Eseguire il debug e la diagnosi di applicazioni Spark in cluster Big Data di SQL Server nel server cronologia Spark
Si applica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
Questo articolo fornisce indicazioni su come usare il server cronologia Spark esteso per eseguire il debug e la diagnosi delle applicazioni Spark in un cluster Big Data di SQL Server. Le funzionalità di debug e diagnosi sono integrate nel server cronologia Spark e basate su tecnologia Microsoft. L'estensione include scheda dati e scheda grafico e scheda diagnosi. Nella scheda dati gli utenti possono controllare i dati di input e output del processo Spark. Nella scheda relativa ai grafici gli utenti possono esaminare il flusso di dati e riprodurre il grafico del processo. Nella scheda relativa alla diagnosi l'utente può vedere le analisi relative ad asimmetria dei dati, sfasamento dell'ora e utilizzo dell'executor.
Ottenere l'accesso al server cronologia Spark
L'esperienza utente del server cronologia Spark open source è stata migliorata con alcune informazioni, tra cui dati specifici dei processi e visualizzazione interattiva del grafico del processo e dei flussi di dati per i cluster Big Data.
Aprire l'interfaccia utente Web del server cronologia Spark tramite l'URL
Aprire il server cronologia Spark passando all'URL seguente, sostituendo <Ipaddress> e <Port> con informazioni specifiche del cluster Big Data. Nei cluster distribuiti nella versione precedente a SQL Server 2019 CU 5, tramite un'installazione di cluster Big Data con autenticazione di base (nome utente/password), è necessario specificare la radice dell'utente quando viene chiesto di accedere agli endpoint del gateway (Knox). Vedere Distribuire un cluster Big Data di SQL Server. A partire da SQL Server 2019 (15.x) CU 5, quando si distribuisce un nuovo cluster con l'autenticazione di base, tutti gli endpoint, incluso il gateway, usano AZDATA_USERNAME e AZDATA_PASSWORD. Gli endpoint nei cluster aggiornati a CU5 continuano a usare root come nome utente per la connessione all'endpoint del gateway. Questa modifica non si applica alle distribuzioni che usano l'autenticazione Active Directory. Vedere Credenziali per l'accesso ai servizi tramite l'endpoint del gateway nelle note sulla versione.
https://<Ipaddress>:<Port>/gateway/default/sparkhistory
L'interfaccia utente Web del server cronologia Spark ha un aspetto simile al seguente:
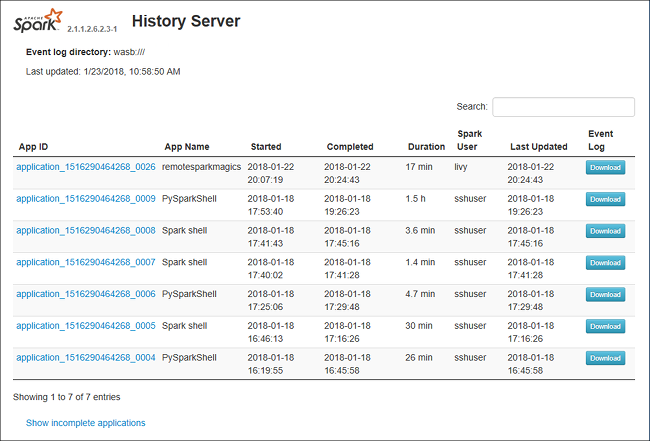
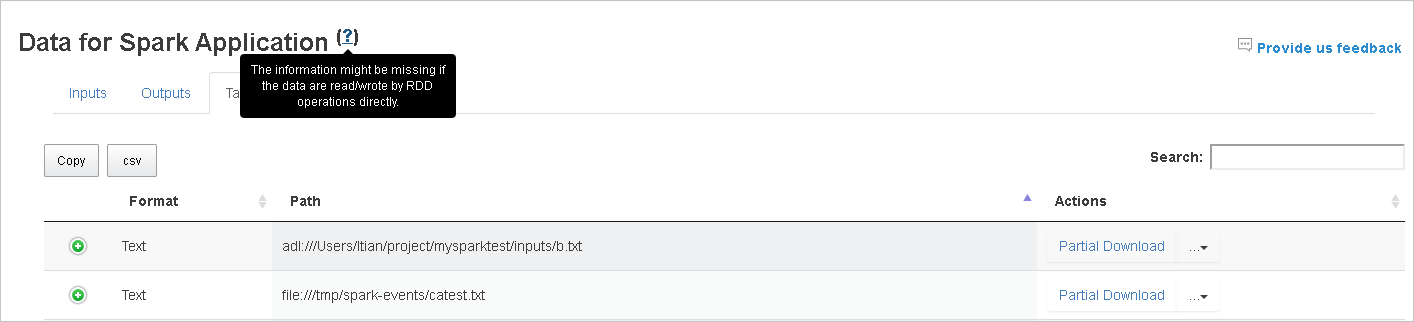
Scheda relativa ai dati del server cronologia Spark
Selezionare l'ID processo e quindi fare clic su Dati nel menu degli strumenti per passare alla visualizzazione dati.
Esaminare Input, Output e Table Operations (Operazioni tabella) selezionando le schede separatamente.
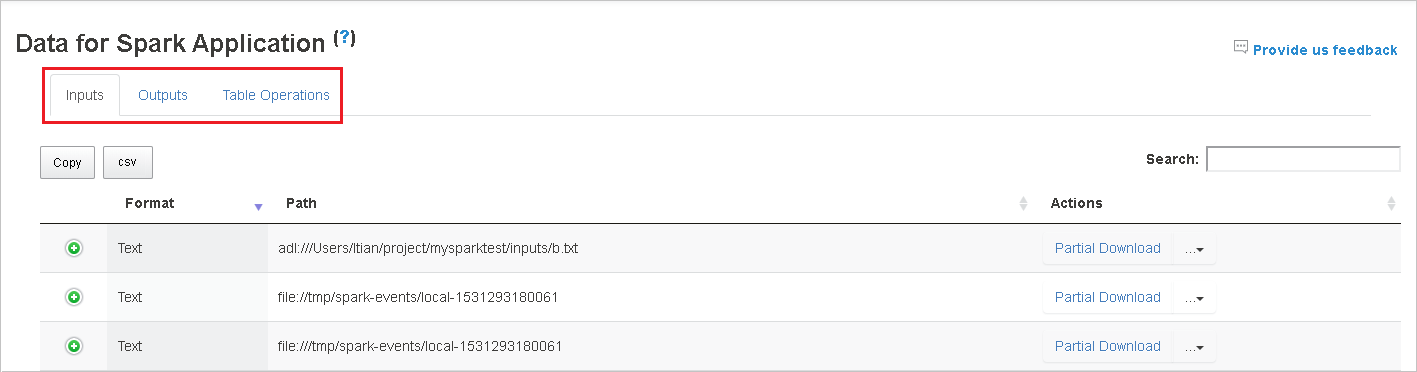
Copiare tutte le righe facendo clic sul pulsante Copia.
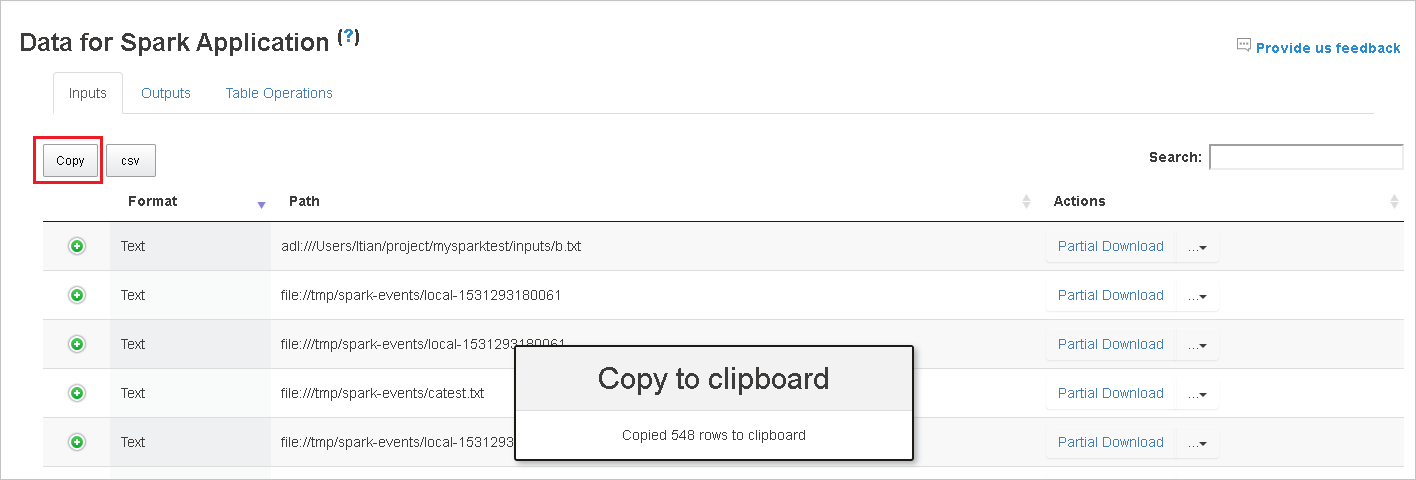
Salvare tutti i dati in un file CSV facendo clic sul pulsante csv.
Eseguire una ricerca immettendo le parole chiave nel campo Cerca e il risultato della ricerca verrà visualizzato immediatamente.
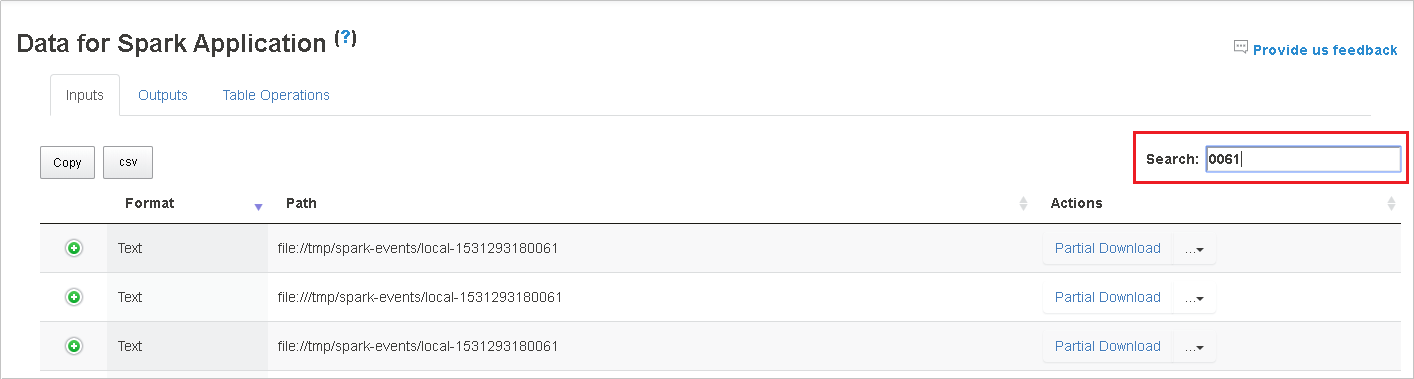
Fare clic sull'intestazione di colonna per ordinare la tabella, fare clic sul segno più per espandere una riga e visualizzare altri dettagli oppure fare clic sul segno meno per comprimere una riga.
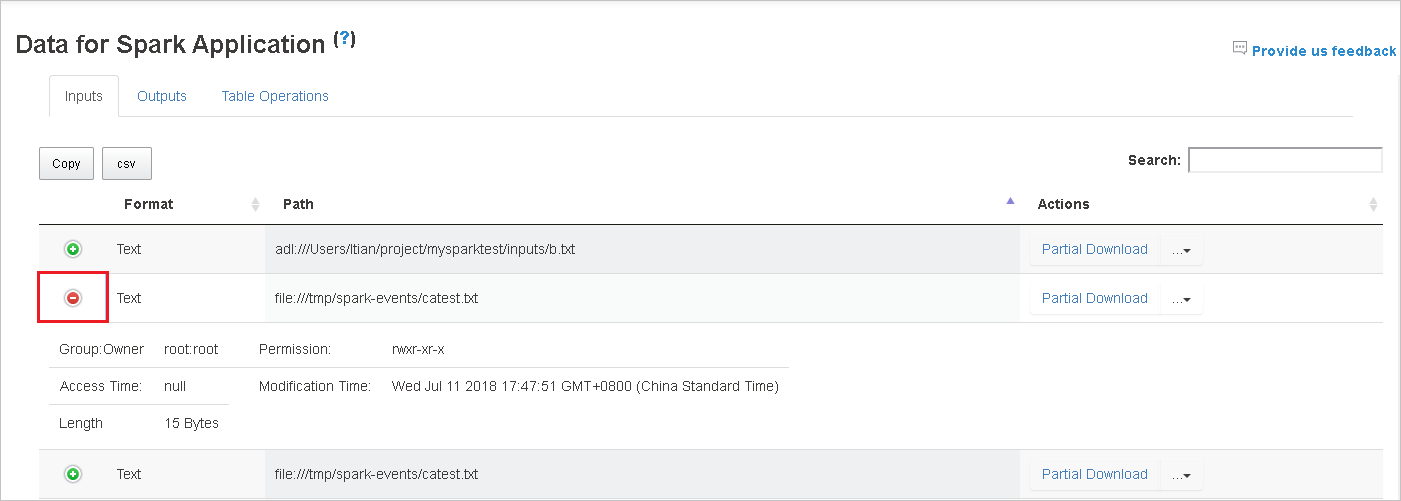
Scaricare un singolo file facendo clic sul pulsante Download parziale a destra e il file selezionato verrà scaricato in un percorso locale. Se il file non esiste più, verrà aperta una nuova scheda per visualizzare i messaggi di errore.
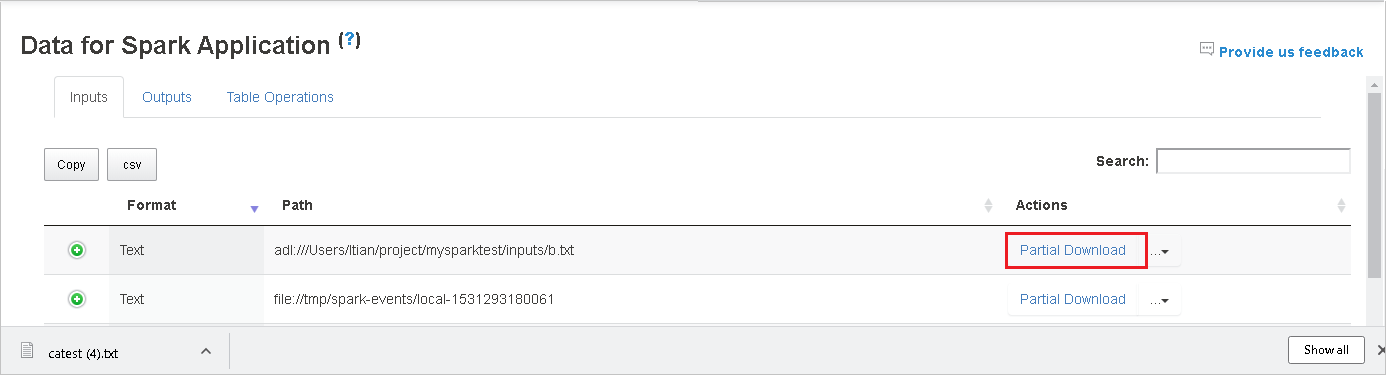
Copiare il percorso completo o relativo selezionando i comandi Copia percorso completo, Copia percorso relativo per espandere il menu di download. Per i file di Azure Data Lake Storage, il comando Open in Azure Storage Explorer (Apri in Azure Storage Explorer) avvia Azure Storage Explorer. Individuare la cartella esatta al momento dell'accesso.
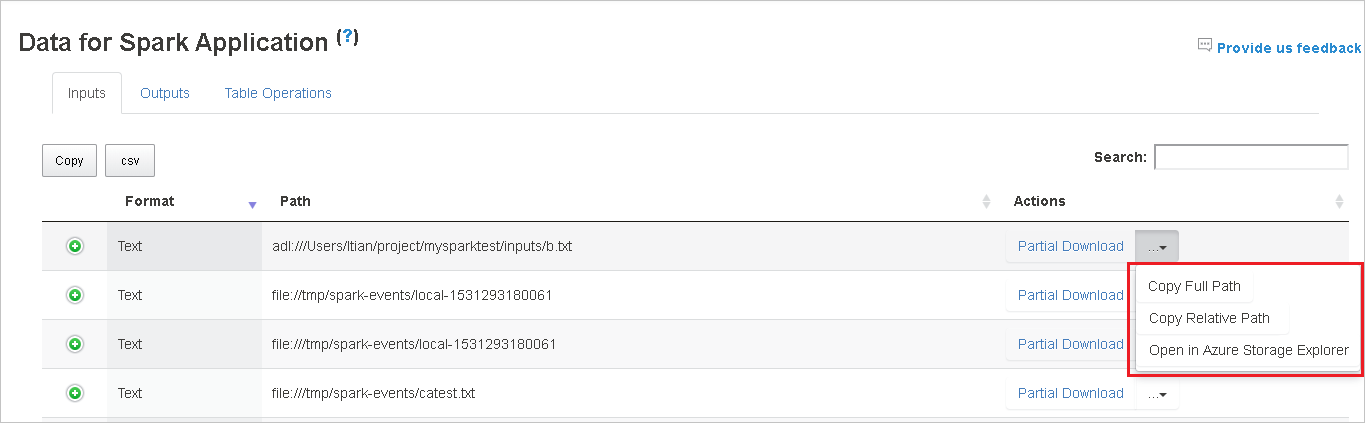
Fare clic sul numero sotto la tabella per spostarsi tra le pagine quando sono presenti troppe righe da visualizzare in una pagina.

Passare il puntatore sul punto interrogativo accanto all'intestazione dei dati per visualizzare la descrizione comando oppure fare clic sul punto interrogativo per ottenere altre informazioni.
Per inviare feedback e commenti relativi ai problemi, fare clic su Provide us feedback (Invia feedback).
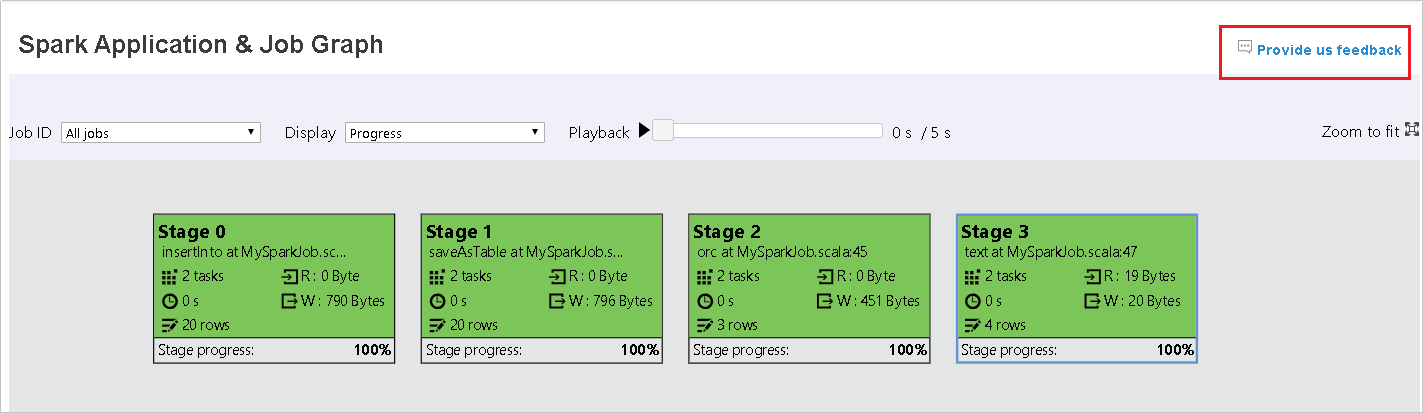
Scheda relativa ai grafici del server cronologia Spark
Selezionare l'ID processo e quindi fare clic su Grafico nel menu degli strumenti per passare alla visualizzazione grafici.
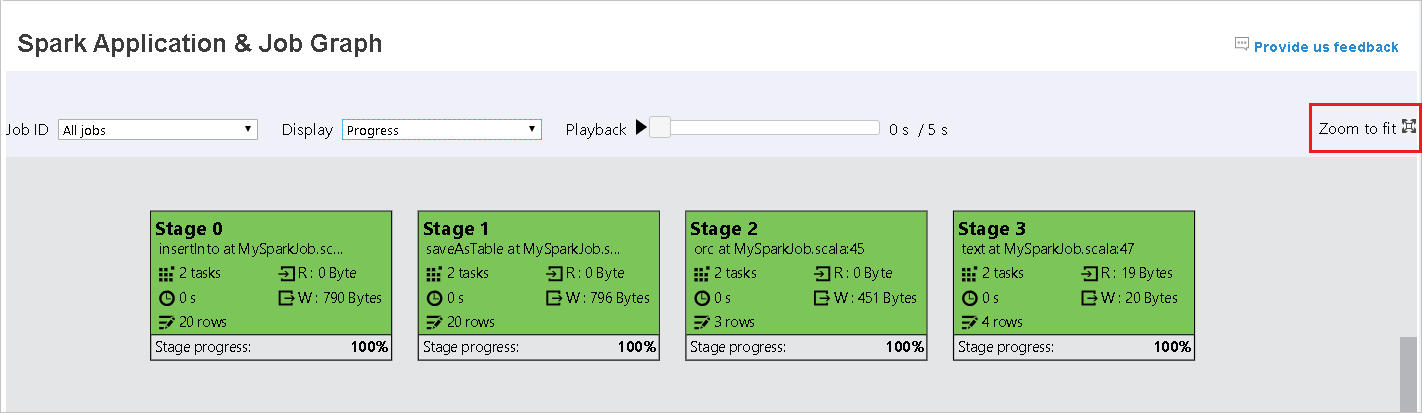
Esaminare la panoramica del processo nel grafico del processo generato.
Per impostazione predefinita, verranno visualizzati tutti i processi, che è possibile filtrare in base a ID processo.
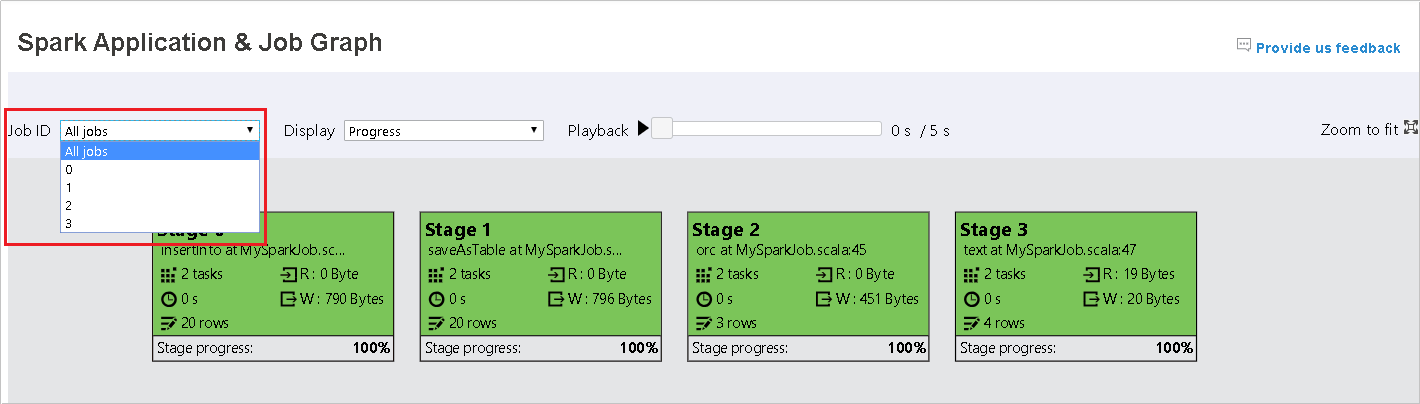
In questo caso viene lasciata l'opzione Stato come valore predefinito. L'utente può esaminare il flusso di dati selezionando Lettura o Dati scritti nell'elenco a discesa Visualizza.
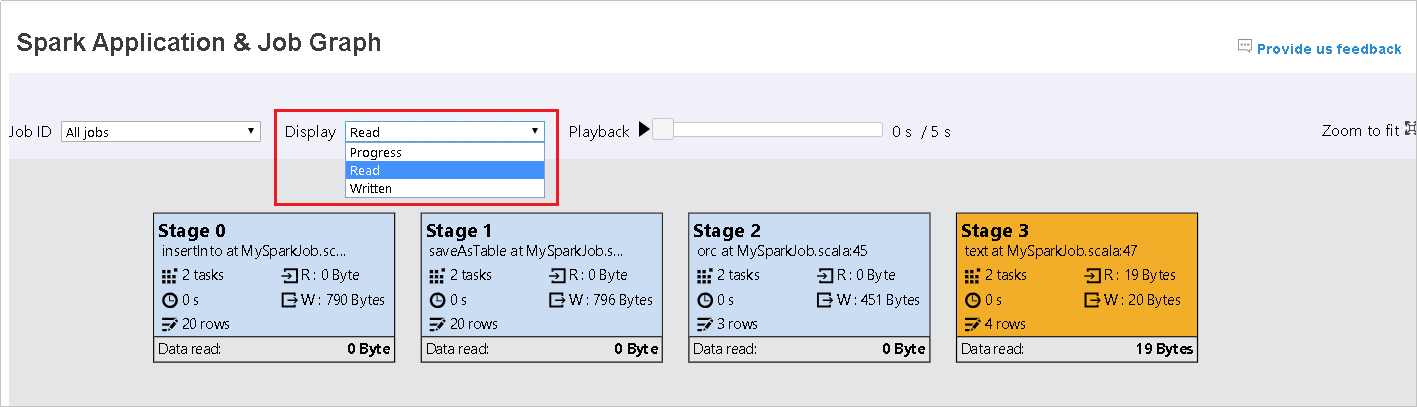
Il nodo relativo ai grafici viene visualizzato con un colore che indica la mappa termica.

Per riprodurre il processo, fare clic sul pulsante Riproduzione e per arrestarlo in qualsiasi momento fare clic sul pulsante Arresta. L'attività viene visualizzata con un colore che indica il diverso stato durante la riproduzione:
- Il verde indica l'esito positivo: il processo è stato completato correttamente.
- L'arancione indica i tentativi ripetuti: istanze di attività non riuscite, ma che non influiscono sul risultato finale del processo. Per queste attività sono presenti istanze duplicate o nuovi tentativi che potrebbero riuscire in un secondo momento.
- Il blu indica lo stato di esecuzione: l'attività è in esecuzione.
- Il bianco indica un processo in attesa o ignorato: l'attività è in attesa di esecuzione o la fase è stata ignorata.
- Il rosso indica l'esito negativo: l'attività non è stata completata.

La fase ignorata viene visualizzata in bianco.


Nota
È consentita la riproduzione per ogni processo. Per un processo incompleto, la riproduzione non è supportata.
Scorrere con il mouse per fare zoom avanti o indietro oppure fare clic su Adatta alla finestra per adattare la visualizzazione allo schermo.
Passare il puntatore sul nodo del grafico per visualizzare la descrizione comando quando sono presenti attività non riuscite e fare clic su una fase per aprire la pagina relativa.
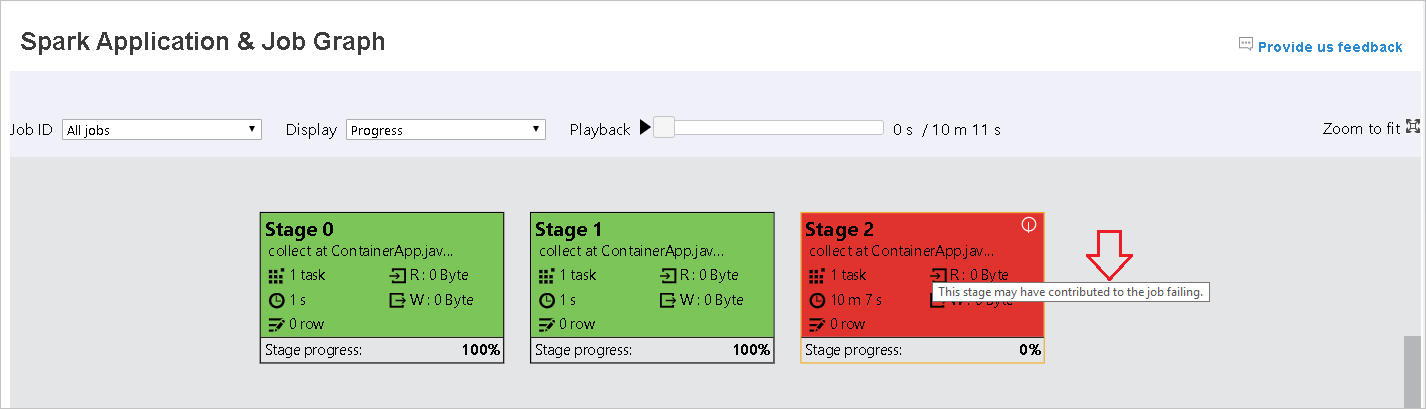
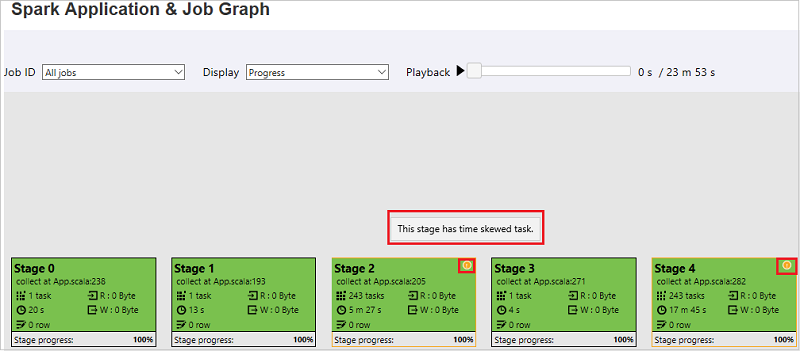
Nella scheda relativa al grafico del processo, per le fasi sono visualizzate una descrizione comando e una piccola icona se sono presenti attività che soddisfano le condizioni seguenti:
- Asimmetria dei dati: dimensioni di lettura dei dati > dimensioni medie di lettura dei dati di tutte le attività all'interno della fase * 2 e dimensioni di lettura dei dati > 10 MB
- Sfasamento dell'ora: tempo di esecuzione > tempo di esecuzione medio di tutte le attività all'interno della fase * 2 e tempo di esecuzione > 2 min
Il nodo del grafico del processo visualizza le informazioni seguenti per ogni fase:
- ID.
- Nome o descrizione.
- Numero totale di attività.
- Dati letti: somma delle dimensioni di input e delle dimensioni di lettura casuale.
- Dati scritti: somma delle dimensioni di output e delle dimensioni di scrittura casuale.
- Tempo di esecuzione: tempo tra l'ora di inizio del primo tentativo e l'ora di completamento dell'ultimo tentativo.
- Conteggio righe: somma di record di input, record di output, record di lettura casuale e record di scrittura casuale.
- Stato.
Nota
Per impostazione predefinita, il nodo del grafico del processo visualizzerà le informazioni dell'ultimo tentativo di ogni fase, ad eccezione del tempo di esecuzione della fase, ma durante la riproduzione il nodo del grafico mostrerà le informazioni di ogni tentativo.
Nota
Per le dimensioni dei dati letti e scritti si usa 1 MB = 1000 KB = 1000 * 1000 byte.
Per inviare feedback e commenti relativi ai problemi, fare clic su Provide us feedback (Invia feedback).
Scheda relativa alla diagnosi del server cronologia Spark
Selezionare l'ID processo e quindi fare clic su Diagnosi nel menu degli strumenti per passare alla visualizzazione diagnosi. La scheda relativa alla diagnosi include Asimmetria dei dati, Sfasamento dell'ora e Analisi dell'utilizzo dell'executor.
Esaminare i valori di Asimmetria dei dati, Sfasamento dell'ora e Analisi dell'utilizzo dell'executor selezionando le rispettive schede.
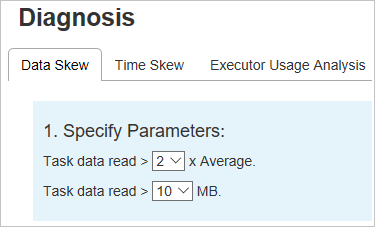
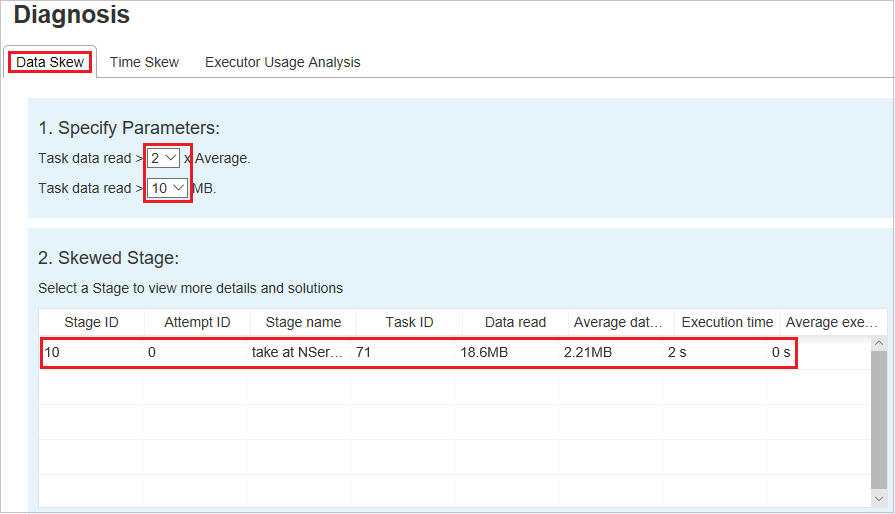
Asimmetria dei dati
Fare clic sulla scheda Asimmetria dei dati per visualizzare le attività asimmetriche corrispondenti in base ai parametri specificati.
Specificare i parametri: la prima sezione visualizza i parametri usati per rilevare Asimmetria dei dati. La regola predefinita è: la quantità di dati attività letti è superiore al triplo della quantità media di dati attività letti e la quantità di dati attività letti è superiore a 10 MB. Se si vuole definire una regola personalizzata per le attività asimmetriche, è possibile scegliere i parametri e le sezioni Fase asimmetrica e Skew Chart (Grafico asimmetrie) verranno aggiornate di conseguenza.
Fase asimmetrica - La seconda sezione visualizza le fasi che hanno attività asimmetriche che soddisfano i criteri specificati in precedenza. Se in una fase è presente più di un'attività asimmetrica, nella tabella delle fasi asimmetriche viene visualizzata solo l'attività con più asimmetria, ad esempio i dati di dimensioni maggiori per l'asimmetria dei dati.
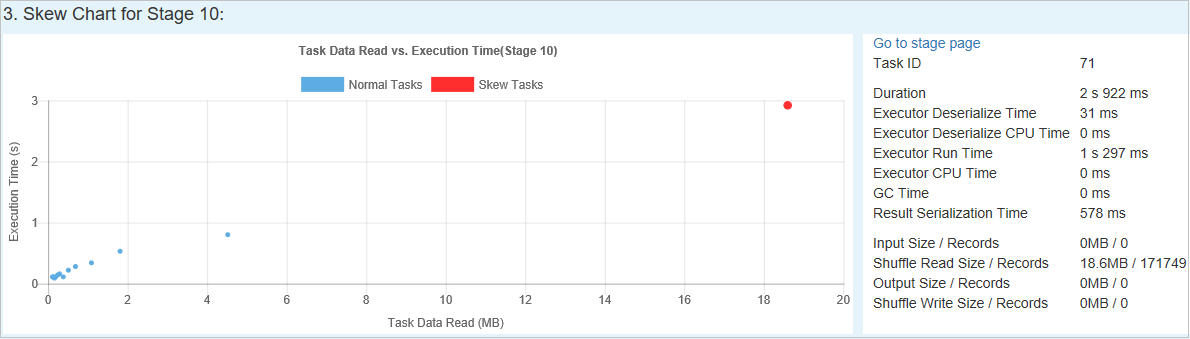
Skew Chart (Grafico asimmetrie) - Quando viene selezionata una riga nella tabella delle fasi asimmetriche, il grafico delle asimmetrie visualizza più dettagli delle distribuzioni delle attività in base ai dati letti e al tempo di esecuzione. Le attività asimmetriche sono contrassegnate in rosso e le attività normali sono contrassegnate in blu. Per consentire la valutazione delle prestazioni, il grafico visualizza solo fino a 100 attività di esempio. I dettagli delle attività sono visualizzati nel pannello inferiore destro.
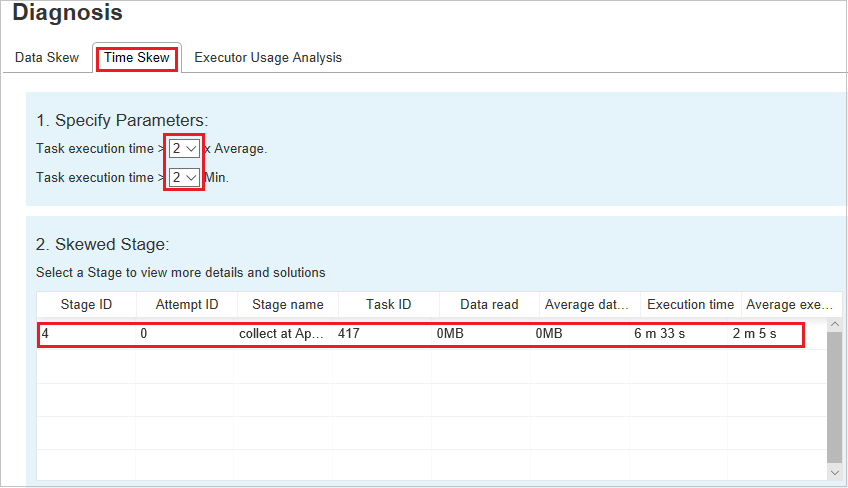
Sfasamento dell'ora
La scheda Sfasamento dell'ora visualizza le attività asimmetriche in base al tempo di esecuzione.
Specificare i parametri - La prima sezione visualizza i parametri, che vengono usati per rilevare lo sfasamento dell'ora. I criteri predefiniti per il rilevamento dello sfasamento dell'ora sono: il tempo di esecuzione dell'attività è maggiore di tre volte rispetto al tempo medio di esecuzione e il tempo di esecuzione dell'attività è maggiore di 30 secondi. È possibile modificare i parametri in base alle esigenze. Le sezioni Fase asimmetrica e Skew Chart (Grafico asimmetrie) visualizzano le informazioni sulle fasi e sulle attività corrispondenti come nella scheda Asimmetria dei dati precedente.
Fare clic su Sfasamento dell'ora e i risultati filtrati verranno visualizzati nella sezione Fase asimmetrica in base ai parametri impostati nella sezione Specificare i parametri. Fare clic su un elemento nella sezione Fase asimmetrica per tracciare il grafico corrispondente nella sezione 3 e visualizzare i dettagli delle attività nel pannello inferiore destro.
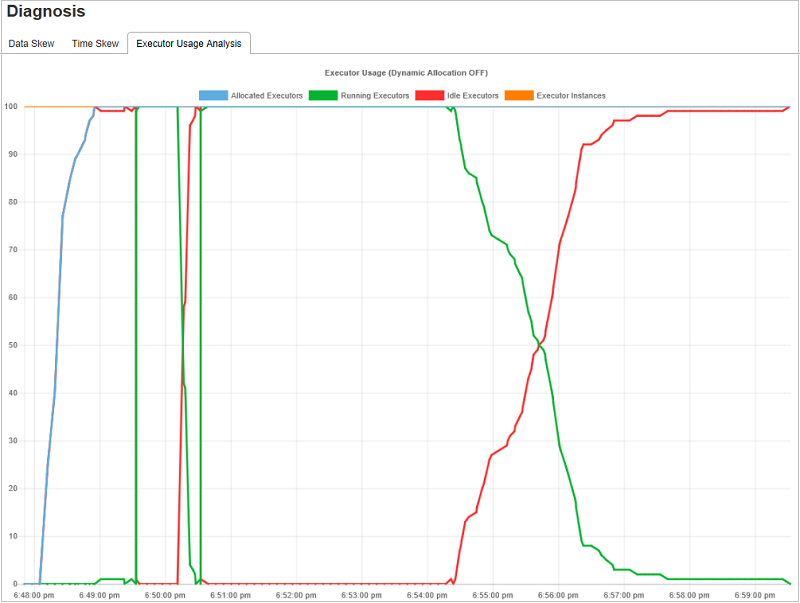
Analisi dell'utilizzo dell'executor
Il grafico relativo all'utilizzo dell'executor visualizza l'allocazione effettiva dell'executor del processo Spark e lo stato di esecuzione.
Fare clic su Executor Usage Analysis (Analisi utilizzo executor) per tracciare quattro tipi di curve relative all'utilizzo dell'executor. Le curve indicano Allocated Executors (Executor allocati), Running Executors (Executor in esecuzione), Idle Executors (Executor inattivi) e Max Executor Instances (Istanze massime executor). Per quanto riguarda gli excutor allocati, ogni evento di aggiunta o rimozione di un executor comporta un aumento o una diminuzione del numero di executor allocati. È possibile esaminare la sequenza temporale degli eventi nella scheda relativa ai processi per ulteriori confronti.
Fare clic sull'icona del colore per selezionare o deselezionare il contenuto corrispondente in tutte le bozze.
Log di Spark/Yarn
Oltre al server della cronologia di Spark, è possibile trovare i log per Spark e Yarn rispettivamente agli indirizzi seguenti:
- Log eventi di Spark: hdfs:///system/spark-events
- Log di Yarn: hdfs:///tmp/logs/root/logs-tfile
per entrambi questi log è previsto un periodo di conservazione predefinito di 7 giorni. Se si vuole modificare il periodo di conservazione, vedere la pagina Configurare Apache Spark e Apache Hadoop. Il percorso non può essere modificato.
Problemi noti
Il server cronologia Spark presenta i problemi noti seguenti:
Funziona attualmente solo per il cluster Spark 3.1 (CU13+) e Spark 2.4 (CU12-).
I dati di input/output con RDD non vengono visualizzati nella scheda dei dati.
Passaggi successivi
- Introduzione ai cluster Big Data di SQL Server
- Configurare le impostazioni di Spark
- Configurare le impostazioni di Spark