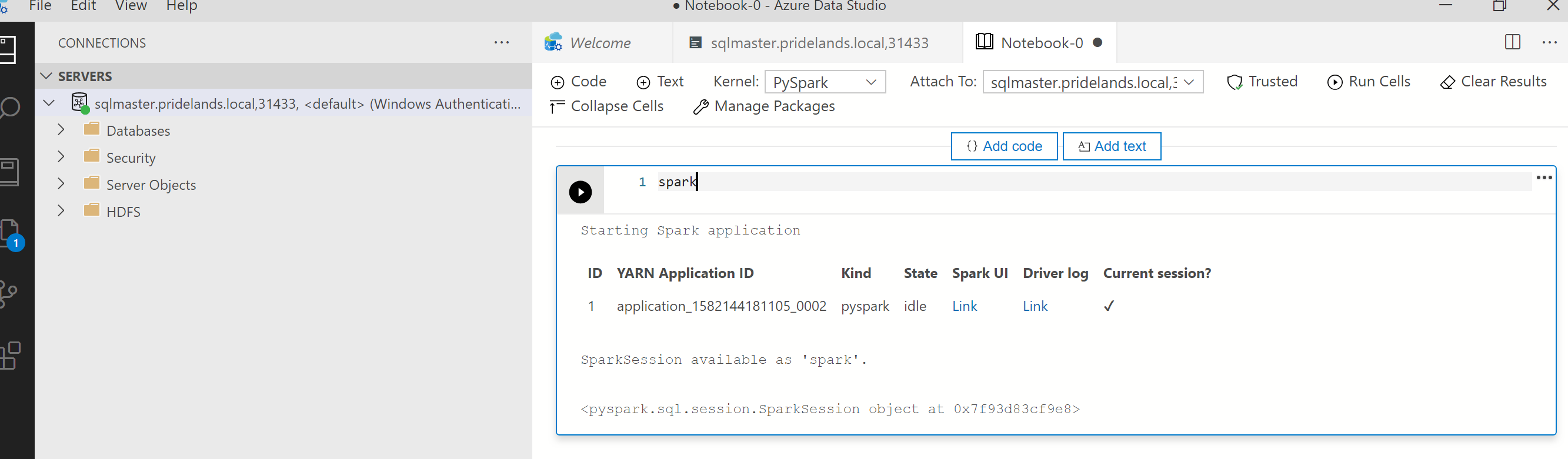
Ottenere i log.
Usare
azdata bdc debug copy-logsper eseguire l'analisi.Nell'esempio seguente viene connesso un endpoint del cluster Big Data per copiare i log. Aggiornare i valori seguenti nell'esempio prima di procedere all'esecuzione.
<ip_address>: endpoint del cluster Big Data<username>: nome utente del cluster Big Data<namespace>: spazio dei nomi Kubernetes per il cluster<folder_to_copy_logs>: percorso della cartella locale in cui copiare i log
azdata login --auth basic --username <username> --endpoint https://<ip_address>:30080 azdata bdc debug copy-logs -n <namespace> -d <folder_to_copy_logs>Output di esempio
<user>@<server>:~$ azdata bdc debug copy-logs -n <namespace> -d copy_logs Collecting the logs for cluster '<namespace>'. Collecting logs for containers... Creating an archive from logs-tmp/<namespace>. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS-dumps.tar.gz. Collecting the logs for cluster 'kube-system'. Collecting logs for containers... Creating an archive from logs-tmp/kube-system. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS-dumps.tar.gz.Esaminare i log di Livy. I log di Livy si trovano in
<namespace>\sparkhead-0\hadoop-livy-sparkhistory\supervisor\log.- Cercare l'ID applicazione YARN nella prima cella del notebook PySpark.
- Cercare lo stato
ERR.
Esempio di log di Livy con stato
YARN ACCEPTED. Livy ha inviato l'applicazione Yarn.HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO impl.YarnClientImpl: Submitted application application_<application_id> YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: Application report for application_<application_id> (state: ACCEPTED) YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: client token: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: diagnostics: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster host: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster RPC port: -1 YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: queue: default YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: start time: ############ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: final status: UNDEFINED YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: tracking URL: https://sparkhead-1.fnbm.corp:8090/proxy/application_<application_id>/ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: user: <account>Esaminare l'interfaccia utente di YARN
Ottenere l'URL dell'endpoint YARN dal dashboard di gestione del cluster Big Data di Azure Data Studio o eseguire
azdata bdc endpoint list –o table.Ad esempio:
azdata bdc endpoint list -o tableValori restituiti
Description Endpoint Name Protocol ------------------------------------------------------ ---------------------------------------------------------------- -------------------------- ---------- Gateway to access HDFS files, Spark https://knox.<namespace-value>.local:30443 gateway https Spark Jobs Management and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/sparkhistory spark-history https Spark Diagnostics and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/yarn yarn-ui https Application Proxy https://proxy.<namespace-value>.local:30778 app-proxy https Management Proxy https://bdcmon.<namespace-value>.local:30777 mgmtproxy https Log Search Dashboard https://bdcmon.<namespace-value>.local:30777/kibana logsui https Metrics Dashboard https://bdcmon.<namespace-value>.local:30777/grafana metricsui https Cluster Management Service https://bdcctl.<namespace-value>.local:30080 controller https SQL Server Master Instance Front-End sqlmaster.<namespace-value>.local,31433 sql-server-master tds SQL Server Master Readable Secondary Replicas sqlsecondary.<namespace-value>.local,31436 sql-server-master-readonly tds HDFS File System Proxy https://knox.<namespace-value>.local:30443/gateway/default/webhdfs/v1 webhdfs https Proxy for running Spark statements, jobs, applications https://knox.<namespace-value>.local:30443/gateway/default/livy/v1 livy httpsControllare l'ID applicazione e i singoli log del contenitore e application_master.
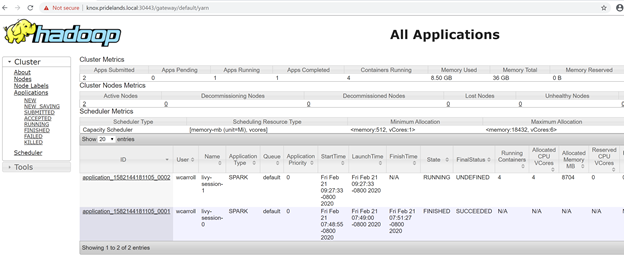
Esaminare i log applicazioni YARN.
Ottenere il log applicazioni per l'app. Usare
kubectlper connettersi al podsparkhead-0, ad esempio:kubectl exec -it sparkhead-0 -- /bin/bashEseguire quindi questo comando all'interno della shell usando l'
application_idcorretto:yarn logs -applicationId application_<application_id>Cercare errori o stack.
Ad esempio, un errore di autorizzazione rispetto a HDFS. Nello stack Java cercare
Caused by:YYYY-MM-DD HH:MM:SS,MMM ERROR spark.SparkContext: Error initializing SparkContext. org.apache.hadoop.security.AccessControlException: Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:399) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:255) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:193) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1852) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1836) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1795) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.resolvePathForStartFile(FSDirWriteFileOp.java:324) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2504) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileChecked(FSNamesystem.java:2448) Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-xEsaminare l'interfaccia utente di Spark.
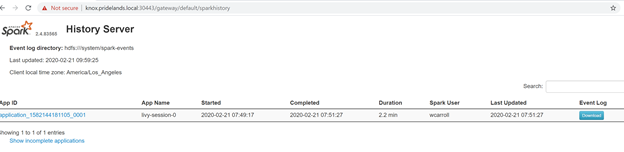
Eseguire il drill-down nelle attività delle fasi alla ricerca di errori.
Passaggi successivi
Risolvere i problemi di integrazione di Active Directory di cluster Big Data di SQL Server