Introduzione al pool di dati nei cluster Big Data di SQL Server
Si applica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
Questo articolo descrive il ruolo dei pool di dati di SQL Server in un cluster Big Data di SQL Server. Le sezioni seguenti descrivono l'architettura, le funzionalità e gli scenari di utilizzo di un pool di dati.
Questo video di 5 minuti introduce i pool di dati e mostra come eseguire query sui dati dai pool di dati:
Architettura dei pool di dati
Un pool di dati è costituito da una o più istanze di pool di dati di SQL Server che forniscono risorse di archiviazione permanenti di SQL Server per il cluster. Consente di eseguire query sulle prestazioni dei dati memorizzati nella cache su origini dati esterne e l'offload del lavoro. I dati vengono inseriti nel pool di dati usando query T-SQL o processi Spark. Per migliorare le prestazioni tra set di dati di grandi dimensioni, i dati inseriti vengono distribuiti in partizioni e archiviati in tutte le istanze di SQL Server nel pool. I metodi di distribuzione supportati sono round robin e con replica. Per l'ottimizzazione dell'accesso in lettura, viene creato un indice columnstore cluster in ogni tabella in ogni istanza del pool di dati. Un pool di dati funge da data mart con scalabilità orizzontale per i cluster Big Data di SQL Server.
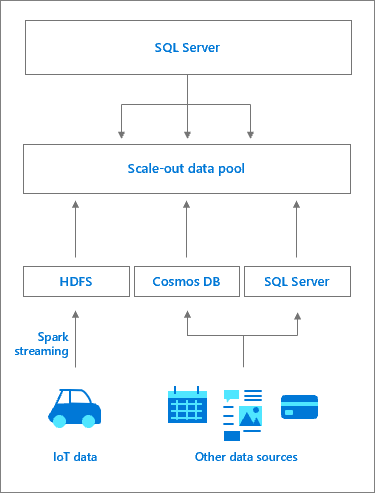
L'accesso alle istanze di SQL Server nel pool di dati viene gestito dall'istanza master di SQL Server. Viene creata un'origine dati esterna per il pool di dati, insieme alle tabelle esterne di PolyBase per archiviare la cache di dati. In background, il controller crea un database nel pool di dati con tabelle corrispondenti alle tabelle esterne. Dall'istanza master di SQL Server il flusso di lavoro è trasparente. Il controller reindirizza le richieste specifiche di tabelle esterne alle istanze di SQL Server nel pool di dati, eventualmente tramite il pool di calcolo, esegue le query e restituisce il set di risultati. I dati nel pool di dati possono essere solo inseriti o sottoposti a query e non possono essere modificati. Eventuali aggiornamenti dei dati richiedono pertanto l'eliminazione della tabella, seguita dalla ricreazione della tabella e dal successivo ripopolamento dei dati.
Scenari di pool di dati
La creazione di report è uno scenario comune per i pool di dati. Ad esempio, per una query complessa per il join di più origini dati di PolyBase, usata per un report settimanale, potrebbe essere eseguito l'offload al pool di dati. I dati memorizzati nella cache supportano il calcolo rapido in locale ed evitano di dover tornare ai set di dati originali. Analogamente, i dati di dashboard che richiedono un aggiornamento periodico possono essere memorizzati nella cache nel pool di dati per ottimizzare la creazione di report. Anche l'esplorazione ripetuta di Machine Learning può trarre vantaggio dalla memorizzazione nella cache dei set di dati nel pool di dati.
Passaggi successivi
Per altre informazioni sui cluster Big Data di SQL Server, vedere le risorse seguenti: