Introduzione al pool di archiviazione nei cluster Big Data di SQL Server
Si applica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Questo articolo descrive il ruolo del pool di archiviazione di SQL Server in un cluster Big Data di SQL Server. Le sezioni seguenti descrivono l'architettura e le funzionalità di un pool di archiviazione.
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
Architettura dei pool di archiviazione
Il pool di archiviazione è il cluster HDFS (Hadoop) locale in un cluster Big Data di SQL Server. Fornisce l'archiviazione permanente per i dati non strutturati e semistrutturati. I file di dati, ad esempio Parquet o testo delimitato, possono essere archiviati nel pool di archiviazione. Per ottenere l'archiviazione permanente, a ogni pod nel pool è associato un volume permanente. I file del pool di archiviazione sono accessibili con PolyBase tramite SQL Server o direttamente usando Apache Knox Gateway.
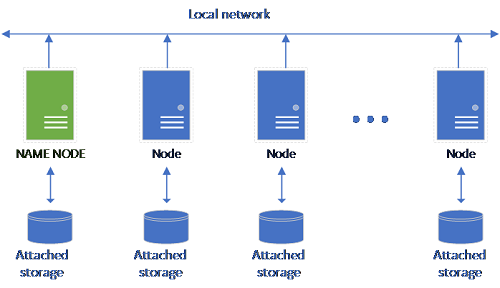
Una configurazione di HDFS classica è costituita da un set di computer con hardware commerciale e archiviazione collegata. I dati vengono distribuiti in blocchi tra i nodi per la tolleranza di errore e per sfruttare l'elaborazione parallela. Uno dei nodi del cluster funge da nodo dei nomi e contiene le informazioni dei metadati relative ai file presenti nei nodi dei dati.
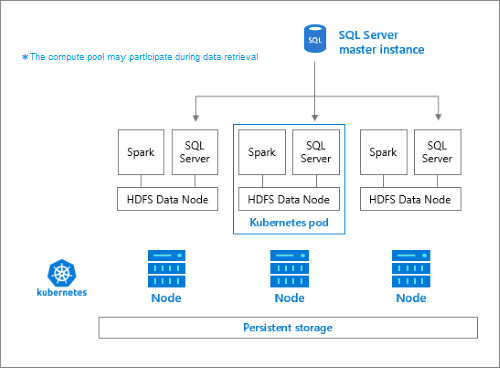
Il pool di archiviazione è costituito da nodi di archiviazione membri di un cluster HDFS. Esegue uno o più pod Kubernetes con ogni pod che ospita i contenitori seguenti:
- Un contenitore Hadoop collegato a un volume permanente (archiviazione). Tutti i contenitori di questo tipo nel loro insieme formano il cluster Hadoop. All'interno del contenitore Hadoop è disponibile un processo di gestione dei nodi YARN che può creare processi di lavoro Apache Spark su richiesta. Il nodo head Spark ospita il metastore hive, la cronologia di Spark e i contenitori di cronologia dei processi YARN.
- Un'istanza di SQL Server per leggere i dati da HDFS usando la tecnologia OpenRowSet.
collectdper la raccolta dei dati di metrica.fluentbitper la raccolta dei dati di log.
Responsabilità
I nodi di archiviazione sono responsabili delle attività seguenti:
- Inserimento di dati tramite Apache Spark.
- Archiviazione dei dati in HDFS (formato parquet e testo delimitato). HDFS fornisce anche la persistenza dei dati, tenendo conto che i dati HDFS vengono distribuiti tra tutti i nodi di archiviazione del cluster Big Data di SQL Server.
- Accesso ai dati tramite gateway HDFS ed endpoint SQL Server.
Accesso ai dati
I metodi principali per accedere ai dati nel pool di archiviazione sono:
- Processi Spark.
- Utilizzo di tabelle esterne di SQL Server per consentire l'esecuzione di query sui dati tramite i nodi di calcolo PolyBase e le istanze di SQL Server in esecuzione sui nodi HDFS.
È anche possibile interagire con HDFS usando:
- Azure Data Studio.
- Azure Data CLI (
azdata). - kubectl per eseguire comandi nel contenitore Hadoop.
- Gateway HTTP HDFS.
Passaggi successivi
Per altre informazioni sui cluster Big Data di SQL Server, vedere le risorse seguenti: